install.packages("concurve")
library("concurve")Tables, Graphs, and Computations from Rafi & Greenland (2020)
This post goes through the R code and logic that was used to construct the figures and concepts in Rafi & Greenland (2020) BMC MRM.
Keywords
p-value, p-value function, confidence curve, confidence distribution

The following post provides some of the code that was used to construct the figures and tables from Rafi & Greenland, 20201. An enhanced PDF version of the paper can be found here. For further discussion of the computations, see the appendix of the main paper, along with our technical supplement.2
Disclaimer: I am responsible for all the code and mistakes below, and none of them can be attributed to my coauthors or my fellow package developers.
In order to recreate the functions, I would recommend installing the latest version of concurve from CRAN, as it has patched some issues with graphing when the outcome is binary. Use the script below to get the latest version and load the R package. A number of other R packages are also used in this post, which are listed below.
Valid P-values Are Uniform Under the Null Model
Here we show that valid P-values have specific properties, when the null model is true. We first generate two variables (Y, X) that come from the same normal distribution with a \mu of 0 and \sigma of 1, each with a total of 1000 observations. We assume that there is no relationship between these two variables. We run a simple t-test between Y and X and iterate this 100000 times and compute 100000 P-values to see the overall distribution of the P-values, which we then plot using a histogram./
RNGkind(kind = "L'Ecuyer-CMRG")
set.seed <- 1031
n.sim <- 100
t.sim <- numeric(n.sim)
n.samp <- 1000
for (i in 1:n.sim) {
X <- rnorm(n.samp, mean = 0, sd = 1)
Y <- rnorm(n.samp, mean = 0, sd = 1)
df <- data.frame(X, Y)
t <- t.test(X, Y, data = df)
t.sim[i] <- t[[3]]
}
ggplot(NULL, aes(x = t.sim)) + geom_histogram(bins = 30, col = "black",
fill = "#99c7c7", alpha = 0.25) + labs(title = "Distribution of P-values Under the Null",
x = "P-value") + scale_x_continuous(breaks = seq(0, 1, 0.1)) +
theme_bw()
This can also be shown using the TeachingDemos R package, which has a function dedicated to showing this phenomenon.
library("TeachingDemos")
RNGkind(kind = "L'Ecuyer-CMRG")
set.seed <- 1031
obs_p <- Pvalue.norm.sim(n = 1000, mu = 0, mu0 = 0, sigma = 1,
sigma0 = 1, test = "t", alternative = "two.sided", alpha = 0.05,
B = 1e+05)
ggplot(NULL, aes(x = obs_p)) + geom_histogram(bins = 30, col = "black",
fill = "#99c7c7", alpha = 0.25) + labs(title = "Distribution of P-values Under the Null",
x = "P-value") + scale_x_continuous(breaks = seq(0, 1, 0.1)) +
theme_bw()
As you can see, when the null model is true, the distribution of P-values is uniform. Valid P-values are uniform under the null hypothesis and their corresponding S-values are exponentially distributed. We run the same simulation as before, but then convert the obtained P-values into S-values, to see how they are distributed.
RNGkind(kind = "L'Ecuyer-CMRG")
set.seed <- 1031
n.sim <- 100
t.sim <- numeric(n.sim)
n.samp <- 1000
for (i in 1:n.sim) {
X <- rnorm(n.samp, mean = 0, sd = 1)
Y <- rnorm(n.samp, mean = 0, sd = 1)
df <- data.frame(X, Y)
t <- t.test(X, Y, data = df)
t.sim[i] <- t[[3]]
}
ggplot(NULL, aes(x = -log2(t.sim))) + geom_histogram(bins = 30,
col = "black", fill = "#d46c5b", alpha = 0.5) + labs(title = "Distribution of S-values Under the Null",
x = "S-value (Bits of Information)") + theme_bw()
Posterior Predictive P-values
Despite the name, posterior predictive P-values are not considered valid frequentist P-values because they do not meet the uniformity criterion, instead they are pulled towards the parameter value 0.5. For further discussion, see our technical supplement along with Greenland (2019) for comprehensive theoretical discussions.2, 3
A quick excerpt from our main paper and the technical supplement explains why this is not the case,
As discussed in the Supplement, in Bayesian settings one may see certain P-values that are not valid frequentist P-values, the primary example being the posterior predictive P-value4;5; unfortunately, the negative logs of such invalid P-values do not measure surprisal at the statistic given the model, and so are not valid S-values.
The decision rule “reject H if p\leq \alpha” will reject H 100\alpha% of the time under sampling from a model M obeying H (i.e., the Type-1 error rate of the test will be \alpha) provided the random variable P corresponding to p is valid (uniform under the model M used to compute it), but not necessarily otherwise6. This is one reason why frequentist writers reject invalid P-values (such as posterior predictive P-values, which highly concentrate around 0.50) and devote considerable technical coverage to uniform P-values6;5;4. A valid P-value (“U-value”) translates into an exponentially distributed S-value with a mean of 1 nat or \log_{2}(e)=1.443 bits where e is the base of the natural logs.
Uniformity is also central to the “refutational information” interpretation of the S-value used here, for it is necessary to ensure that the P-value p from which s is derived is in fact the percentile of the observed value of the test statistic in the distribution of the statistic under M, thus making small p surprising under M and making s the corresponding degree of surprise. Because posterior predictive P-values do not translate into sampling percentiles of the statistic under the hypothesis (in fact, they are pulled toward 0.5 from the correct percentiles)5;4, the resulting negative log does not measure surprisal at the statistic given M, and so is not a valid S-value in our terms.
And indeed, we can show this phenomenon below with simulations. Here we fit a simple Bayesian regression model with a weakly informative prior normal(0, 10) using rstanarm, where both the predictor and response variable come from the same distribution and have the same location and scale parameters (\mu = 0, \sigma = 1. We then calculate the observed test statistics, along with their distributions, and convert them into posterior predictive P-values and plot them using Bayesplot functions. Then, we iterate this 1000 times to examine the distribution of posterior predictive P-values and compare them to standard P-values that are known to be uniform.
But first, we’ll generate the distribution of the test statistic from one model.
library("bayesplot")
library("rstan")
library("rstanarm")
rstan_options(auto_write = TRUE)
options(mc.cores = 4)
teal <- c("#99c7c7")
color_scheme_set("teal")
RNGkind(kind = "L'Ecuyer-CMRG")
n.samp <- 100
X <- rnorm(n.samp, mean = 0, sd = 1)
Y <- rnorm(n.samp, mean = 0, sd = 1)
df <- data.frame(X, Y)
mod1 <- stan_glm(Y ~ X, data = df, chains = 1, cores = 4, refresh = 0,
prior = normal(0, 10))
#> Error in if (!prior_dist_name %in% unlist(ok_dists)) {: argument is of length zero
yrep <- posterior_predict(mod1)
#> Error: object 'mod1' not found
h <- ppc_stat(Y, yrep, stat = "median", freq = TRUE, binwidth = 0.01) +
labs(title = "Distribution of Posterior Test Statistic") +
theme_bw() + yaxis_text(on = TRUE)
#> Error: object 'yrep' not found
values_all <- h[["plot_env"]][["T_yrep"]]
#> Error: object 'h' not found
prob_to_find <- h[["plot_env"]][["T_y"]]
#> Error: object 'h' not found
quantInv <- function(distr, value) ecdf(distr)(value)
posterior_p_value <- quantInv(values_all, prob_to_find)
#> Error: object 'values_all' not found
l <- ppc_stat_2d(Y, yrep) + theme_bw() + labs(title = "Distribution of Posterior Test Statistic")
#> Error: object 'yrep' not found
plot(h)
#> Error in h(simpleError(msg, call)): error in evaluating the argument 'x' in selecting a method for function 'plot': object 'h' not found
plot(l)
#> Error in h(simpleError(msg, call)): error in evaluating the argument 'x' in selecting a method for function 'plot': object 'l' not foundprint(prob_to_find)
#> Error in h(simpleError(msg, call)): error in evaluating the argument 'x' in selecting a method for function 'print': object 'prob_to_find' not foundThe above is the posterior predictive test statistic for one model, along with it’s distribution. Now let’s iterate this process, convert them into posterior predictive P-values, and generate their distribution.
