The studies that gain the most attention from the media are usually nutritional epidemiological studies. However, there is a good reason to be skeptical of these types of studies and in this blog post, I explain why.
Nutritional epidemiology studies the relationship between diet and disease, and like many other epidemiological disciplines, it hopes to develop interventions and policies that will improve the health of the public. The field has had some success in the past by observing certain associations and implementing public health interventions that lead to large effects, as shown by the following findings:
Observational Findings
Health Interventions
Linking folate deficiency to a higher risk of neural tube defects.1, 2
Linking the consumption of trans fats to a higher risk of cardiovascular disease.4
FDA limits/bans the production of foods with trans fats.5
Linking high fish consumption to longer pregnancies.6
Cochrane concludes strong evidence that omega-3 supplementation is effective for reducing risk of preterm birth.7
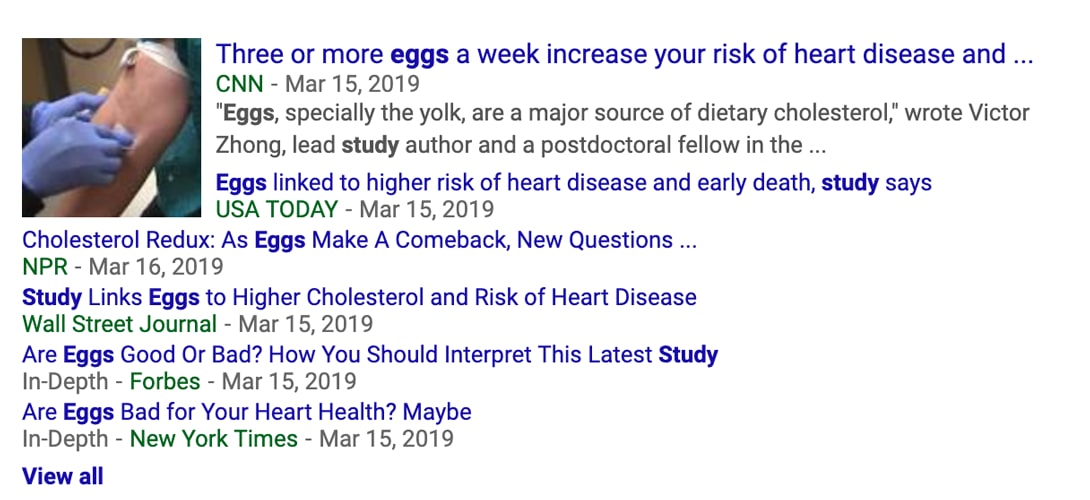
However, these sorts of occurences have been rare and unfortunately, the field continues to publish several studies every year that have lead to little progress in nutrition research. Despite this, nutritional epidemiological researchers will often overexaggerate their findings during press releases and the media loves covering these sorts of studies.
This is one of my favorite ones.
This has lead to severe criticism of the field, with the leading meta researcher in the world exclaiming,
“Nutritional Epidemiology is a scandal. It should just go to the waste bin.” - John Ioannidis
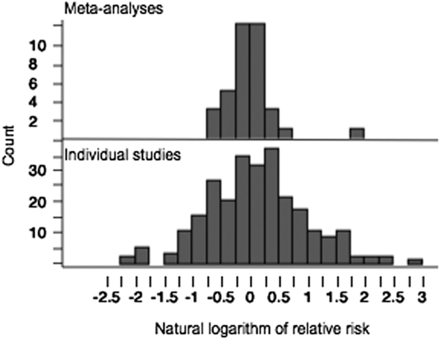
In one meta-study,8 Ioannidis showed that several random food ingredients from a cookbook had large associations with cancers, as shown below. Some of these effects were simply implausible.
Schoenfeld JD, Ioannidis JP. Is everything we eat associated with cancer? A systematic cookbook review. The American Journal of Clinical Nutrition. 2013;97(1):127-134. doi:10.3945/ajcn.112.047142
However, when several of the studies were pooled in meta-analyses, these large effects shrunk as shown below.
Schoenfeld JD, Ioannidis JP. Is everything we eat associated with cancer? A systematic cookbook review. The American Journal of Clinical Nutrition. 2013;97(1):127-134. doi:10.3945/ajcn.112.047142
Defenders of nutritional epidemiology will often exclaim that the purpose of the field is to produce studies that “generate hypotheses,” that other researchers can follow up on with randomized trials.
However, this argument holds little merit, given that many of the associations that are found are never followed up on, are simply implausible (with little background biology to support them), lead to wasted resources when they are followed up on,9 and are used to argue for policy changes without any confirmation by clinical trials or research syntheses.10
Cole (1993)11 elegantly addressess these points in the “The Hypothesis Generating Machine”,
On the other hand, nearly all of the hypotheses that are said to be generated by a study are unworthy of the name: they are seen only once, they are usually weak, and many are contradicted by data…
What is relevant is the credibility of the hypothesis. This credibility is to be assessed by a review of all available knowledge within a frameowrk of reasonable criteria of causality. Thus, complex notions of generating, testing, accepting, and rejecting can be abandoned…
It occurred to me that it is unnecessary and unproductive to wait for future studies to generate hypotheses. After all, there is a boundless number of hypotheses that could be generated, nearly all of them wrong. Therefore, if we are going to get anywhere at all with this approach, we should go about it systemtically and rapidly.
Cole’s fears have turned out to be true. There are dozens, if not hundreds, of nutritional epidemiological studies that are published every year, and few of them have lead to any substantial gains in knowledge.
Concordance with randomized clinical trials (often considered one of the most efficient ways to causally determine treatment effects) has also been poor. This can be seen with contradictions between observational studies and RCTs about Vitamin D,12 Vitamin C, Vitamin E,13 beta carotene,14 and fish oil15.
This article will explore why nutritional epidemiology has largely failed to produce much useful knowledge and offer some practical recommendations along the way for researchers in this domain (make no mistake, this article is also written for the average person interested in this topic).
The initial focus will be on measurement error, something that plagues not only nutritional epidemiological studies, but also randomized controlled trials that are not tightly monitored (such as metabolic ward studies).
Measurement Error
Traditionally, researchers have attempted to measure the composition of an individual’s diet via three methods, food frequency questionnaires, 24-hour food recalls, and dietary food records. All of these methods rely on the participant’s memory, making them heavily prone to systematic errors, such as classical measurement error \(W_{ij}=X_{i}+ \epsilon_{ij}\).
Food frequency questionnaires (FFQ) (first pioneered in the 1960s16) attempt to assess how often an individual eats certain amounts of foods. These methods are widely used because they are cheap, easy to collect, and provide researchers with information about long-term dietary habits. There are even parody videos about them, such as the one below.
24-hour food recalls are the most widely used method to assess dietary intake and involve interviewers spending 15-20 minutes asking participants what they ate in the last 24 hours. While this method may seem more reliable than the FFQ, metabolic ward studies17, 18 have shown that even in 24-hour recalls, participants often erroneously reported eating foods that were not eaten or omitted those that were.
Food diaries are also used to assess dietary habits, however, they are limited because they rely on the individual accurately weighing and reporting food intake during every meal for several days. This puts a lot more burden on the participant than the other methods, making them less likely to properly report food intake. This method is the least widely used and much less is known about its systematic errors (yes, food diaries also suffer from bias!).
The measurement error that results from using these methods is well known, however, another issue that is less discussed is the disregarding of the effects of individual foods. Since most of these methods attempt to compute nutrient intake and conflate nutrient composition with the food itself, valuable information is discarded. For example, milk and yogurt are known to have similar nutrient profiles, yet, they have different physiological effects,19 but in a typical nutritional epidemiological study, they will likely be treated as the same due to similar nutrient profiles.
