Vol. XII · Estd. 2018
New York, NY
A place for statistical science, medicine, and the quiet arithmetic of being wrong less often.
Featured this issue
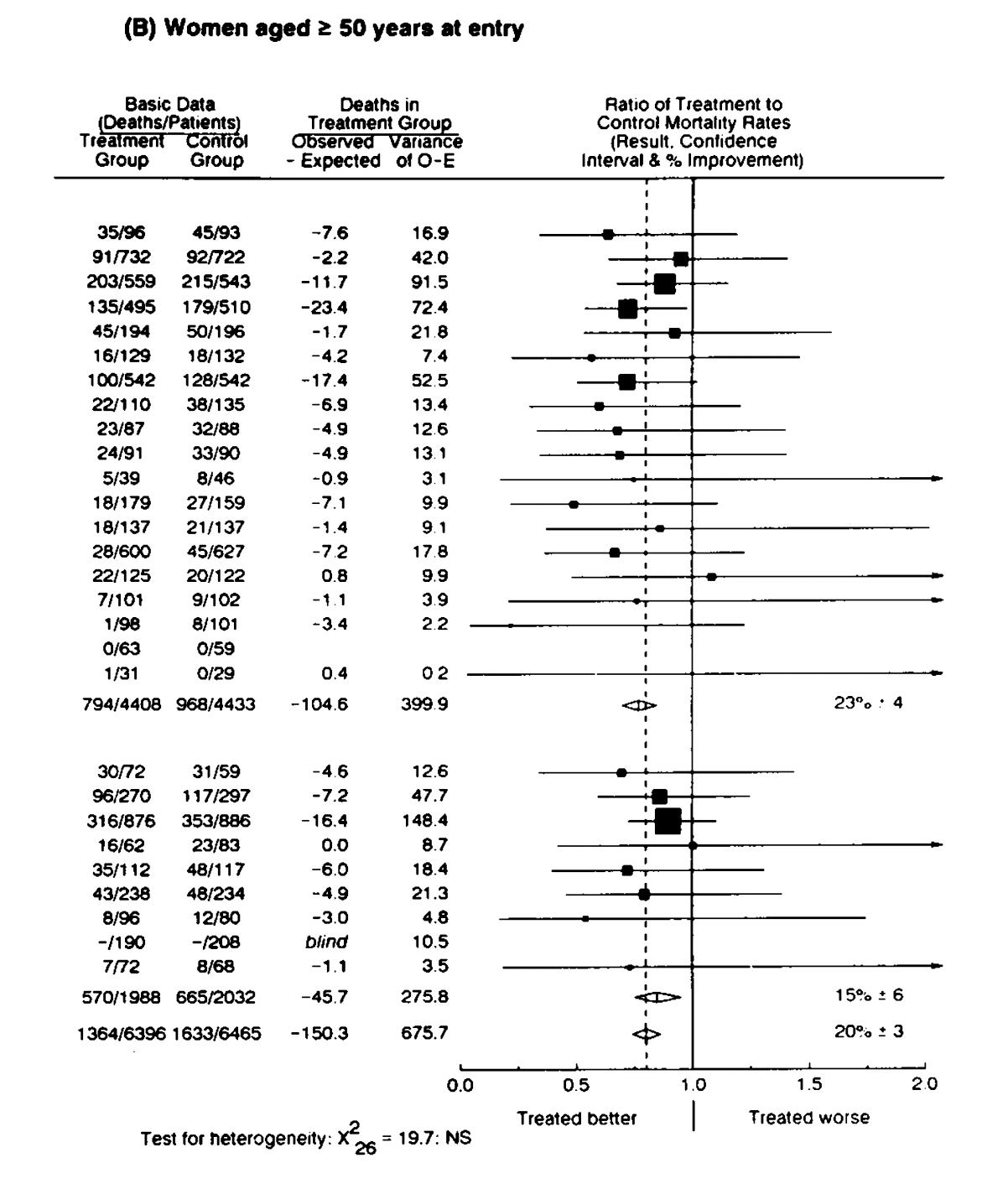
No matching items
Latest articles
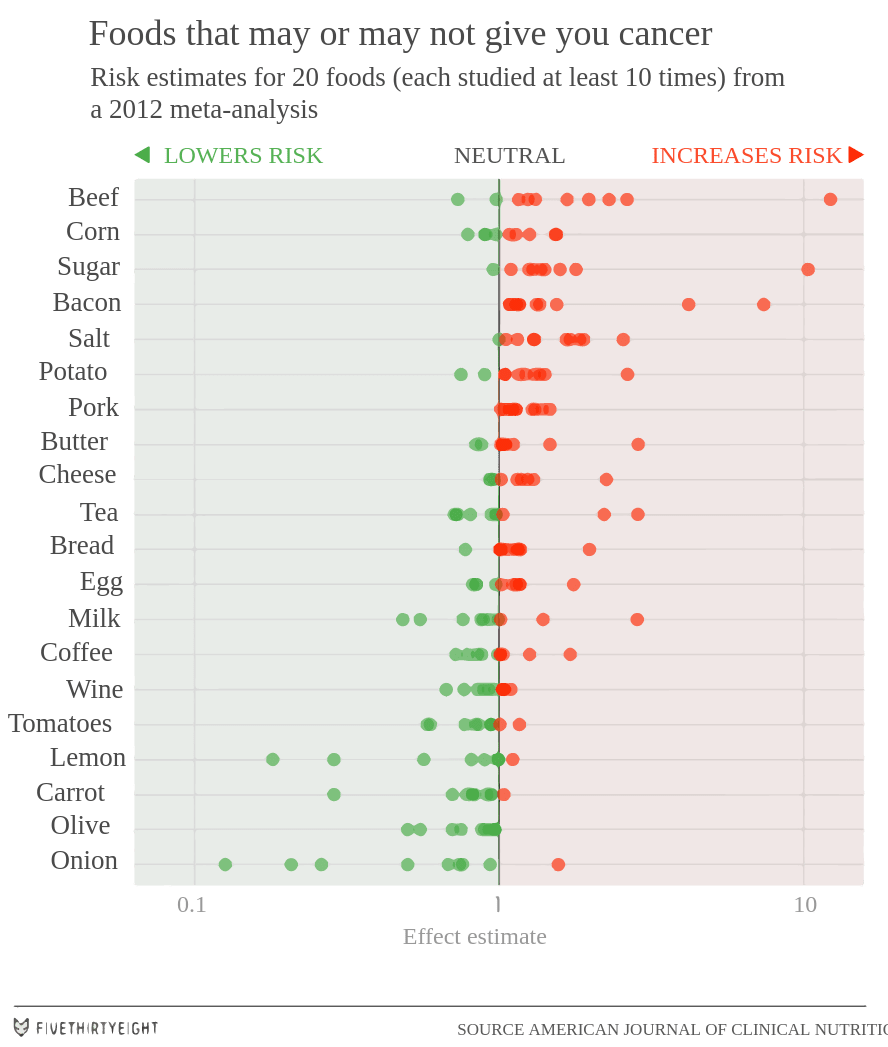
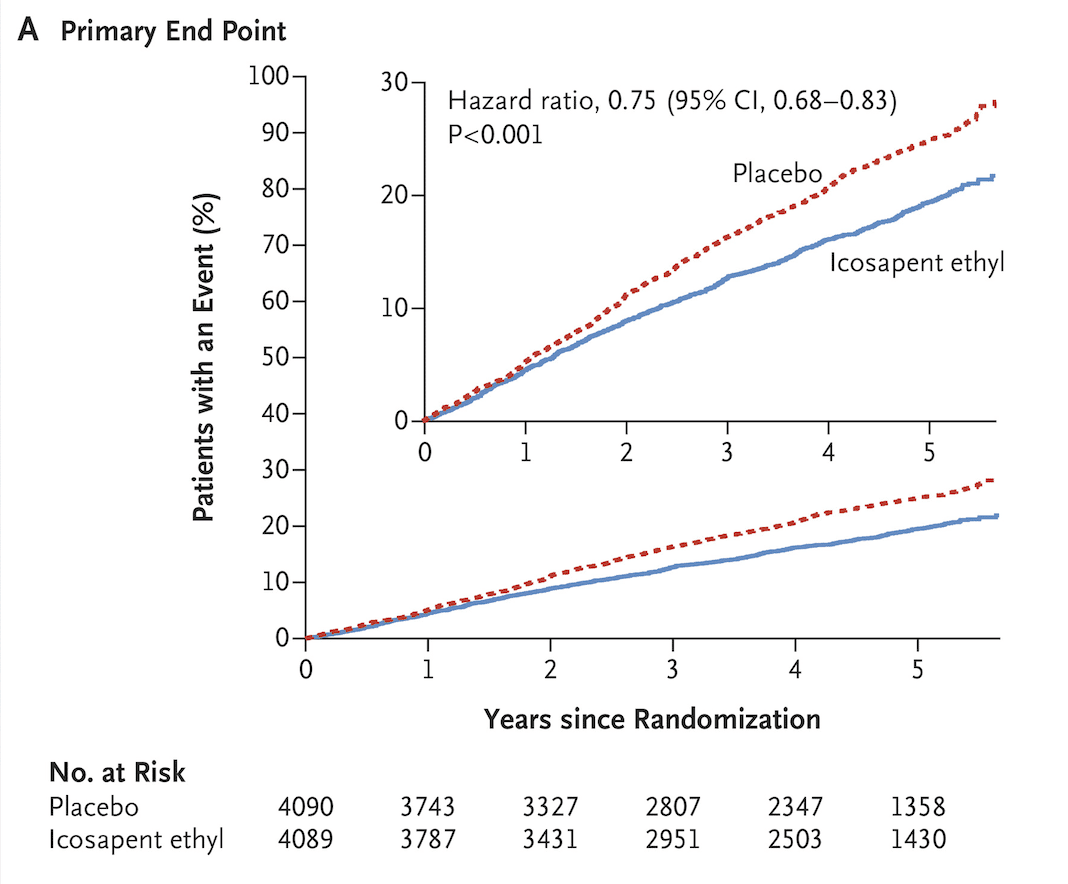


No matching items
End of selection
All articles →
30+Pages
27Articles
3Departments
∞Caveats
Recurring themes
N° 01
Sensitivity analysis
How conclusions move when assumptions wobble — tipping points, multiverse runs, robustness.
N° 02Causal inference
Drawing causal claims from observational data, and the price of doing it carelessly.
N° 03Bayesian thinking
Posteriors, priors, and the uncomfortable but useful business of saying what you actually believe.
N° 04The bootstrap
Resampling for uncertainty quantification — when it works, when it lies, and why.
N° 05Surrogates & trials
Endpoints that aren't outcomes, and trials that almost answer the question you asked.
N° 06Nutritional epidemiology
Why food-and-disease studies are hard, and what to read when someone reports otherwise.
No matching items
Comments