rstan_options(auto_write = TRUE)
options(mc.cores = 4)
RNGkind(kind = "L'Ecuyer-CMRG")
set.seed <- 1031
n.sim <- 100
ppp <- numeric(n.sim)
n.samp <- 1000
quantInv <- function(distr, value) ecdf(distr)(value)
for (i in 1:length(ppp)) {
X <- rnorm(n.samp, mean = 0, sd = 1)
Y <- rnorm(n.samp, mean = 0, sd = 1)
df <- data.frame(X, Y)
mod1 <- stan_glm(Y ~ X, data = df, chains = 1, cores = 4,
iter = 1000, refresh = 0, prior = normal(0, 10))
yrep <- posterior_predict(mod1)
h <- ppc_stat(Y, yrep, stat = "median")
values_all <- h[["plot_env"]][["T_yrep"]]
prob_to_find <- h[["plot_env"]][["T_y"]]
posterior_p_value <- quantInv(values_all, prob_to_find)
ppp[i] <- posterior_p_value
}
#> Error in if (!prior_dist_name %in% unlist(ok_dists)) {: argument is of length zero
ggplot(NULL, aes(x = ppp)) + geom_histogram(bins = 30, col = "black",
fill = "#99c7c7", alpha = 0.25) + labs(title = "Distribution of Posterior Predictive P-values",
subtitle = "From Simulation of 1000 Simple Linear Regressions",
x = "Posterior Predictive P-value") + scale_x_continuous(breaks = seq(0,
1, 0.1)) + theme_bw()
We can also show this in Stata 16.1, using their new bayesstats ppvalues command which generates posterior predictive P-values.
version 16.1
set obs 100
/**
Generate variables from a normal distribution like before
*/
generate x = rnormal(0, 1)
generate y = rnormal(0, 1)
/**
We set up our model here
*/
parallel initialize 8, f
bayesmh y x, likelihood(normal({var})) prior({var}, normal(0, 10)) ///
prior({y:}, normal(0, 10)) rseed(1031) saving(coutput_pred, replace) mcmcsize(1000)
/**
We use the bayespredict command to make predictions from the model
*/
bayespredict (mean:@mean({_resid})) (var:@variance({_resid})), ///
rseed(1031) saving(coutput_pred, replace)
/**
Then we calculate the posterior predictive P-values
*/
bayesstats ppvalues {mean} using coutput_pred
#> . version 16.1
#>
#> . set obs 100
#> Number of observations (_N) was 0, now 100.
#>
#> . /**
#> > Generate variables from a normal distribution like before
#> > */
#> . generate x = rnormal(0, 1)
#>
#> . generate y = rnormal(0, 1)
#>
#> . /**
#> > We set up our model here
#> >
#> > */
#> . parallel initialize 8, f
#> N Child processes: 8
#> Stata dir: /Applications/Stata/StataBE.app/Contents/MacOS/stata-be
#>
#> . bayesmh y x, likelihood(normal({var})) prior({var}, normal(0, 10)) ///
#> > prior({y:}, normal(0, 10)) rseed(1031) saving(coutput_pred, replace) mcmcsize(1000)
#>
#> Burn-in ...
#> Simulation ...
#>
#> Model summary
#> ------------------------------------------------------------------------------
#> Likelihood:
#> y ~ normal(xb_y,{var})
#>
#> Priors:
#> {y:x _cons} ~ normal(0,10) (1)
#> {var} ~ normal(0,10)
#> ------------------------------------------------------------------------------
#> (1) Parameters are elements of the linear form xb_y.
#>
#> Bayesian normal regression MCMC iterations = 3,500
#> Random-walk Metropolis–Hastings sampling Burn-in = 2,500
#> MCMC sample size = 1,000
#> Number of obs = 100
#> Acceptance rate = .2068
#> Efficiency: min = .03878
#> avg = .07757
#> Log marginal-likelihood = -149.68351 max = .1317
#>
#> ------------------------------------------------------------------------------
#> | Equal-tailed
#> | Mean Std. dev. MCSE Median [95% cred. interval]
#> -------------+----------------------------------------------------------------
#> y |
#> x | -.0758396 .097915 .008532 -.0704775 -.2600037 .1054718
#> _cons | .0238076 .1107038 .014035 .0326669 -.1793756 .2293247
#> -------------+----------------------------------------------------------------
#> var | .9773565 .1313659 .021096 .9384637 .7882847 1.323255
#> ------------------------------------------------------------------------------
#>
#> file coutput_pred.dta saved.
#>
#> . /**
#> > We use the bayespredict command to make predictions from the model
#> > */
#> . bayespredict (mean:@mean({_resid})) (var:@variance({_resid})), ///
#> > rseed(1031) saving(coutput_pred, replace)
#>
#> Computing predictions ...
#>
#> file coutput_pred.dta saved.
#> file coutput_pred.ster saved.
#>
#> . /**
#> > Then we calculate the posterior predictive P-values
#> > */
#> . bayesstats ppvalues {mean} using coutput_pred
#>
#> Posterior predictive summary MCMC sample size = 1,000
#>
#> -----------------------------------------------------------
#> T | Mean Std. dev. E(T_obs) P(T>=T_obs)
#> -------------+---------------------------------------------
#> mean | .0004223 .0957513 .008651 .495
#> -----------------------------------------------------------
#> Note: P(T>=T_obs) close to 0 or 1 indicates lack of fit.
#>
#> .As we can see from the R plot above, the test statistics are are generally concentrated around 0.5 and the distribution (as shown above via the R code) hardly resembles the uniform distribution of P-value under the null model. Further, the base-2 log transformation of posterior predictive P-values is not exponentially distributed, making them invalid S-values in our terms.
ggplot(NULL, aes(x = (-log2(ppp)))) + geom_histogram(bins = 30,
col = "black", fill = "#d46c5b", alpha = 0.25) + labs(title = "Distribution of -log2(Posterior Predictive P-values)",
subtitle = "S-values Produced From Posterior Predictive P-values",
x = "-log2(Posterior Predictive P-value)") + theme_bw()
#> Error in `geom_histogram()`:
#> ! Problem while computing stat.
#> ℹ Error occurred in the 1st layer.
#> Caused by error in `seq_len()`:
#> ! argument must be coercible to non-negative integerTable 1: Some P-values, S-values, Maximum Likelihood Ratios, and Likelihood Ratio Statistics
Here, we look at some common P-values, and how they correspond to other information statistics and likelihood measures.