As an example, in nearly all observational studies of nutrient effects, individual risks are regressed directly on nutrient intakes calculated from food intakes. This conventional model makes no further use of the food intakes, and so assumes implicitly that foods have no effect on risk beyond their calculated nutrient content.
This is an unsupported and very doubtful assumption. A more realistic model allows food effects beyond measured-nutrient content. However, the resulting two-level hierarchical model is not identified without a prior because nutrient intakes are linear functions of food intakes (making nutrient and food intakes completely collinear).
Using any contextually defensible prior reveals that the conventional analysis generates overconfident inferences, both in the Bayesian sense of overstating information (Greenland, 2000), and also in the frequentist sense of producing interval undercoverage (Gustafson and Greenland, 2006). That overconfidence may explain the rather embarrassing track record of nutritional epidemiology when compared against clinical trials (Lawlor et al., 2004).
With all this, and more, in mind, some researchers21 have argued the following about the current methods used to assess food intake:
The use of memory-based methods is founded upon two inter-related logical fallacies: a category error and reification
Human memory and recall are not valid instruments for scientific data collection
The measurement errors of memory-based dietary assessment methods are neither quantifiable nor falsifiable; this renders these methods and data pseudoscientific
The post hoc process of pseudoquantification is impermissible and invalid
Memory-based dietary data were repeatedly demonstrated to be physiologically implausible (i.e., meaningless numbers)
The failure to cite or acknowledge contrary evidence and empirical refutations contributed to a fictional discourse on diet-disease relations
Our conclusion is that nutrition epidemiology is a degenerating research paradigm in which the use of expedient but nonfalsifiable anecdotal evidence impeded scientific progress and engendered a fictional discourse on diet-health relations. The continued funding and use of memory-based methods such as Food Frequency Questionnaires and 24-hour dietary interviews is anathema to evidence-based public policy.
Thus, our recommendation is simply that the use of memory-based methods must stop and all previous articles presenting memory-based methods data and conclusions must be corrected to include contrary evidence and address the consequences of a half century of pseudoscientific claims.
However, many other researchers22 have pointed out errors in the analysis by the author of that excerpt (Archer et al) and believe that Archer et al overstates the evidence against FFQ data.22
Measurement error is inherent in all types of data. The errors in self-report dietary intake data are well documented. On the basis of current knowledge, we recommend that investigators:
continue to collect self-report dietary intake data because they contain valuable, rich, and critical information about foods and beverages consumed by populations that can be used to inform nutrition policy and assess diet-disease associations;
not use self-reported EI as a measure of EI;
use self-reported EI for energy adjustment of other self reported dietary constituents to improve risk estimation in studies of diet-health associations;
acknowledge the limitations of self-report dietary data and analyze and interpret them appropriately;
design studies and conduct analyses that allow adjustment for measurement error;
design new epidemiologic studies to collect dietary data from both short-term (24HRs or FRs) and long-term (FFQs) instruments on the entire study population to allow for maximizing the strengths of each instrument; and
continue to develop, evaluate, and further expand methods of dietary assessment, including dietary biomarkers and methods using new technologies.
Self-report dietary data provide information on food intake, food behaviors, and eating patterns that is not possible to obtain from a comprehensive set of biomarkers. To guide people in how to eat more healthfully, asking them what they are currently eating is imperative and should not be abandoned.
Thus, it seems prudent to supplement these measurements with each other (if possible) and with other methods such as surrogate biomarkers, as outlined by Keogh, White, & Rodwell, 2013.23
The use of surrogate biomarkers allows us to relax the assumptions that errors in FFQs and food records are independent and that errors in repeated measurements using the same instrument are independent, which in the past have been made in validation studies involving only FFQ and diet diary.
However, this comes at the price of assuming that errors in surrogate biomarker measurements are independent of errors in self‐reported measurements conditional on covariates, and an inability to estimate the correlation between errors in repeated surrogate biomarker measurement, ρMM.
In the illustration of the model, we showed that different assumptions about the values of these parameters can result in RDRs covering a wide range. This is an important result; it suggests that we should be highly sceptical about results obtained under the usual assumptions and cautious to draw firm conclusions about the degree of error in self‐reported measurements unless more information can be obtained about the relationship between the surrogate biomarker in question and true intake.
Keogh & White, 201424 also provide recommendations on how to account for these issues in the analysis phase via methods such as regression calibration, moment reconstruction, multiple imputation, and graphical methods, along with sensitivity analyses.
We emphasized the use of RC to make corrections for measurement error, this being the most popular approach in practice. We also showed how RC can be extended to incorporate sensitivity analyses to investigate the potential impact of departures from classical error on corrected estimates of exposure-outcome associations.
The use of sensitivity analyses such as these is important in nutritional epidemiology, where there is evidence of systematic errors in dietary measurements, but few unbiased measures with which to make comparisons. If a validation study is available, in which the true exposure is observed, then no sensitivity analyses are necessary.
While this section has now concluded on the very complicated issue of measurement error, the next issue is just as, if not more, complicated and involves confounding and multiplicity.
Confounding and Multiplicity
The reason that randomized controlled trials are so efficient in estimating causal treatment effects is because they randomly distribute covariates and reduce systematic variation and selection bias.25, 26
In epidemiological studies, such as in nutritional epidemiology, researchers often use a variety of methods such as statistical adjustments, matching/propensity scores, and several other sophisticated methods to make groups as comparable as possible.
So one of the biggest issues that remains is what covariates should be included in a statistical model for adjustment? Typically, many researchers will use stepwise methods such as backward selection, where they include all covariates that are available to them in the model, and delete those with the largest P-values.
Another stepwise approach typically used is forward selection, where researchers will start with no predictors and add covariate by covariate, including only those that result in highly significant results.
There are numerous problems with these approaches27–31 and they result in biased overestimates and abuse both P-values and a decision making paradigm that was intended for quality inspection. Again, nutritional epidemiological studies are observational and most of the exposures are not random (an assumption often assumed to be true when computing P-values).32, 33
Greenland summarizes this issue with clarity in his 1990 paper published in Epidemiology.32
Randomization provides the key link between inferential statistics and causal parameters. Inferential statistics, such as P values, confidence intervals, and likelihood ratios, have very limited meaning in causal analysis when the mechanism of exposure assignment is largely unknown or is known to be nonrandom. It is my impression that such statistics are often given a weight of authority appropriate only in randomized studies
Variable selection in statistical modeling is a very complex subject, however, one method that may aid a researcher involves consulting subject-matter experts and drawing out all knowledge/assumptions using directed acyclical graphs34, commonly referred to as DAGs.
This may aid researchers in knowing what to adjust for in a statistical model, while avoiding adjusting for things that may result in biased, spurious associations, such as collider bias (shown below).
VanderWeele TJ. Principles of confounder selection. European Journal of Epidemiology. 2019;34(3):211-219. doi:10.1007/s10654-019-00494-6
Some epidemiologists35 have recommended utilizing the “disjunctive cause criterion” for selecting covariates to adjust for. In this framework, covariates that are known to cause the exposure or the outcome are included in the model.
While these methods are a large improvement over mindless inclusion of variables within a model, the issue remains, diets are linked to nearly everything (making confounding a really tough problem to deal with), effects tend to be small, and it is easy to shift these effects based on inclusion or deletion of a few covariates.