pvalue <- c(0.99, 0.9, 0.5, 0.25, 0.1, 0.05, 0.025, 0.01, 0.005,
1e-04, paste("5 sigma (~ 2.9 in 10 million)"), paste("1 in 100 million (GWAS)"),
paste("6 sigma (~ 1 in a billion)"))
svalue <- round(c(-log2(c(0.99, 0.9, 0.5, 0.25, 0.1, 0.05, 0.025,
0.01, 0.005, 1e-04)), 21.7, 26.6, 29.9), 2)
pvalue[1:10] <- formatC(pvalue[1:10], format = "e", digits = 2)
mlr <- round(c(1, 1.01, 1.26, 1.94, 3.87, 6.83, 12.3, 27.6, 51.4,
1935, (5.2 * (10^5)), (1.4 * (10^7)), (1.3 * (10^8))), 2)
# likelihood ratio statistic
lr <- round(c(0.00016, 0.016, 0.45, 1.32, 2.71, 3.84, 5.02, 6.63,
7.88, 15.1, 26.3, 32.8, 37.4), 2)
table1 <- data.frame(pvalue, svalue, mlr, lr)
colnames(table1) <- c("P-value (compatibility)", "S-value (bits)",
"Maximum Likelihood Ratio", "Deviance Statistic 2ln(MLR)")
kbl(table1, format = "html", padding = 45, longtable = TRUE,
color = "#777") %>%
row_spec(row = 0, color = "#777", bold = T) %>%
column_spec(column = 1:4, color = "#777", bold = F) %>%
kable_classic(full_width = TRUE, html_font = "Cambria", lightable_options = "basic",
font_size = 17, fixed_thead = list(enabled = F)) %>%
footnote(general_title = "Abbreviations: ", title_format = "underline",
general = c("Table 1 $P$-values and binary $S$-values, with corresponding maximum-likelihood ratios (MLR) and deviance (likelihood-ratio) statistics for a simple test hypothesis H under background assumptions A"))| P-value (compatibility) | S-value (bits) | Maximum Likelihood Ratio | Deviance Statistic 2ln(MLR) |
|---|---|---|---|
| 0.99 | 0.01 | 1.000e+00 | 0.00 |
| 0.9 | 0.15 | 1.010e+00 | 0.02 |
| 0.5 | 1.00 | 1.260e+00 | 0.45 |
| 0.25 | 2.00 | 1.940e+00 | 1.32 |
| 0.1 | 3.32 | 3.870e+00 | 2.71 |
| 0.05 | 4.32 | 6.830e+00 | 3.84 |
| 0.025 | 5.32 | 1.230e+01 | 5.02 |
| 0.01 | 6.64 | 2.760e+01 | 6.63 |
| 0.005 | 7.64 | 5.140e+01 | 7.88 |
| 1e-04 | 13.29 | 1.935e+03 | 15.10 |
| 5 sigma (~ 2.9 in 10 million) | 21.70 | 5.200e+05 | 26.30 |
| 1 in 100 million (GWAS) | 26.60 | 1.400e+07 | 32.80 |
| 6 sigma (~ 1 in a billion) | 29.90 | 1.300e+08 | 37.40 |
| Abbreviations: | |||
| Table 1 $P$-values and binary $S$-values, with corresponding maximum-likelihood ratios (MLR) and deviance (likelihood-ratio) statistics for a simple test hypothesis H under background assumptions A |
For further discussion of 5 and 6 sigma cutoffs, see7.
Frequentist Interval Estimate Percentiles
Refer to Long-Run Coverage
Here we simulate a study where one group with 100 participants has an \mu of 100 with a \sigma of 20 and the second group has the same number of participants but an average of 80 and a standard deviation of 20. We compare them using a Welch’s t-test and generate 95% compatibility intervals several times, specifically 100 times, and then plot them. Since we know the mean difference is 20, we wish to see how often the interval estimates cover this true parameter value.

This shows that the intervals tend to vary simply as a result of randomness, and that the proper interpretation of the attached percentile is about long run coverage of the true parameter. However, this does not preclude interpretation of a single interval estimate from a study.8 As we write in the Replace unrealistic “confidence” claims with compatibility measures section of our paper.1
The fact that “confidence” refers to the procedure behavior, not the reported interval, seems to be lost on most researchers. Remarking on this subtlety, when Jerzy Neyman discussed his confidence concept in 1934 at a meeting of the Royal Statistical Society, Arthur Bowley replied, “I am not at all sure that the ‘confidence’ is not a confidence trick.”9. And indeed, 40 years later, Cox and Hinkley warned, “interval estimates cannot be taken as probability statements about parameters, and foremost is the interpretation ‘such and such parameter values are consistent with the data.’”8. Unfortunately, the word “consistency” is used for several other concepts in statistics, while in logic it refers to an absolute condition (of noncontradiction); thus, its use in place of “confidence” would risk further confusion.
To address the problems above, we exploit the fact that a 95% CI summarizes the results of varying the test hypothesis H over a range of parameter values, displaying all values for which p > 0.0510 and hence s < 4.32 bits3;11. Thus the CI contains a range of parameter values that are more compatible with the data than are values outside the interval, under the background assumptions3;12. Unconditionally (and thus even if the background assumptions are uncertain), the interval shows the values of the parameter which, when combined with the background assumptions, produce a test model that is “highly compatible” with the data in the sense of having less than 4.32 bits of information against it. We thus refer to CI as compatibility intervals rather than confidence intervals13;3;11; their abbreviation remains “CI.” We reject calling these intervals “uncertainty intervals,” because they do not capture uncertainty about background assumptions13.
Indeed, this also has to do with our paper on deemphasizing the model assumptions that are often behind common statistical outputs, and why it is necessary to treat them as uncertain, rather than given.14 For example, a 95% interval estimate is assumed to be free of bias in its construction, however, it’s coverage claims are no longer so, once there are systematic errors in play. Many of these common, classical statistical procedures are designed to deal with random variation, and less so with bias (a relatively new field, with shiny new methods).
Brown et al. (2017) Reanalysis
Taken from the Brown et al. data.15, 16
Here we take the reported statistics from the Brown et al. studies in order to run statistical tests of different alternative test hypotheses and use those results to construct various functions.
We calculate the standard errors from the point estimate and the confidence (compatibility) limits.
se <- log(2.59/0.997)/3.92
logUL <- log(2.59)
logLL <- log(0.997)
logpoint <- log(1.61)
logpoint + (1.96 * se)
#> [1] 0.9535654
logpoint - (1.96 * se)
#> [1] -0.001097013Table 2: P-values, S-values, and Likelihoods for Targeted Hypotheses About Hazard Ratios for Brown et al.
testhypothesis <- c("Halving of hazard", "No effect (null)",
"Point estimate", "Doubling of hazard", "Tripling of hazard",
"Quintupling of hazard")
hazardratios <- c(0.5, 1, 1.61, 2, 3, 5)
pvals <- c(1.6e-06, 0.05, 1, 0.37, 0.01, 3.2e-06)
svals <- round(-log2(pvals), 2)
mlr2 <- c((1 * 10^5), 6.77, 1, 1.49, 26.2, (5 * 10^4))
lr <- round(c(exp((((log(0.5/1.61))/se)^2)/(2)), exp((((log(1/1.61))/se)^2)/(2)),
exp((((log(1.61/1.61))/se)^2)/(2)), exp((((log(2/1.61))/se)^2)/(2)),
exp((((log(3/1.61))/se)^2)/(2)), exp((((log(5/1.61))/se)^2)/(2))),
3)
LR <- formatC(lr, format = "e", digits = 2)
table2 <- data.frame(testhypothesis, hazardratios, pvals, svals,
mlr2, LR)
colnames(table2) <- c("Test Hypothesis", "HR", "P-values", "S-values",
"MLR", "LR")
kbl(table2, format = "html", padding = 45, longtable = TRUE,
color = "#777") %>%
row_spec(row = 0, color = "#777", bold = T) %>%
column_spec(column = 1:6, color = "#777", bold = F) %>%
kable_classic(full_width = TRUE, html_font = "Cambria", lightable_options = "basic",
font_size = 15, fixed_thead = list(enabled = F))| Test Hypothesis | HR | P-values | S-values | MLR | LR |
|---|---|---|---|---|---|
| Halving of hazard | 0.50 | 1.6e-06 | 19.25 | 1.00e+05 | 1.02e+05 |
| No effect (null) | 1.00 | 5.0e-02 | 4.32 | 6.77e+00 | 6.77e+00 |
| Point estimate | 1.61 | 1.0e+00 | 0.00 | 1.00e+00 | 1.00e+00 |
| Doubling of hazard | 2.00 | 3.7e-01 | 1.43 | 1.49e+00 | 1.49e+00 |
| Tripling of hazard | 3.00 | 1.0e-02 | 6.64 | 2.62e+01 | 2.62e+01 |
| Quintupling of hazard | 5.00 | 3.2e-06 | 18.25 | 5.00e+04 | 5.03e+04 |
Plot the point estimate and 95% compatibility interval
label <- c("Brown et al. (2017)\n JAMA", "Brown et al. (2017)\n J Clin Psychiatry")
point <- c(1.61, 1.7)
lower <- c(0.997, 1.1)
upper <- c(2.59, 2.6)
df <- data.frame(label, point, lower, upper)Here we plot the 95% compatibility interval estimate reported from the high-dimensional propensity score analysis.
ggplot(data = df, mapping = aes(x = label, y = point, ymin = lower,
ymax = upper, group = label)) + geom_pointrange(color = "#007C7C",
size = 1.5, alpha = 0.4) + geom_hline(yintercept = 1, lty = 3,
color = "#d46c5b", alpha = 0.5) + coord_flip() + scale_y_log10(breaks = scales::pretty_breaks(n = 10),
limits = c(0.8, 4)) + labs(title = "Association Between Serotonergic Antidepressant Exposure
\nDuring Pregnancy and Child Autism Spectrum Disorder",
subtitle = "Reported 95% Compatibility Intervals From Primary Results",
x = "Study", y = "Hazard Ratio (JAMA) +
Adjusted Pooled Odds Ratio (J Clin Psychiatry)") +
annotate(geom = "text", x = 1.5, y = 1, size = 5, label = "Null parameter value of 1",
color = "#d46c5b", alpha = 0.75) + annotate(geom = "text",
x = 2.2, y = 1.8, size = 5, label = "Point Estimate = 1.61,
Lower Limit = 0.997, Upper Limit = 2.59",
color = "#000000", alpha = 0.75) + annotate(geom = "text",
x = 1.2, y = 1.8, size = 5, label = "Point Estimate = 1.7,
Lower Limit = 1.1, Upper Limit = 2.6",
color = "#000000", alpha = 0.75) + theme_light() + theme(axis.text.y = element_text(angle = 90,
hjust = 1, size = 13)) + theme(axis.text.x = element_text(size = 13)) +
theme(title = element_text(size = 13))
Once again, the authors reported that15
In the 2837 pregnancies (7.9%) exposed to antidepressants, 2.0% (95% CI, 1.6%-2.6%) of children were diagnosed with autism spectrum disorder. Risk of autism spectrum disorder was significantly higher with serotonergic antidepressant exposure (4.51 exposed vs 2.03 unexposed per 1000 person-years; between-group difference, 2.48 95% CI, 2.33-2.62 per 1000 person-years) in crude (HR, 2.16 95% CI, 1.64-2.86) and multivariable-adjusted analyses (HR, 1.59 95% CI, 1.17-2.17) (Table 2). After inverse probability of treatment weighting based on the HDPS, the association was not significant (HR, 1.61 95% CI, 0.997-2.59) (Table 2).
and concluded with
In children born to mothers receiving public drug coverage in Ontario, Canada, in utero serotonergic antidepressant exposure compared with no exposure was not associated with autism spectrum disorder in the child. Although a causal relationship cannot be ruled out, the previously observed association may be explained by other factors.
We will show using the graphical and tabular summaries below, why a more nuanced summary such as,
“After HDPS adjustment for confounding, a 61% hazard elevation remained; however, under the same model, every hypothesis from no elevation up to a 160% hazard increase had p > 0.05; Thus, while quite imprecise, these results are consistent with previous observations of a positive association between serotonergic antidepressant prescriptions and subsequent ASD. Because the association may be partially or wholly due to uncontrolled biases, further evidence will be needed for evaluating what, if any, proportion of it can be attributed to causal effects of prenatal serotonergic antidepressant use on ASD incidence.”
would have been far more appropriate, as we discuss in our paper.1
P-value and S-value Functions
In order to use this information to construct a P-value function, we can use the concurve functions.
library("concurve")We enter the reported point estimates and compatibility limits and produce all possible intervals + P-values + S-values. This is calculated assuming normal approximations with the curve_rev() function.
curve1 <- curve_rev(point = 1.61, LL = 0.997, UL = 2.59, measure = "ratio")It is stored in the object curve1.
We can generate a table of the relevant statistics from this reanalysis, similar to the table from above, but this time using the concurve function, curve_table(), but this time it will give us interval estimates of various percentiles (25%, 50%, 75%, 95%, etc.). These are in turn used to construct the entire confidence (compatibility) distribution or P-value function.
kbl(curve_table(curve1[[1]]), format = "html", padding = 45,
longtable = TRUE, color = "#777", row.names = F, col.names = colnames(curve_table(curve1[[1]]))) %>%
row_spec(row = 0, color = "#777", bold = T) %>%
column_spec(column = 1:7, color = "#777", bold = F) %>%
kable_classic(full_width = TRUE, html_font = "Cambria", lightable_options = "basic",
font_size = 17, fixed_thead = list(enabled = F)) %>%
footnote(general_title = c("Table of Statistics for Various Interval Estimate Percentiles"),
general = " ")| Lower Limit | Upper Limit | Interval Width | Interval Level (%) | CDF | P-value | S-value (bits) |
|---|---|---|---|---|---|---|
| 1.490 | 1.740 | 0.250 | 25.0 | 0.625 | 0.750 | 0.415 |
| 1.366 | 1.897 | 0.531 | 50.0 | 0.750 | 0.500 | 1.000 |
| 1.217 | 2.131 | 0.914 | 75.0 | 0.875 | 0.250 | 2.000 |
| 1.178 | 2.200 | 1.021 | 80.0 | 0.900 | 0.200 | 2.322 |
| 1.134 | 2.286 | 1.152 | 85.0 | 0.925 | 0.150 | 2.737 |
| 1.079 | 2.403 | 1.325 | 90.0 | 0.950 | 0.100 | 3.322 |
| 0.999 | 2.595 | 1.596 | 95.0 | 0.975 | 0.050 | 4.322 |
| 0.933 | 2.779 | 1.846 | 97.5 | 0.988 | 0.025 | 5.322 |
| 0.860 | 3.015 | 2.155 | 99.0 | 0.995 | 0.010 | 6.644 |
| Table of Statistics for Various Interval Estimate Percentiles | ||||||
Figure 3: P-value (Compatibility) Function
Plot the P-value (Compatibility) function of the Brown et al. data
Now we plot the P-value function from the data stored in curve1 using the ggcurve() function from concurve.
ggcurve(curve1[[1]], type = "c", measure = "ratio", nullvalue = c(1),
levels = c(0.5, 0.75, 0.95)) + labs(title = expression(paste(italic(P),
"-value (Compatibility) Function")), subtitle = expression(paste(italic(P),
"-values for a range of hazard ratios (HR)")), x = "Hazard Ratio (HR)",
y = expression(paste(italic(P), "-value"))) + geom_vline(xintercept = 1.61,
lty = 1, color = "gray", alpha = 0.2) + geom_vline(xintercept = 2.59,
lty = 1, color = "gray", alpha = 0.2) + theme(plot.title = element_text(size = 12),
plot.subtitle = element_text(size = 11), axis.title.x = element_text(size = 12),
axis.title.y = element_text(size = 12), text = element_text(size = 11))
It is practically the same as the published version from Rafi & Greenland, 20201.
curve1 <- curve_rev(point = 1.61, LL = 0.997, UL = 2.59, measure = "ratio")
curve2 <- curve_rev(point = 1.7, LL = 1.1, UL = 2.6, measure = "ratio")Cumulative Confidence (Compatibility Distribution)
Although we do not cover this figure in our paper, it is easy to construct using concurve's ggcurve() function by specifying type as “cdf” to see the median estimate within the confidence distribution. The horizontal line that meets at the curve, is approximately the same as the maximum at the P-value function/confidence (compatibility) curve.
ggcurve(curve1[[2]], type = "cdf", measure = "ratio", nullvalue = c(1)) +
labs(title = "P-values for a range of hazard ratios (HR)",
subtitle = "Association Between Serotonergic Antidepressant Exposure
\nDuring Pregnancy and Child Autism Spectrum Disorder",
x = "Hazard Ratio (HR)", y = "Cumulative Compatibility") +
theme(plot.title = element_text(size = 12), plot.subtitle = element_text(size = 11),
axis.title.x = element_text(size = 12), axis.title.y = element_text(size = 12),
text = element_text(size = 11))
We will also calculate the likelihoods so that we can generate the corresponding likelihood functions.
lik2 <- curve_rev(point = 1.7, LL = 1.1, UL = 2.6, type = "l",
measure = "ratio")
lik1 <- curve_rev(point = 1.61, LL = 0.997, UL = 2.59, type = "l",
measure = "ratio")We can also see how consistent these results are with previous studies conducted by the same research group, given the overlap of the functions, which can be compared using the plot_compare() function. Let’s compare the relative likelihood functions from both studies from this research group to see how consistent the results are.
plot_compare(data1 = lik1[[1]], data2 = lik2[[1]], type = "l1",
measure = "ratio", nullvalue = TRUE, title = "Brown et al. 2017. J Clin Psychiatry. vs.