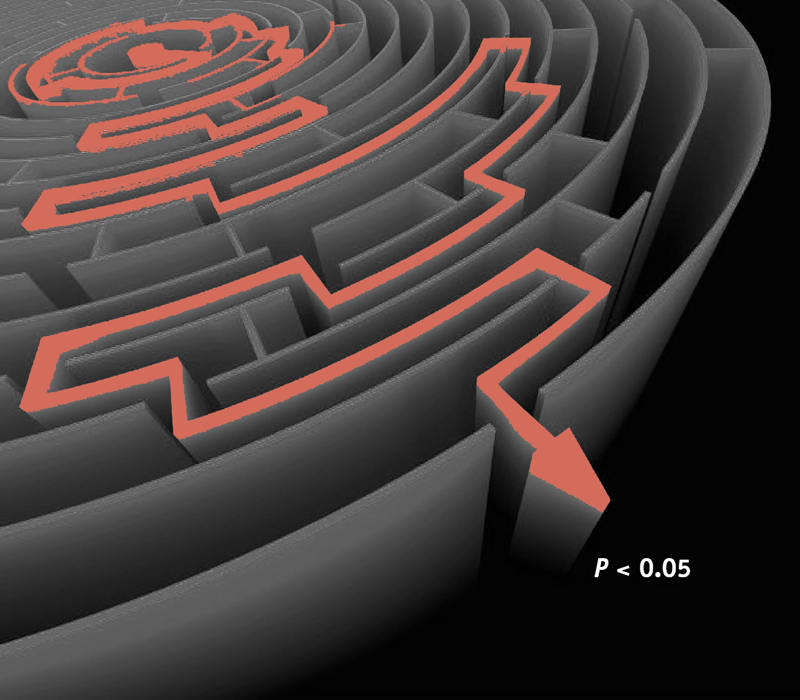
The statistician Stan Young pointed out how this flexibility could be problematic in the journal Significance.36
For example, consider the use of linear regression to adjust the risk levels of two treatments to the same background level of risk. There can be many covariates, and each set of covariates can be in or out of the model. With ten covariates, there are over 1000 possible models. Consider a maze as a metaphor for modelling (Figure 3).
The red line traces the correct path out of the maze. The path through the maze looks simple, once it is known. Returning to a linear regression model, terms can be put into and taken out of a regression model. Once you get a p‐value smaller than 0.05, the model can be frozen and the model selection justified after the fact. It is easy to justify each turn.
In a similar meta-study,37 titled “Assessment of vibration of effects due to model specification can demonstrate the instability of observational associations”, John Ioannidis showed that by using different combinations of a certain number of covariates, you could virtually make effects go in either direction (type S (sign) errors) or change their magnitude (type M errors).37
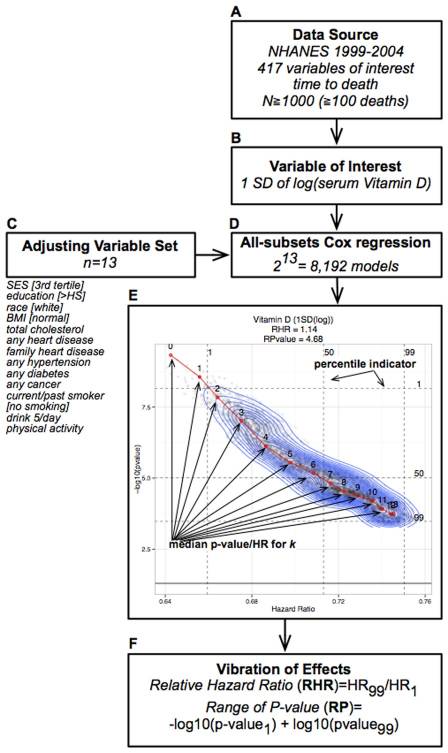
In the study, Ioannidis downloaded 13 variables from the NHANES dataset that were linked to all-cause mortality, and that had a substantial number of participants associated with each variable (at least 1000 participants and 100 deaths).
From those 13 variables, he was able to produce 8,192 different statistical models that all resulted in different hazard ratios (HR), as seen in the image below. The variables were included age, smoking, BMI, hypertension, diabetes, cholesterol, alcohol consumption, education, income, sex, family history of heart disease, heart disease, and any cancer.
Patel CJ, Burford B, Ioannidis JPA. Assessment of vibration of effects due to model specification can demonstrate the instability of observational associations. J Clin Epidemiol. 2015;68(9):1046-1058.
For one particular relationship between vitamin D and all-cause mortality, Ioannidis reported that with no adjustment of covariates, Vitamin D resulted in an impressive 0.64 HR. A 36% decrease. However, when all 13 covariates are included in the model, the HR increases to 0.75.
Ioannidis and Patel recommended reporting all possible statistical models from all possible combinations of covariates and to report the median of all these models, rather than selectively reporting a few models. And to note whether there was something called a “Janus effect”, where the effect size would go in both directions.
In the last pattern, as exemplified by α-tocopherol, the estimated HRs can be both greater and less than the null value (HR > 1 and HR ≤ 1) depending on what adjustments were made. We call this the Janus effect after the two-headed representation of the ancient Roman god.
For α-tocopherol, most of the HR and p-values were concentrated around 1 and non-significance, respectively… The Janus effect is common: 131 (31%) of the 417 variables had their 99th percentile HR>1 and their 1st percentile HR < 1.
However, statistician/epidemiologist, Sander Greenland has been a critic of meta-research and epidemiological studies that lack biochemical sophistication and lump several compounds together as if they were the same and behaved the same in the body.
“For nutrition, the lack of biochemistry sophistication among the trial designers leads to a lot of dubious and noncomparable studies, while the meta-analysts and reviewers do a lot of distortive lumping, e.g., talking about “vitamin E” as if that were a single entity.
A recent review by prominent authors didn’t even notice that almost all trials used the racemic synthetic mixture, dl-alpha-tocopheryl, (which they misidentify with “alpha tocopherol”) with vastly diferent and unjustifed dosages, and which hardly resembles the eight or so natural d-tocopherols or d-tocotrienols that account for dietary intake.”37
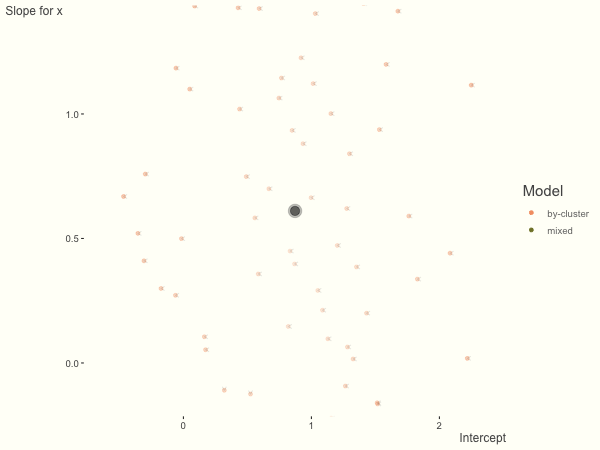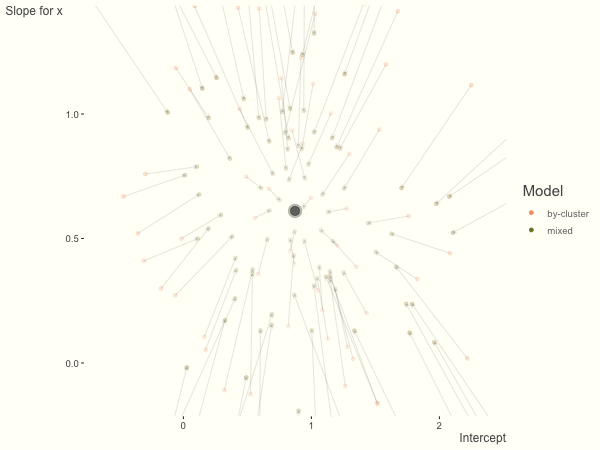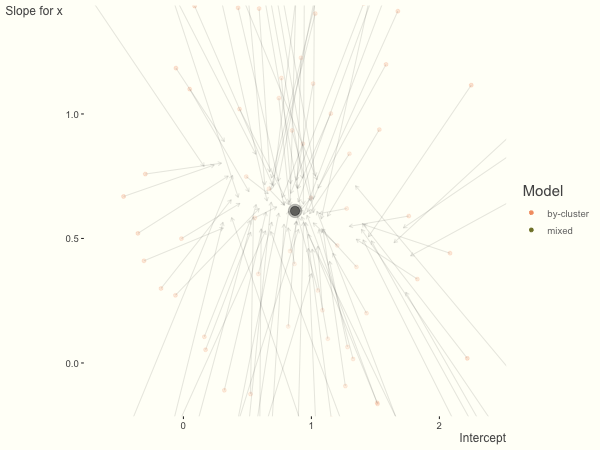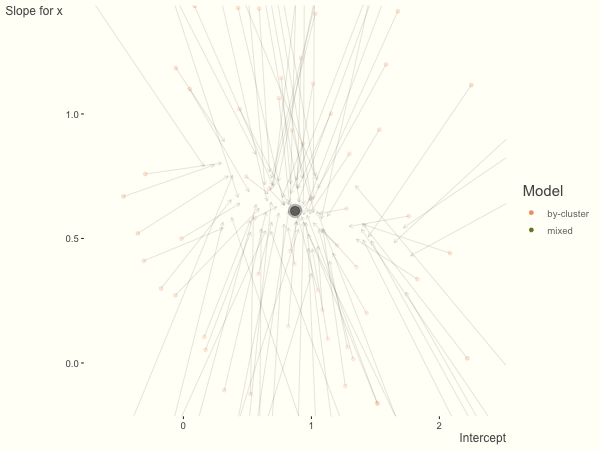
A reasonable way to address the issue of model selection seems to be using sensitivity analyses and multiverse analyses38 to see all possible variations, whilst using hierarchical modeling and shrinkage estimators39, 40 (shown below) to partially pool results towards zero.
Taken from Clark (2019, May 18). Michael Clark: Shrinkage in Mixed Effects Models. Retrieved from https://m-clark.github.io/posts/2019-05-14-shrinkage-in-mixed-models/
Poor Concordance with Randomized Trials
Another common criticism is that the findings of nutritional epidemiological studies are rarely corroborated by randomized trials, which is well known from studies of Vitamin D,12 Vitamin C, Vitamin E,13 beta carotene,14 and fish oil15. In 201136, the statistician Stan Young decided to assess what concordance was like between observational studies and randomized clinical trials. Young writes,
We ourselves carried out an informal but comprehensive accounting of 12 randomised clinical trials that tested observational claims – see Table 1. The 12 clinical trials tested 52 observational claims. They all confirmed no claims in the direction of the observational claims. We repeat that figure: 0 out of 52. To put it another way, 100% of the observational claims failed to replicate.
In fact, five claims (9.6%) are statistically significant in the clinical trials in the opposite direction to the observational claim. To us, a false discovery rate of over 80% is potent evidence that the observational study process is not in control. The problem, which has been recognised at least since 1988, is systemic.
However, there are some issues with these particular conclusions.
The randomized trials are nowhere near as large as the observational studies, therefore it is likely that the designs were too small to detect an effect of interest and reject the null hypothesis. Thus, focusing on statistical significance makes little sense.
In observational studies, there often is no random mechanism such as random assignment or random sampling, thus, putting significant weight on a decision theoretic like statistical significance is rarely justified.Greenland1990-ay?.
In the same paper,Greenland1990-ay? Greenland also points out the problems with several probabilistic arguments that are used to justify classical statistics in areas where the exposure is unknown or unlikely to be random. He proposes some possible solutions:
In causal analysis of observational data, valid use of inferential statistics as measures of compatibility, conflict, or support depends crucially on randomization assumptions about which we are at best agnostic and more usually doubtful. Among the possible remedies are:
Restrain our interpretation of classical statistics by explicating and criticizing any randomization assumptions that are necessary for probabilistic interpretations;
train our students and retrain ourselves to focus on nonprobabilistic interpretations of inferential statistics;
deemphasize inferential statistics in favor of pure data descriptors, such as graphs and tables;
expand our analytic repertoire to include more elaborate techniques that depend on assumptions in the “agnostic” rather than the “doubtful” realm, and subject the results of these techniques to influence and sensitivity analysis.
These are neither mutually exclusive nor exhaustive possibilities, but I think any one of them would constitute an improvement over much of what we have done in the past.
As we can see, there are plenty of issues with nutritional epidemiology as its currently done. Some, like Trepanowski & Ioannidis41 believe that the field should stop producing studies altogether and that randomized studies should be the focus of nutrition research with a focus on how to overcome common issues faced by RCTs.
The aforementioned epistemologic problems cannot be overcome with the research designs that are currently used in nutrition science. Nonrandomized observational research simply involves too much confounding.
It is also more vulnerable to publication and selective-outcome reporting biases (47) compared with randomized research, because it is more difficult to ascertain how many observational data sets are available worldwide that can address a given exposure-outcome relation (48).
Although some epidemiologists register their analysis protocols, this is falsely reassuring because it can easily be done after peeking at the relevant data surreptitiously.
However, the reality is that nonrandomized studies will often be needed when randomized studies are simply not possible and nonrandomized studies are not going anywhere. Thus, a great deal of effort should be placed into improving nutritional epidemiological research to make it more useful.
1. Hibbard BM. (1964). “The Role of FolicAcid in Pregnancy; WithParticularReference to Anaemia, Abruption and Abortion.”The Journal of obstetrics and gynaecology of the British Commonwealth. 71:529–542.
3. Honein MA, Paulozzi LJ, Mathews TJ, Erickson JD, Wong LY. (2001). “Impact of folic acid fortification of the US food supply on the occurrence of neural tube defects.”JAMA : the journal of the American Medical Association. 285:2981–2986. doi: 10.1001/jama.285.23.2981.
4. Willett WC, Ascherio A. (1994). “Trans fatty acids: Are the effects only marginal?”American journal of public health. 84:722–724.
5. Dewey C. (2018). “Analysis Artificial trans fats, widely linked to heart disease, are officially banned.”Washington post (Washington, DC : 1974).
6. Leventakou V, Roumeliotaki T, Martinez D, Barros H, Brantsaeter A-L, Casas M, et al. (2014). “Fish intake during pregnancy, fetal growth, and gestational length in 19 European birth cohort studies.”American Journal of Clinical Nutrition. 99:506–516. doi: 10.3945/ajcn.113.067421.
7. Middleton P, Gomersall JC, Gould JF, Shepherd E, Olsen SF, Makrides M. (2018). “Omega-3 fatty acid addition during pregnancy.”Cochrane database of systematic reviews (Online). 11:CD003402. doi: 10.1002/14651858.CD003402.pub3.
8. Schoenfeld JD, Ioannidis JP. (2013). “Is everything we eat associated with cancer? A systematic cookbook review.”The American journal of clinical nutrition. 97:127–134. doi: 10.3945/ajcn.112.047142.
9. Pittas AG, Dawson-Hughes B, Sheehan P, Ware JH, Knowler WC, Aroda VR, et al. (2019). “Vitamin DSupplementation and Prevention of Type 2 Diabetes.”New England Journal of Medicine. 381:520–530. doi: 10.1056/NEJMoa1900906.
10. Prasad V, Jorgenson J, Ioannidis JPA, Cifu A. (2013). “Observational studies often make clinical practice recommendations: An empirical evaluation of authors’ attitudes.”Journal of clinical epidemiology. 66:361–366.e4. doi: 10.1016/j.jclinepi.2012.11.005.
11. Cole P. (1993). “The HypothesisGeneratingMachine.”Epidemiology (Cambridge, Mass). 4:271. doi: 10.1097/00001648-199305000-00012.