\nBrown et al. 2017. JAMA.",
subtitle = "J Clin Psychiatry: OR = 1.7, 1/6.83 LI: LL = 1.1, UL = 2.6
\nJAMA: HR = 1.61, 1/6.83 LI: LL = 0.997, UL = 2.59",
xaxis = "Hazard Ratio / Odds Ratio") + theme(plot.title = element_text(size = 12),
plot.subtitle = element_text(size = 11), axis.title.x = element_text(size = 12),
axis.title.y = element_text(size = 12), text = element_text(size = 11))
and the P-value functions.
plot_compare(data1 = curve1[[1]], data2 = curve2[[1]], type = "c",
measure = "ratio", nullvalue = TRUE, title = "Brown et al. 2017. J Clin Psychiatry. vs.
\nBrown et al. 2017. JAMA.",
subtitle = "J Clin Psychiatry: OR = 1.7, 1/6.83 LI: LL = 1.1, UL = 2.6
\nJAMA: HR = 1.61, 1/6.83 LI: LL = 0.997, UL = 2.59",
xaxis = "Hazard Ratio / Odds Ratio") + theme(plot.title = element_text(size = 12),
plot.subtitle = element_text(size = 11), axis.title.x = element_text(size = 12),
axis.title.y = element_text(size = 12), text = element_text(size = 11))
Figure 4: S-value (Suprisal) Function
Plot the S-value (Surprisal) function of the Brown et al. data with ggcurve()
ggcurve(data = curve1[[1]], type = "s", measure = "ratio", nullvalue = c(1),
title = "S-value (Surprisal) Function", subtitle = "S-Values (surprisals) for a range of hazard ratios (HR)",
xaxis = "Hazard Ratio", yaxis1 = "S-value (bits of information)") +
theme(plot.title = element_text(size = 12), plot.subtitle = element_text(size = 11),
axis.title.x = element_text(size = 12), axis.title.y = element_text(size = 12),
text = element_text(size = 11))
which is quite close to the figure from our paper.
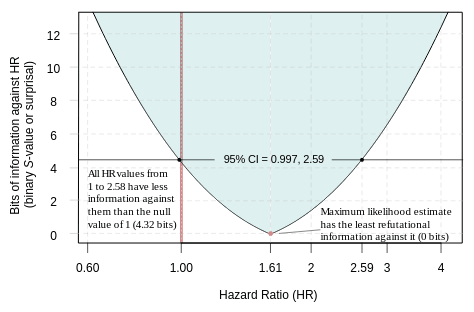
Likelihood (Support) Functions
Here we provide the code to show how we constructed the likelihood functions from our paper, which are the supplementary figures found here (S1) and here (S2).
Calculate and Plot Likelihood (Support) Intervals.
Here we use the reported estimates to construct the Z-scores and standard errors, which are in turn used to compute the likelihoods.
hrvalues <- seq(from = 0.65, to = 3.98, by = 0.01)
se <- log(2.59/0.997)/3.92
zscore <- sapply(hrvalues, function(i) (log(i/1.61)/se))Figure S1: Relative Likelihood Function
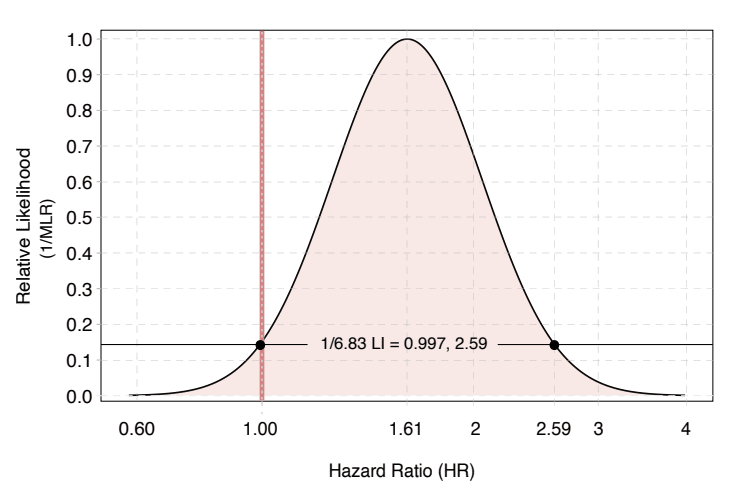
We then standardize all the likelihoods by their maximum at the likelihood function,17 to produce relative likelihoods, likelihood intervals, and their corresponding relative likelihood function.18
support <- exp((-zscore^2)/2)
likfunction <- data.frame(hrvalues, zscore, support)
ggplot(data = likfunction, mapping = aes(x = hrvalues, y = support)) +
geom_line() + geom_vline(xintercept = 1, lty = 3, color = "#d46c5b",
alpha = 0.75) + geom_hline(yintercept = (1/6.83), lty = 1,
color = "#333333", alpha = 0.05) + geom_ribbon(aes(x = hrvalues,
ymin = min(support), ymax = support), fill = "#d46c5b", alpha = 0.1) +
labs(title = "Relative Likelihood Function", subtitle = "Relative likelihoods for a range of hazard ratios",
x = "Hazard Ratio (HR)", y = "Relative Likelihood \n1/MLR") +
annotate(geom = "text", x = 1.65, y = 0.2, label = "1/6.83 LI = 0.997, 2.59",
size = 4, color = "#000000") + theme_bw() + theme(plot.title = element_text(size = 12),
plot.subtitle = element_text(size = 11), axis.title.x = element_text(size = 12),
axis.title.y = element_text(size = 12), text = element_text(size = 11)) +
scale_x_log10(breaks = scales::pretty_breaks(n = 10)) + scale_y_continuous(expand = expansion(mult = c(0.01,
0.0125)), breaks = seq(0, 1, 0.1))
The \frac{1}{6.83} likelihood interval corresponds to the 95% compatibility interval, as shown by the figure from our paper.