12. Barbarawi M, Kheiri B, Zayed Y, Barbarawi O, Dhillon H, Swaid B, et al. (2019). “Vitamin DSupplementation and CardiovascularDiseaseRisks in MoreThan 83 000 Individuals in 21 RandomizedClinicalTrials: AMeta-Analysis.”JAMA cardiology. doi: 10.1001/jamacardio.2019.1870.
13. Lawlor DA, Smith GD, Bruckdorfer KR, Kundu D, Ebrahim S. (2004). “Those confounded vitamins: What can we learn from the differences between observational versus randomised trial evidence?”The Lancet. 363:1724–1727. doi: 10.1016/S0140-6736(04)16260-0.
14. Druesne-Pecollo N, Latino-Martel P, Norat T, Barrandon E, Bertrais S, Galan P, et al. (2010). “Beta-carotene supplementation and cancer risk: A systematic review and metaanalysis of randomized controlled trials.”International Journal of Cancer. 127:172–184. doi: 10.1002/ijc.25008.
15. Abdelhamid AS, Brown TJ, Brainard JS, Biswas P, Thorpe GC, Moore HJ, et al. (2018). “Omega-3 fatty acids for the primary and secondary prevention of cardiovascular disease.”Cochrane database of systematic reviews (Online). 7:CD003177. doi: 10.1002/14651858.CD003177.pub3.
16. Heady JA. (1961). “Diets of BankClerksDevelopment of a Method of Classifying the Diets of Individuals for Use in EpidemiologicalStudies.”Journal of the Royal Statistical Society Series A (General). 124:336–371. doi: 10.2307/2343242.
17. Karvetti RL, Knuts LR. (1985). “Validity of the 24-Hour dietary recall.”Journal of the American Dietetic Association. 85:1437–1442.
18. Madden JP, Goodman SJ, Guthrie HA. (1976). “Validity of the 24-Hr. Recall. Analysis of data obtained from elderly subjects.”Journal of the American Dietetic Association. 68:143–147.
19. Mertz W. (1984). “Foods and nutrients.”Journal of the American Dietetic Association (USA).
20. Greenland S. (2010). “Comment: TheNeed for Syncretism in AppliedStatistics.”Statistical Science. 25:158–161. doi: 10.1214/10-STS308A.
21. Archer E, Marlow ML, Lavie CJ. (2018). “Controversy and debate: Memory-BasedMethodsPaper 1: The fatal flaws of food frequency questionnaires and other memory-based dietary assessment methods.”Journal of Clinical Epidemiology. 104:113–124. doi: 10.1016/j.jclinepi.2018.08.003.
22. Subar AF, Freedman LS, Tooze JA, Kirkpatrick SI, Boushey C, Neuhouser ML, et al. (2015). “Addressing CurrentCriticismRegarding the Value of Self-ReportDietaryData12.”The Journal of nutrition. 145:2639–2645. doi: 10.3945/jn.115.219634.
24. Keogh RH, White IR. (2014). “A toolkit for measurement error correction, with a focus on nutritional epidemiology.”Statistics in Medicine. 33:2137–2155. doi: 10.1002/sim.6095.
25. Kempthorne O. (1977). “Why randomize?”Journal of Statistical Planning and Inference. 1:1–25. doi: 10.1016/0378-3758(77)90002-7.
27. Hurvich CM, Tsai C-L. (1990). “The Impact of ModelSelection on Inference in LinearRegression.”The American Statistician. 44:214–217. doi: 10.1080/00031305.1990.10475722.
29. Livingston E, Cao J, Dimick JB. (2010). “Tread CarefullyWithStepwiseRegression.”Archives of surgery (Chicago, Ill : 1920). 145:1039–1040. doi: 10.1001/archsurg.2010.240.
30. Steyerberg EW, Eijkemans MJ, Habbema JD. (1999). “Stepwise selection in small data sets: A simulation study of bias in logistic regression analysis.”Journal of clinical epidemiology. 52:935–942.
31. Thompson B. (1995). “Stepwise Regression and StepwiseDiscriminantAnalysisNeedNotApply here: AGuidelinesEditorial.”Educational and Psychological Measurement. 55:525–534. doi: 10.1177/0013164495055004001.
32. Greenland S. (1990). “Randomization, statistics, and causal inference.”Epidemiology (Cambridge, Mass). 1:421–429. doi: 10.1097/00001648-199011000-00003.
33. Greenland S, Senn SJ, Rothman KJ, Carlin JB, Poole C, Goodman SN, et al. (2016). “Statistical tests, P values, confidence intervals, and power: A guide to misinterpretations.”European journal of epidemiology. 31:337–350. doi: 10.1007/s10654-016-0149-3.
34. Greenland S, Pearl J, Robins J. (1999). “Causal Diagrams for EpidemiologicResearch.”Epidemiology (Cambridge, Mass). 10:37–48.
35. VanderWeele TJ. (2019). “Principles of confounder selection.”European journal of epidemiology. 34:211–219. doi: 10.1007/s10654-019-00494-6.
36. Young SS, Karr A. (2011). “Deming, data and observational studies.”Significance. 8:116–120. doi: 10.1111/j.1740-9713.2011.00506.x.
38. Steegen S, Tuerlinckx F, Gelman A, Vanpaemel W. (2016). “Increasing TransparencyThrough a MultiverseAnalysis.”Perspectives On Psychological Science. 11:702–712. doi: 10.1177/1745691616658637.
40. Greenland S. (2000). “Principles of multilevel modelling.”International journal of epidemiology. 29:158–167. doi: 10.1093/ije/29.1.158.
41. Trepanowski JF, Ioannidis JPA. (2018). “Perspective: LimitingDependence on NonrandomizedStudies and ImprovingRandomizedTrials in HumanNutritionResearch: Why and How.”Advances in nutrition (Bethesda, Md). 9:367–377. doi: 10.1093/advances/nmy014.
This website uses cookies. By continuing to read, you accept the use of cookies.
Source Code
---title: "How Useful Is Nutritional Epidemiology?"bibliography: references.bibdescription: The studies that gain the most attention from the media are usually nutritional epidemiological studies. However, there is a good reason to be skeptical of these types of studies and in this blog post, I explain why.image: https://res.cloudinary.com/less-likely/image/upload/f_auto,q_auto/v1565843242/Site/cookbook.svglastmod: '2019-08-14'zotero: trueog_image: https://res.cloudinary.com/less-likely/image/upload/f_auto,q_auto/v1565843242/Site/cookbook.svgslug: nutritional-epidemiologytags:- causality- epidemiology- multiplicityurl: nutrition/nutritional-epidemiologycategories: [nutrition]format: html: toc: true df-print: kable---Nutritional epidemiology studies the relationship between diet and disease, and like many other epidemiological disciplines, it hopes to develop interventions and policies that will improve the health of the public. The field has had some success in the past by observing certain associations and implementing public health interventions that lead to large effects, as shown by the following findings:------------------------------------------------------------------------| Observational Findings | Health Interventions ||--------------------------------|----------------------------------------|| Linking folate deficiency to a higher risk of neural tube defects.[@hibbard1964jogbc; @hibbard1965tl]| Fortification of foods with folate.[@honein2001j]|| Linking the consumption of trans fats to a higher risk of cardiovascular disease.[@willett1994ajph]| FDA limits/bans the production of foods with trans fats.[@dewey2018wp]|| Linking high fish consumption to longer pregnancies.[@leventakou2014ajcn]| Cochrane concludes strong evidence that omega-3 supplementation is effective for reducing risk of preterm birth.[@middleton2018cdsr]|------------------------------------------------------------------------However, these sorts of occurences have been rare and unfortunately, the field continues to publish several studies every year that have lead to little progress in nutrition research. Despite this, nutritional epidemiological researchers will often overexaggerate their findings during press releases and the media *loves* covering these sorts of studies.------------------------------------------------------------------------<img src="https://res.cloudinary.com/less-likely/image/upload/f_auto,q_auto/v1554700132/Site/media_eggs.png" alt="The media response to the publication of the JAMA egg study"/>------------------------------------------------------------------------This is one of my favorite ones.------------------------------------------------------------------------<img src="https://res.cloudinary.com/less-likely/image/upload/f_auto,q_auto/v1554700113/Site/eggs_media_reporting.png" alt="Fear mongering headlines about eggs"/>------------------------------------------------------------------------This has lead to severe criticism of the field, with the leading meta researcher in the world [exclaiming],[exclaiming]: "http://www.cbc.ca/news/health/second-opinion-alcohol180505-1.4648331"> “Nutritional Epidemiology is a scandal. It should just go to the waste bin.” - John IoannidisIn one [meta-study],[@schoenfeld2013ajcn] Ioannidis showed that several random food ingredients from a cookbook had large associations with cancers, as shown below. Some of these effects were simply implausible.[meta-study]: https://academic.oup.com/ajcn/article/97/1/127/4576988------------------------------------------------------------------------<figure><img src="https://res.cloudinary.com/less-likely/image/upload/v1565843242/Site/cookbook.svg" alt="Many nutritional epidemiological findings showing that all foods are associated with an increased or decreased risk of cancer"/><figcaption>Schoenfeld JD, Ioannidis JP. Is everything we eat associated with cancer? A systematic cookbook review. The American Journal of Clinical Nutrition. 2013;97(1):127-134. doi:10.3945/ajcn.112.047142</figcaption></figure>------------------------------------------------------------------------However, when several of the studies were pooled in meta-analyses, these large effects shrunk as shown below.------------------------------------------------------------------------<figure><img src="https://res.cloudinary.com/less-likely/image/upload/f_auto,q_auto/v1554700126/Site/IndividualvsMeta.gif" alt="Meta-analyses of nutrition studies shrink the large effects"/><figcaption>Schoenfeld JD, Ioannidis JP. Is everything we eat associated with cancer? A systematic cookbook review. The American Journal of Clinical Nutrition. 2013;97(1):127-134. doi:10.3945/ajcn.112.047142</figcaption></figure>------------------------------------------------------------------------Defenders of nutritional epidemiology will often exclaim that the purpose of the field is to produce studies that "generate hypotheses," that other researchers can follow up on with randomized trials.However, this argument holds little merit, given that many of the associations that are found are never followed up on, are simply implausible (with little background biology to support them), lead to wasted resources when they are followed up on,[@pittas2019nejm] and are used to argue for policy changes without any confirmation by clinical trials or research syntheses.[@prasad2013jce]Cole (1993)[@cole1993e] elegantly addressess these points in the "The Hypothesis Generating Machine",> On the other hand, nearly all of the hypotheses that are said to be generated by a study are unworthy of the name: **they are seen only once, they are usually weak, and many are contradicted by data**...>> What is **relevant is the credibility of the hypothesis**. This credibility is to be **assessed by a review of all available knowledge within a frameowrk of reasonable criteria of causality**. Thus, complex notions of generating, testing, accepting, and rejecting can be abandoned...>> It occurred to me that it is unnecessary and unproductive to wait for future studies to generate hypotheses. After all, **there is a boundless number of hypotheses that could be generated, nearly all of them wrong**. Therefore, if we are going to get anywhere at all with this approach, we should go about it systemtically and rapidly.Cole's fears have turned out to be true. There are dozens, if not hundreds, of nutritional epidemiological studies that are published every year, and few of them have lead to any substantial gains in knowledge.Concordance with randomized clinical trials (often considered one of the most efficient ways to causally determine treatment effects) has also been poor. This can be seen with contradictions between observational studies and RCTs about Vitamin D,[@barbarawi2019jc] Vitamin C, Vitamin E,[@lawlor2004tl] beta carotene,[@druesne-pecollo2010ijc] and fish oil[@abdelhamid2018cdsr].------------------------------------------------------------------------This article will explore why nutritional epidemiology has largely failed to produce much useful knowledge and offer some practical recommendations along the way for researchers in this domain (make no mistake, this article is also written for the average person interested in this topic).The initial focus will be on measurement error, something that plagues not only nutritional epidemiological studies, but also randomized controlled trials that are not tightly monitored (such as metabolic ward studies).------------------------------------------------------------------------# Measurement Error------------------------------------------------------------------------Traditionally, researchers have attempted to measure the composition of an individual's diet via three methods, food frequency questionnaires, 24-hour food recalls, and dietary food records. All of these methods rely on the participant's memory, making them heavily prone to systematic errors, such as classical measurement error $W_{ij}=X_{i}+ \epsilon_{ij}$.Food frequency questionnaires (FFQ) (first pioneered in the 1960s[@heady1961jrsssg]) attempt to assess how often an individual eats certain amounts of foods. These methods are widely used because they are cheap, easy to collect, and provide researchers with information about long-term dietary habits. There are even parody videos about them, such as the one below.------------------------------------------------------------------------<center><iframe src="https://www.facebook.com/plugins/video.php?href=https%3A%2F%2Fwww.facebook.com%2Ffivethirtyeight%2Fvideos%2F1038072956236533%2F&width=300&show_text=false&height=168&appId" width="300" height="168" style="border:none;overflow:hidden" scrolling="no" frameborder="0" allowTransparency="true" allow="encrypted-media" allowFullScreen="true"></iframe></center>------------------------------------------------------------------------24-hour food recalls are the most widely used method to assess dietary intake and involve interviewers spending 15-20 minutes asking participants what they ate in the last 24 hours. While this method may seem more reliable than the FFQ, metabolic ward studies[@karvetti1985jada; @madden1976jada] have shown that even in 24-hour recalls, participants often erroneously reported eating foods that were not eaten or omitted those that were.Food diaries are also used to assess dietary habits, however, they are limited because they rely on the individual accurately weighing and reporting food intake during every meal for several days. This puts a lot more burden on the participant than the other methods, making them less likely to properly report food intake. This method is the least widely used and much less is known about its systematic errors (yes, food diaries also suffer from bias!).The measurement error that results from using these methods is well known, however, another issue that is less discussed is the disregarding of the effects of individual foods. Since most of these methods attempt to compute nutrient intake and conflate nutrient composition with the food itself, valuable information is discarded. For example, milk and yogurt are known to have similar nutrient profiles, yet, they have different physiological effects,[@mertz1984jadau] but in a typical nutritional epidemiological study, they will likely be treated as the same due to similar nutrient profiles.Greenland (2010)[@greenland2010ss] writes,> As an example, in nearly all observational studies of nutrient effects, individual risks are regressed directly on nutrient intakes calculated from food intakes. **This conventional model makes no further use of the food intakes, and so assumes implicitly that foods have no effect on risk beyond their calculated nutrient content.