Below we use the calculated Z-scores to construct the log-likelihood function which is the upward-concave parabola \frac{Z^{2}}{2} = -ln(MLR)
support <- (zscore^2)/2
likfunction <- data.frame(hrvalues, zscore, support)
ggplot(data = likfunction, mapping = aes(x = hrvalues, y = support)) +
geom_line() + geom_vline(xintercept = 1, lty = 3, color = "#d46c5b",
alpha = 0.75) + geom_ribbon(aes(x = hrvalues, ymin = support,
ymax = max(support)), fill = "#d46c5b", alpha = 0.1) + labs(title = "Log-Likelihood Function",
subtitle = "Log-likelihoods for a range of hazard ratios",
x = "Hazard Ratio (HR)", y = "ln(MLR)") + theme_bw() + theme(axis.title.x = element_text(size = 13),
axis.title.y = element_text(size = 13)) + scale_x_log10(breaks = scales::pretty_breaks(n = 10)) +
scale_y_continuous(expand = expansion(mult = c(0.01, 0.0125)),
breaks = seq(0, 7, 1)) + theme(text = element_text(size = 15)) +
theme(plot.title = element_text(size = 12), plot.subtitle = element_text(size = 12))
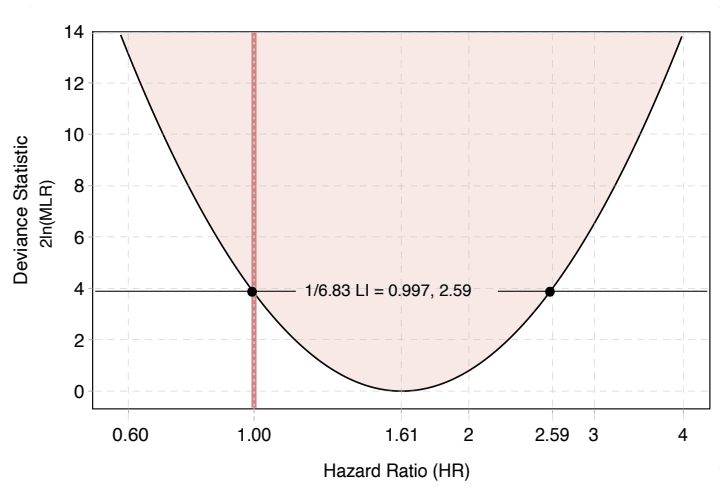
Figure S2: Deviance Function 2ln(MLR)
Known as the deviance function, it is twice the log-likelihood, which maps to the S-value function.
support <- (zscore^2)
likfunction <- data.frame(hrvalues, zscore, support)
ggplot(data = likfunction, mapping = aes(x = hrvalues, y = support)) +
geom_line() + geom_vline(xintercept = 1, lty = 3, color = "#d46c5b",
alpha = 0.75) + geom_hline(yintercept = 3.84, lty = 1, color = "#333333",
alpha = 0.05) + geom_ribbon(aes(x = hrvalues, ymin = support,
ymax = max(support)), fill = "#d46c5b", alpha = 0.1) + annotate(geom = "text",
x = 1.65, y = 4.4, label = "1/6.83 LI = 0.997, 2.59", size = 4,
color = "#000000") + theme_bw() + theme(plot.title = element_text(size = 12),
plot.subtitle = element_text(size = 11), axis.title.x = element_text(size = 12),
axis.title.y = element_text(size = 12), text = element_text(size = 11)) +
scale_x_log10(breaks = scales::pretty_breaks(n = 10)) + scale_y_continuous(expand = expansion(mult = c(0.01,
0.0125)), breaks = seq(0, 14, 2)) + labs(title = "Deviance Function",
subtitle = "Deviance statistics for a range of hazard ratios",
x = "Hazard Ratio (HR)", y = " Deviance Statistic \n2ln(MLR)")
And the version from our paper can be found here.
It is important to note that although we have calculated these likelihood functions manually here, they can also be generated easily using the curve_lik() function which takes inputs from the ProfileLikelihood R package. To see a further discussion, please see the following article, which gives several examples for a wide variety of models.
Further, we urge some caution. Although we endorse the construction and presentation of likelihood functions along with P-value and S-value functions, along with the tabulations, the use of pure likelihood methods has been highly controversial among some statisticians, with some going as far as to say that likelihood is blind although not all statisticians believe this, and have responded to such criticisms in kind, see discussants.19 Thus, we support providing both P-value/S-value and likelihood-based functions for a complete picture.
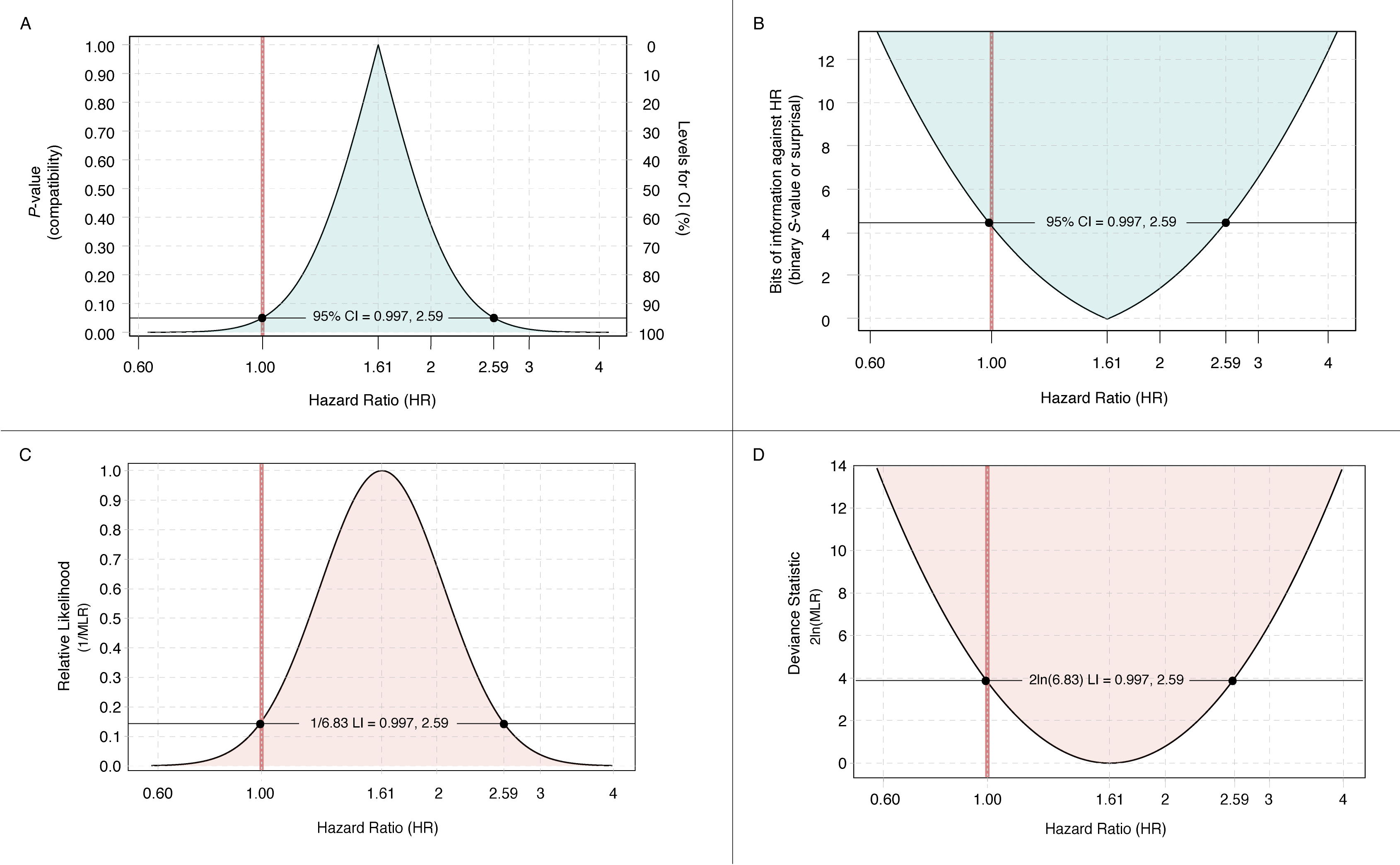
Indeed, we can see how they all easily map to one another when plotted side by side, with the following script.
library("cowplot")
plot_grid(confcurve, surprisalcurve, relsupportfunction, deviancefunction,
ncol = 2, nrow = 2)A clearer plot comparing the four functions is seen below (click on the image to view in full).
Additional adjustments that were made to the figures from Rafi & Greenland, 20201 were done using Adobe Illustrator and Photoshop.
All errors are ours, and we welcome critical feedback and reporting of errors. To report possible errors in our analyses, please post it as a comment below or as a bug here. We will compile them onto a public errata, if any errors or flaws are reported to us.
Statistical Package Citations
Please remember to cite the R packages if you use any of the R scripts from above. The citation for our1 can be found below in the References section or it can be downloaded here for a reference manager.
citation("concurve")
citation("TeachingDemos")
citation("ProfileLikelihood")
citation("rstan")
citation("rstanarm")
citation("bayesplot")
citation("knitr")
citation("kableExtra")
citation("ggplot2")
citation("cowplot")
citation("Statamarkdown")Environment
The analyses were run on:
si <- sessionInfo()
print(si, RNG = TRUE, locale = TRUE)
#> R version 4.5.0 (2025-04-11)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS Sequoia 15.6.1
#>
#> Matrix products: default
#> BLAS: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRblas.0.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.1
#>
#> Random number generation:
#> RNG: L'Ecuyer-CMRG
#> Normal: Inversion
#> Sample: Rejection
#>
#> locale:
#> [1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
#>
#> time zone: America/New_York
#> tzcode source: internal
#>
#> attached base packages:
#> [1] splines grid stats4 parallel stats graphics grDevices
#> [8] utils datasets methods base
#>
#> other attached packages:
#> [1] TeachingDemos_2.13 plotly_4.10.4 TSstudio_0.1.7
#> [4] tfautograph_0.3.2 tfdatasets_2.17.0 keras_2.15.0
#> [7] tensorflow_2.16.0 timetk_2.9.0 modeltime_1.3.1
#> [10] workflowsets_1.1.1 workflows_1.2.0 tune_1.3.0
#> [13] rsample_1.3.0 recipes_1.3.1 parsnip_1.3.2
#> [16] modeldata_1.4.0 infer_1.0.8 dials_1.4.0
#> [19] scales_1.4.0 tidymodels_1.3.0 xgboost_1.7.11.1
#> [22] prophet_1.0 rlang_1.1.6 astsa_2.2
#> [25] bayesforecast_1.0.5 smooth_4.2.0 greybox_2.0.4
#> [28] glmnet_4.1-9 forecast_8.24.0 fable_0.4.1
#> [31] fabletools_0.5.0 tsibbledata_0.4.1 tsibble_1.1.6
#> [34] rstanarm_2.32.1 texPreview_2.1.0 tinytex_0.57
#> [37] rmarkdown_2.29 brms_2.22.0 bootImpute_1.2.2
#> [40] knitr_1.50 boot_1.3-31 JuliaCall_0.17.6
#> [43] reshape2_1.4.4 ProfileLikelihood_1.3 ImputeRobust_1.3-1
#> [46] gamlss_5.4-22 gamlss.dist_6.1-1 gamlss.data_6.0-6
#> [49] mvtnorm_1.3-3 performance_0.14.0 summarytools_1.1.4
#> [52] tidybayes_3.0.7 htmltools_0.5.8.1 Statamarkdown_0.9.2
#> [55] car_3.1-3 carData_3.0-5 qqplotr_0.0.6
#> [58] ggcorrplot_0.1.4.1 mitml_0.4-5 pbmcapply_1.5.1
#> [61] Amelia_1.8.3 Rcpp_1.0.14 blogdown_1.21
#> [64] doParallel_1.0.17 iterators_1.0.14 foreach_1.5.2
#> [67] lattice_0.22-7 bayesplot_1.12.0 wesanderson_0.3.7
#> [70] VIM_6.2.2 colorspace_2.1-1 here_1.0.1
#> [73] progress_1.2.3 loo_2.8.0 mi_1.1
#> [76] Matrix_1.7-3 broom_1.0.8 yardstick_1.3.2
#> [79] svglite_2.2.1 Cairo_1.6-2 cowplot_1.1.3
#> [82] mgcv_1.9-3 nlme_3.1-168 xfun_0.52
#> [85] broom.mixed_0.2.9.6 reticulate_1.42.0 kableExtra_1.4.0
#> [88] posterior_1.6.1 checkmate_2.3.2 parallelly_1.45.0
#> [91] miceFast_0.8.5 randomForest_4.7-1.2 missForest_1.5
#> [94] miceadds_3.17-44 quantreg_6.1 SparseM_1.84-2
#> [97] MCMCpack_1.7-1 MASS_7.3-65 coda_0.19-4.1
#> [100] latex2exp_0.9.6 rstan_2.32.7 StanHeaders_2.32.10
#> [103] lubridate_1.9.4 forcats_1.0.0 stringr_1.5.1
#> [106] dplyr_1.1.4 purrr_1.0.4 readr_2.1.5
#> [109] tibble_3.2.1 ggplot2_3.5.2 tidyverse_2.0.0
#> [112] ggtext_0.1.2 concurve_2.7.7 showtext_0.9-7
#> [115] showtextdb_3.0 sysfonts_0.8.9 future.apply_1.11.3
#> [118] future_1.58.0 tidyr_1.3.1 magrittr_2.0.3
#> [121] mice_3.18.0 rms_8.0-0 Hmisc_5.2-3
#>
#> loaded via a namespace (and not attached):
#> [1] igraph_2.1.4 Formula_1.2-5 rematch2_2.1.2
#> [4] GPfit_1.0-9 tidyselect_1.2.1 bridgesampling_1.1-2
#> [7] rngtools_1.5.2 dichromat_2.0-0.1 png_0.1-8
#> [10] cli_3.6.5 arrayhelpers_1.1-0 askpass_1.2.1
#> [13] openssl_2.3.3 textshaping_1.0.1 officer_0.6.10
#> [16] lhs_1.2.0 curl_6.2.3 mime_0.13
#> [19] evaluate_1.0.3 V8_6.0.4 stringi_1.8.7
#> [22] backports_1.5.0 desc_1.4.3 qqconf_1.3.2
#> [25] httpuv_1.6.16 rappdirs_0.3.3 details_0.4.0
#> [28] prodlim_2025.04.28 KMsurv_0.1-6 doRNG_1.8.6.2
#> [31] survminer_0.5.0 DT_0.33 DBI_1.2.3
#> [34] withr_3.0.2 tfruns_1.5.3 reformulas_0.4.1
#> [37] tseries_0.10-58 class_7.3-23 systemfonts_1.2.3
#> [40] rprojroot_2.0.4 lmtest_0.9-40 formatR_1.14
#> [43] colourpicker_1.3.0 htmlwidgets_1.6.4 fs_1.6.6
#> [46] labeling_0.4.3 ranger_0.17.0 DEoptimR_1.1-3-1
#> [49] zoo_1.8-14 itertools_0.1-3 svUnit_1.0.6
#> [52] timechange_0.3.0 caTools_1.18.3 extremevalues_2.4.1
#> [55] data.table_1.17.4 timeDate_4041.110 pan_1.9
#> [58] clipr_0.8.0 ellipsis_0.3.2 lazyeval_0.2.2
#> [61] yaml_2.3.10 survival_3.8-3 crayon_1.5.3
#> [64] tensorA_0.36.2.1 RColorBrewer_1.1-3 later_1.4.2
#> [67] codetools_0.2-20 base64enc_0.1-3 shape_1.4.6.1
#> [70] estimability_1.5.1 gdtools_0.4.2 DiceDesign_1.10
#> [73] foreign_0.8-90 pkgconfig_2.0.3 xml2_1.3.8
#> [76] mathjaxr_1.8-0 ggpubr_0.6.0 viridisLite_0.4.2
#> [79] xtable_1.8-4 plyr_1.8.9 httr_1.4.7
#> [82] rbibutils_2.3 tools_4.5.0 globals_0.18.0
#> [85] hardhat_1.4.1 pkgbuild_1.4.8 htmlTable_2.4.3
#> [88] survMisc_0.5.6 shinyjs_2.1.0 crosstalk_1.2.1
#> [91] twosamples_2.0.1 MatrixModels_0.5-4 lme4_1.1-37
#> [94] digest_0.6.37 numDeriv_2016.8-1.1 furrr_0.3.1
#> [97] farver_2.1.2 tzdb_0.5.0 rapportools_1.2
#> [100] rpart_4.1.24 glue_1.8.0 fracdiff_1.5-3
#> [103] generics_0.1.4 opdisDownsampling_1.0.1 statmod_1.5.0
#> [106] arm_1.14-4 ragg_1.4.0 fontBitstreamVera_0.1.1
#> [109] minqa_1.2.8 mcmc_0.9-8 tcltk_4.5.0
#> [112] texreg_1.39.4 gower_1.0.2 mitools_2.4
#> [115] gtools_3.9.5 ggsignif_0.6.4 lava_1.8.1
#> [118] gridExtra_2.3 shiny_1.10.0 pander_0.6.6