**>> **This is an unsupported and very doubtful assumption. A more realistic model allows food effects beyond measured-nutrient content.** However, the resulting two-level hierarchical model is not identified without a prior because nutrient intakes are linear functions of food intakes (making nutrient and food intakes completely collinear).>> Using any contextually defensible prior reveals that the conventional analysis generates overconfident inferences, both in the Bayesian sense of overstating information (Greenland, 2000), and also in the frequentist sense of producing interval undercoverage (Gustafson and Greenland, 2006). **That overconfidence may explain the rather embarrassing track record of nutritional epidemiology when compared against clinical trials (Lawlor et al., 2004).**With all this, and more, in mind, some researchers[@archer2018joce] have argued the following about the current methods used to assess food intake:> 1. The use of memory-based methods is founded upon two inter-related logical fallacies: a **category error** and **reification**>> 2. **Human memory and recall are not valid instruments** for scientific data collection>> 3. The **measurement errors of memory-based dietary assessment methods** are **neither quantifiable nor falsifiable**; this renders these methods and data pseudoscientific>> 4. The post hoc **process of pseudoquantification is impermissible and invalid**>> 5. **Memory-based dietary data** were repeatedly **demonstrated to be physiologically implausible** (i.e., meaningless numbers)>> 6. The **failure to cite** or acknowledge **contrary evidence** and empirical refutations **contributed to a fictional discourse** on diet-disease relations> Our conclusion is that nutrition epidemiology is a degenerating research paradigm in which the use of expedient but **nonfalsifiable anecdotal evidence impeded scientific progress** and engendered a fictional discourse on diet-health relations. The continued funding and use of memory-based methods such as Food Frequency Questionnaires and 24-hour dietary interviews is anathema to evidence-based public policy.>> Thus, our recommendation is simply that **the use of memory-based methods must stop and all previous articles presenting memory-based methods data and conclusions must be corrected** to include contrary evidence and address the consequences of a half century of pseudoscientific claims.However, many other researchers[@subar2015jn] have pointed out errors in the analysis by the author of that excerpt (Archer et al) and believe that Archer et al overstates the evidence against FFQ data.[@subar2015jn]Subar et al, 2015[@subar2015jn] counter with the following,> Measurement error is inherent in all types of data. **The errors in self-report dietary intake data are well documented.** On the basis of current knowledge, **we recommend that investigators:**>> 1. **continue to collect self-report dietary intake data** because they contain valuable, rich, and critical information about foods and beverages consumed by populations that can be used to inform nutrition policy and assess diet-disease associations;>> 2. **not use self-reported EI as a measure of EI;**>> 3. use self-reported EI for energy adjustment of other self reported dietary constituents to improve risk estimation in studies of diet-health associations;>> 4. **acknowledge the limitations of self-report dietary data** and analyze and interpret them appropriately;>> 5. design studies and **conduct analyses that allow adjustment for measurement error;**>> 6. design new epidemiologic studies to **collect dietary data from both short-term (24HRs or FRs) and long-term (FFQs) instruments** on the entire study population to allow for maximizing the strengths of each instrument; and>> 7. continue to develop, evaluate, and further expand methods of dietary assessment, including dietary biomarkers and methods using new technologies.>> Self-report dietary data provide information on food intake, food behaviors, and eating patterns that is not possible to obtain from a comprehensive set of biomarkers. To guide people in how to eat more healthfully, asking them what they are currently eating is imperative and **should not be abandoned**.Thus, it seems prudent to supplement these measurements with each other (if possible) and with other methods such as surrogate biomarkers, as outlined by Keogh, White, & Rodwell, 2013.[@keogh2013sim]> **The use of surrogate biomarkers allows us to relax the assumptions that errors in FFQs and food records are independent and that errors in repeated measurements using the same instrument are independent,** which in the past have been made in validation studies involving only FFQ and diet diary.>> However, this comes at the price of assuming that errors in surrogate biomarker measurements are independent of errors in self‐reported measurements conditional on covariates, and an inability to estimate the correlation between errors in repeated surrogate biomarker measurement, ρMM.>> In the illustration of the model, we showed that different assumptions about the values of these parameters can result in RDRs covering a wide range. This is an important result; **it suggests that we should be highly sceptical about results obtained under the usual assumptions and cautious to draw firm conclusions about the degree of error in self‐reported measurements unless more information can be obtained about the relationship between the surrogate biomarker in question and true intake.**Keogh & White, 2014[@keogh2014sm] also provide recommendations on how to account for these issues in the analysis phase via methods such as regression calibration, moment reconstruction, multiple imputation, and graphical methods, along with sensitivity analyses.> **We emphasized the use of RC to make corrections for measurement error**, this being the most popular approach in practice. We also showed how RC can be extended to incorporate sensitivity analyses to investigate the potential impact of departures from classical error on corrected estimates of exposure-outcome associations.>> **The use of sensitivity analyses such as these is important in nutritional epidemiology, where there is evidence of systematic errors in dietary measurements,** but few unbiased measures with which to make comparisons. If a validation study is available, in which the true exposure is observed, then no sensitivity analyses are necessary.While this section has now concluded on the very complicated issue of measurement error, the next issue is just as, if not more, complicated and involves confounding and multiplicity.------------------------------------------------------------------------# Confounding and Multiplicity------------------------------------------------------------------------The reason that randomized controlled trials are so efficient in estimating causal treatment effects is because they randomly distribute covariates and reduce systematic variation and selection bias.[@Kempthorne1977-ge; @Zhao2018-yf]In epidemiological studies, such as in nutritional epidemiology, researchers often use a variety of methods such as statistical adjustments, matching/propensity scores, and several other sophisticated methods to make groups as comparable as possible.So one of the biggest issues that remains is what covariates should be included in a statistical model for adjustment? Typically, many researchers will use stepwise methods such as backward selection, where they include all covariates that are available to them in the model, and delete those with the largest P-values.Another stepwise approach typically used is forward selection, where researchers will start with no predictors and add covariate by covariate, including only those that result in highly significant results.There are numerous problems with these approaches[@hurvich1990as; @lewis-beck1978pm; @livingston2010as; @steyerberg1999jce; @thompson1995eapm] and they result in biased overestimates and abuse both P-values and a decision making paradigm that was intended for quality inspection. Again, nutritional epidemiological studies are observational and most of the exposures are not random (an assumption often assumed to be true when computing P-values).[@greenland1990e; @greenland2016eje]Greenland summarizes this issue with clarity in his 1990 paper published in *Epidemiology*.[@greenland1990e]> **Randomization provides the key link between inferential statistics and causal parameters**. Inferential statistics, such as **P values**, **confidence intervals**, and **likelihood ratios**, **have very limited meaning in causal analysis** when the mechanism of exposure assignment is **largely unknown or is known to be nonrandom**. It is my impression that such statistics are often given a weight of authority appropriate only in randomized studiesVariable selection in statistical modeling is a very complex subject, however, one method that may aid a researcher involves consulting subject-matter experts and drawing out all knowledge/assumptions using directed acyclical graphs[@greenland1999e], commonly referred to as DAGs.This may aid researchers in knowing what to adjust for in a statistical model, while avoiding adjusting for things that may result in biased, spurious associations, such as collider bias (shown below).<figure><img src="https://res.cloudinary.com/less-likely/image/upload/v1565843859/Site/collider.svg"/><figcaption>VanderWeele TJ. Principles of confounder selection. European Journal of Epidemiology. 2019;34(3):211-219. doi:10.1007/s10654-019-00494-6</figcaption></figure>Some epidemiologists[@vanderweele2019eje] have recommended utilizing the "disjunctive cause criterion" for selecting covariates to adjust for. In this framework, covariates that are known to cause the exposure or the outcome are included in the model.While these methods are a large improvement over mindless inclusion of variables within a model, the issue remains, diets are linked to *nearly everything* (making confounding a really tough problem to deal with), effects tend to be small, and it is easy to shift these effects based on inclusion or deletion of a few covariates.The statistician Stan Young pointed out how this flexibility could be problematic in the journal *Significance*.[@young2011s]> For example, consider the use of linear regression to adjust the risk levels of two treatments to the same background level of risk. There can be many covariates, and each set of covariates can be in or out of the model. With ten covariates, there are over 1000 possible models. Consider a maze as a metaphor for modelling (Figure 3).>> <figure><img src="https://res.cloudinary.com/less-likely/image/upload/f_auto,q_auto/v1554700169/Site/young_maze.png" alt="Analytical flexibility depicted by attempting to get through a maze" style="width:60%"/></figure>>> The red line traces the correct path out of the maze. The path through the maze looks simple, once it is known. Returning to a linear regression model, terms can be put into and taken out of a regression model. Once you get a p‐value smaller than 0.05, the model can be frozen and the model selection justified after the fact. It is easy to justify each turn.In a similar [meta-study][1],[@Patel2015-kk] titled “Assessment of vibration of effects due to model specification can demonstrate the instability of observational associations”, John Ioannidis showed that by using different combinations of a certain number of covariates, you could virtually make effects go in either direction (type S (sign) errors) or change their magnitude (type M errors).[@Patel2015-kk][1]: https://www.ncbi.nlm.nih.gov/pubmed/26279400In the study, Ioannidis downloaded 13 variables from the NHANES dataset that were linked to all-cause mortality, and that had a substantial number of participants associated with each variable (at least 1000 participants and 100 deaths).From those 13 variables, he was able to produce **8,192** different statistical models that all resulted in different hazard ratios (HR), as seen in the image below. The variables were included age, smoking, BMI, hypertension, diabetes, cholesterol, alcohol consumption, education, income, sex, family history of heart disease, heart disease, and any cancer.------------------------------------------------------------------------<figure><img src="https://res.cloudinary.com/less-likely/image/upload/f_auto,q_auto/v1554700112/Site/effectclouds.jpg" alt="The vibration of effects, depicting how much analytical flexibility there is with covariate choice in model building and selection"/><figcaption>Patel CJ, Burford B, Ioannidis JPA. Assessment of vibration of effects due to model specification can demonstrate the instability of observational associations. J Clin Epidemiol. 2015;68(9):1046-1058.</figcaption></figure>------------------------------------------------------------------------For one particular relationship between vitamin D and all-cause mortality, Ioannidis reported that with *no adjustment* of covariates, Vitamin D resulted in an impressive 0.64 HR. A 36% decrease. However, when all 13 covariates are included in the model, the HR increases to 0.75.Ioannidis and Patel recommended reporting all possible statistical models from all possible combinations of covariates and to report the median of all these models, rather than selectively reporting a few models. And to note whether there was something called a *"Janus effect"*, where the effect size would go in both directions.> In the last pattern, as exemplified by **α-tocopherol**, the estimated HRs can be both greater and less than the null value (HR \> 1 and HR ≤ 1) depending on what adjustments were made. **We call this the Janus effect after the two-headed representation of the ancient Roman god.**>> For α-tocopherol, most of the HR and p-values were concentrated around 1 and non-significance, respectively... **The Janus effect is common**: 131 (31%) of the 417 variables had their 99th percentile HR\>1 and their 1st percentile HR \< 1.However, statistician/epidemiologist, Sander Greenland has been a [critic of meta-research] and epidemiological studies that lack biochemical sophistication and lump several compounds together as if they were the same and behaved the same in the body.[critic of meta-research]: /uploads/SanderGreenland.pdf> "For nutrition, **the lack of biochemistry sophistication among the trial designers leads to a lot of dubious and noncomparable studies**, while the meta-analysts and reviewers do a lot of **distortive lumping**, e.g., talking about “vitamin E” as if that were a **single entity**.>> A recent review by prominent authors didn’t even notice that almost **all trials used the racemic synthetic mixture, dl-alpha-tocopheryl, (which they misidentify with “alpha tocopherol”)** with vastly diferent and unjustifed dosages, and **which hardly resembles the eight or so natural d-tocopherols or d-tocotrienols that account for dietary intake.**"[@Patel2015-kk]------------------------------------------------------------------------A reasonable way to address the issue of model selection seems to be using sensitivity analyses and multiverse analyses[@steegen2016pps] to see all possible variations, whilst using hierarchical modeling and shrinkage estimators[@efron1977sa; @greenland2000ije] (shown below) to partially pool results towards zero.------------------------------------------------------------------------<figure><img src="https://res.cloudinary.com/less-likely/image/upload/v1565815950/Site/shrinkage.gif"/><figcaption>Taken from Clark (2019, May 18). Michael Clark: Shrinkage in Mixed Effects Models. Retrieved from https://m-clark.github.io/posts/2019-05-14-shrinkage-in-mixed-models/</figcaption></figure>------------------------------------------------------------------------# Poor Concordance with Randomized Trials------------------------------------------------------------------------Another common criticism is that the findings of nutritional epidemiological studies are rarely corroborated by randomized trials, which is well known from studies of Vitamin D,[@barbarawi2019jc] Vitamin C, Vitamin E,[@lawlor2004tl] beta carotene,[@druesne-pecollo2010ijc] and fish oil[@abdelhamid2018cdsr]. In 2011[@young2011s], the statistician Stan Young decided to assess what concordance was like between observational studies and randomized clinical trials. Young writes,> We ourselves carried out an informal but comprehensive accounting of 12 randomised clinical trials that tested observational claims – see Table 1. **The 12 clinical trials tested 52 observational claims. They all confirmed no claims in the direction of the observational claims**. We repeat that figure: **0 out of 52**. To put it another way, **100% of the observational claims failed to replicate**.>> In fact, **five claims (9.6%) are statistically significant in the clinical trials in the opposite direction** to the observational claim. To us, a false discovery rate of over 80% is potent evidence that the observational study process is not in control. The problem, which has been recognised at least since 1988, is systemic.However, there are some issues with these particular conclusions.1. The randomized trials are nowhere near as large as the observational studies, therefore it is likely that the designs were too small to detect an effect of interest and reject the null hypothesis. Thus, focusing on statistical significance makes little sense.2. In observational studies, there often is no random mechanism such as random assignment or random sampling, thus, putting significant weight on a decision theoretic like statistical significance is rarely justified.[@Greenland1990-ay].In the same paper,[@Greenland1990-ay] Greenland also points out the problems with several probabilistic arguments that are used to justify classical statistics in areas where the exposure is unknown or unlikely to be random. He proposes some possible solutions:> In causal analysis of observational data, valid use of inferential statistics as measures of compatibility, conflict, or support depends crucially on randomization assumptions about which we are at best agnostic and more usually doubtful. Among the possible remedies are:>> - Restrain our interpretation of classical statistics by explicating and **criticizing any randomization assumptions** that are necessary for probabilistic interpretations;> - train our students and retrain ourselves to **focus on nonprobabilistic interpretations** of inferential statistics;> - **deemphasize inferential statistics** in favor of **pure data descriptors, such as graphs and tables**;> - expand our analytic repertoire to include more elaborate techniques that depend on **assumptions in the "agnostic"** rather than the "doubtful" realm, and **subject the results of these techniques to influence and sensitivity analysis.**>> These are neither mutually exclusive nor exhaustive possibilities, but I think any one of them would constitute an improvement over much of what we have done in the past.------------------------------------------------------------------------As we can see, there are plenty of issues with nutritional epidemiology as its currently done. Some, like Trepanowski & Ioannidis[@trepanowski2018an] believe that the field should stop producing studies altogether and that randomized studies should be the focus of nutrition research with a focus on how to overcome common issues faced by RCTs.> The aforementioned epistemologic problems cannot be overcome with the research designs that are currently used in nutrition science. **Nonrandomized observational research simply involves too much confounding.**>> It is also **more vulnerable to publication and selective-outcome reporting biases (47) compared with randomized research**, because it is more difficult to ascertain how many observational data sets are available worldwide that can address a given exposure-outcome relation (48).>> Although some epidemiologists register their analysis protocols, this is **falsely reassuring because it can easily be done after peeking at the relevant data surreptitiously**.However, the reality is that nonrandomized studies will often be needed when randomized studies are simply not possible and nonrandomized studies are not going anywhere. Thus, a great deal of effort should be placed into improving nutritional epidemiological research to make it more useful.------------------------------------------------------------------------## References




Comments