#> [121] threejs_0.3.4 fontLiberation_0.1.0 km.ci_0.5-6
#> [124] rstudioapi_0.17.1 cluster_2.1.8.1 QuickJSR_1.7.0
#> [127] whisker_0.4.1 rstantools_2.4.0 hms_1.1.3
#> [130] anytime_0.3.11 jomo_2.7-6 quadprog_1.5-8
#> [133] xts_0.14.1 shinythemes_1.2.0 ipred_0.9-15
#> [136] quantmod_0.4.27 laeken_0.5.3 e1071_1.7-16
#> [139] urca_1.3-4 TH.data_1.1-3 metafor_4.8-0
#> [142] matrixStats_1.5.0 emmeans_1.11.1 abind_1.4-8
#> [145] bitops_1.0-9 Rdpack_2.6.4 promises_1.3.3
#> [148] bcaboot_0.2-3 inline_0.3.21 sandwich_3.1-1
#> [151] proxy_0.4-27 compiler_4.5.0 prettyunits_1.2.0
#> [154] distributional_0.5.0 metadat_1.4-0 listenv_0.9.1
#> [157] fontquiver_0.2.1 uuid_1.2-1 insight_1.3.0
#> [160] gridtext_0.1.5 R6_2.6.1 fastmap_1.2.0
#> [163] multcomp_1.4-28 rstatix_0.7.2 TTR_0.24.4
#> [166] vcd_1.4-13 ggdist_3.3.3 nnet_7.3-20
#> [169] gtable_0.3.6 shinystan_2.6.0 miniUI_0.1.2
#> [172] RcppParallel_5.1.10 polspline_1.1.25 lifecycle_1.0.4
#> [175] Brobdingnag_1.2-9 zip_2.3.3 pryr_0.1.6
#> [178] nloptr_2.2.1 dygraphs_1.1.1.6 vctrs_0.6.5
#> [181] zeallot_0.2.0 flextable_0.9.9 robustbase_0.99-4-1
#> [184] sp_2.2-0 pracma_2.4.4 pillar_1.10.2
#> [187] magick_2.8.6 jsonlite_2.0.0 svgPanZoom_0.3.4
#> [190] markdown_2.0Stata
about
version
#> Stata/BE 17.0 for Mac (Apple Silicon)
#> Revision 21 May 2024
#> Copyright 1985-2021 StataCorp LLC
#>
#> Total physical memory: 24.00 GB
#>
#> Stata license: Single-user perpetual
#> Serial number: 301706317553
#> Licensed to: Zad Rafi
#> AMG
#>
#> version 17.0————————————————————————
References
References
1. Rafi Z, Greenland S. (2020). “Semantic and cognitive tools to aid statistical science: Replace confidence and significance by compatibility and surprise.” BMC Medical Research Methodology. 20:244. doi: 10.1186/s12874-020-01105-9.
2. Greenland S, Rafi Z. (2020). “Technical Issues in the Interpretation of S-values and Their Relation to Other Information Measures.” arXiv:200812991 [statME]. https://arxiv.org/abs/2008.12991.
3. Greenland S. (2019). “Valid P-values behave exactly as they should: Some misleading criticisms of P-values and their resolution with S-values.” The American Statistician. 73:106–114. doi: 10.1080/00031305.2018.1529625.
4. Bayarri MJ, Berger JO. (2000). “P Values for Composite Null Models.” Journal of the American Statistical Association. 95:1127–1142. doi: 10/dpvq8c.
5. Robins JM, van der Vaart A, Ventura V. (2000). “Asymptotic Distribution of P Values in Composite Null Models.” Journal of the American Statistical Association. 95:1143–1156. doi: 10/gg7krv.
6. Kuffner TA, Walker SG. (2019). “Why are P-values controversial?” The American Statistician. 73:1–3. doi: 10.1080/00031305.2016.1277161.
7. Cousins RD. (2017). “The Jeffreys paradox and discovery criteria in high energy physics.” Synthese. 194:395–432. doi: 10.1007/s11229-014-0525-z.
8. Cox DR, Hinkley DV. (1974). “Chapter 7, Interval estimation.” In: Theoretical Statistics. Chapman and Hall/CRC. p. 207–249. doi: 10.1201/b14832.
9. Bowley AL. (1934). “Discussion on Dr. Neyman’s Paper. P. 607 in: Neyman J. On the two different aspects of the representative method: The method of stratified sampling and the method of purposive selection (with discussion).” Journal of the Royal Statistical Society. 4:558–625. doi: 10.2307/2342192.
10. Cox DR. (2006). “Principles of Statistical Inference.” Cambridge University Press.
11. Amrhein V, Trafimow D, Greenland S. (2019). “Inferential statistics as descriptive statistics: There is no replication crisis if we don’t expect replication.” The American Statistician. 73:262–270. doi: 10.1080/00031305.2018.1543137.
12. Greenland S, Senn SJ, Rothman KJ, Carlin JB, Poole C, Goodman SN, et al. (2016). “Statistical tests, P values, confidence intervals, and power: A guide to misinterpretations.” European Journal of Epidemiology. 31:337–350. doi: 10.1007/s10654-016-0149-3.
13. Greenland S. (2019). “Are confidence intervals better termed ‘uncertainty intervals’? No: Call them compatibility intervals.” BMJ. 366. doi: 10.1136/bmj.l5381.
14. Greenland S, Rafi Z. (2020). “To Aid Scientific Inference, Emphasize Unconditional Descriptions of Statistics.” arXiv:190908583 [statME]. https://arxiv.org/abs/1909.08583.
15. Brown HK, Ray JG, Wilton AS, Lunsky Y, Gomes T, Vigod SN. (2017). “Association between serotonergic antidepressant use during pregnancy and autism spectrum disorder in children.” Journal of the American Medical Association. 317:1544–1552. doi: 10.1001/jama.2017.3415.
16. Brown HK, Hussain-Shamsy N, Lunsky Y, Dennis C-LE, Vigod SN. (2017). “The association between antenatal exposure to selective serotonin reuptake inhibitors and autism: A systematic review and meta-analysis.” The Journal of Clinical Psychiatry. 78:e48–e58. doi: 10.4088/JCP.15r10194.
17. Jewell NP. (2003). “Statistics for Epidemiology.” CRC Press.
18. Royall R. (1997). “Statistical Evidence: A Likelihood Paradigm.” CRC Press.
19. Davies PL. (2008). “Approximating data [with discussion and a rejoinder].” Journal of the Korean Statistical Society. 37:191–211. doi: 10/bn8cgk.
Citation
BibTeX citation:
@online{panda2020,
author = {Panda, Sir and Rafi, Zad},
title = {Tables, {Graphs,} and {Computations} from {Rafi} \&
{Greenland} (2020)},
date = {2020-12-12},
url = {https://lesslikely.com/posts/statistics/RG2020BMC.html},
langid = {en}
}
For attribution, please cite this work as:
1. Panda S, Rafi Z. (2020). ‘Tables, Graphs, and Computations from
Rafi & Greenland (2020)’. https://lesslikely.com/posts/statistics/RG2020BMC.html.