What Makes a Sensitivity Analysis?
The Rise of Crony Statistical Rituals
statistics
Sensitivity analyses are an important part of statistical analyses, however, there are major misconceptions about what they do and what qualifies as such an analysis.

Keywords
statistical science, statistical reporting, statistical workflow, sample sizes, data management, sensitivity analysis
Cargo-Cult Uncertainty
Sensitivity analyses are an important part of statistical science and many other disciplines when conducted in a principle and systematic manner. However, in the published sensitivity analyses literature, there are many inconsistencies, misconceptions, and highly misleading findings from these analyses. A giant obstacle that prevents these issues from recurring is that they (sensitivity analysis techniques) are quite difficult to learn and often advanced statistical methods that even many statisticians have difficulty with.
Yet, the appearance of difficulty does not dissuade certain researchers away from adopting them for their own work, (so that they may give their colleagues and their stakeholders that they report to, the impression of rigor and methodological expertise), and when this is done mindlessly, researchers will often skip over learning the details and theory, and like many statistical procedures, they will rely on default settings built in the statistical software.
While there are many suites/commands/functions/libraries available to conduct such analyses, much of these procedures masquerade as meticulous sensitivity analyses and to the users, are often a formality to appease stakeholders and give researchers a false sense of confidence about what they are doing. And yet, their users have little to no idea what they’re actually doing. Thus, like many statistical procedures new and old, they too will inevitably be abused as they become more popular and as they are required in research reports.
As Stark & Saltelli1, along with many others such as Gigerenzer2 and Greenland3 have written in the past. Below is an excerpt where Stark describes that much of statistics is simply people masquerading as data analysts and being rewarded as experts despite not having a single clue what they’re doing.
In our experience, many applications of statistics are cargo-cult statistics: practitioners go through the motions of fitting models, computing p-values or confidence intervals, or simulating posterior distributions. They invoke statistical terms and procedures as incantations, with scant understanding of the assumptions or relevance of the calculations, or even the meaning of the terminology. This demotes statistics from a way of thinking about evidence and avoiding self-deception to a formal “blessing” of claims. The effectiveness of cargo-cult statistics is predictably uneven. But it is effective at getting weak work published - and is even required by some journals…
Here, Stark takes on the issue of widely accessible statistical software for academics, students, and analysts.
Statistical software does not help you know what to compute, nor how to interpret the result. It does not offer to explain the assumptions behind methods, nor does it flag delicate or dubious assumptions. It does not warn you about multiplicity or p-hacking. It does not check whether you picked the hypothesis or analysis after looking at the data, nor track the number of analyses you tried before arriving at the one you sought to publish - another form of multiplicity. The more “powerful” and “user-friendly” the software is, the more it invites cargo-cult statistics.1
Greenland3 focuses on how traditional statistical education is inadequate to deal with the messy and chaotic nature of the world and the missing data that is produced by it. Greenland writes that traditional statistical practice opens the room for several cognitive biases, making many reports and conclusions highly misleading. He provides some hope however, by pointing to the utility of sensitivity analyses for modeling bias and uncertainty.
I argue that current training in statistics and analytical methods is inadequate for addressing major sources of inference distortion, and that it should be expanded to cover the biased perceptual and thinking processes (cognitive biases) that plague research reports. As commonly misused, null-hypothesis significance testing (NHST) combines several cognitive problems to create highly distorted interpretations of study results. Interval estimation has proven highly vulnerable to the same problems. Sensitivity and bias analyses address model uncertainties by varying and relaxing assumptions, but (like Bayesian analyses) they are difficult to perform with proper accounting for prior information and are easily manipulated because they depend on specification of many models and parameters.
However, he then follows up to discuss how difficult sensitivity and bias analyses can be due to the plethora of decisions that the analyst must make when specifying parameters in the analysis. These judgements will differ from researcher to researcher, even in the same group, and such analyses have not been studied as widely as conventional statistical practice.
Even with realistic choices, the sensitivity of sensitivity and bias analyses must be evaluated (51). The plausibility of an estimated bias function is determined by intuitions, prejudices, and understanding of the applied context; those can vary dramatically across researchers, in turn leading to very different specifications and inferences even if they are anchored to the same conventional analysis. Adding to this problem, sensitivity and bias analyses are more difficult to perform correctly and more easily massaged toward preferred conclusions, because they require specification of many more equations and their parameters.
And unlike NHST, abuse of sensitivity and bias analysis is as yet barely studied because the pool of such analyses remains small and highly selective. It thus seems implausible that these analyses will increase replicability of inferences, although they can reveal how assumptions affect those inferences. (Here “replicability” is used according to recommendations of the American Statistical Association (52) to denote independent checks of reported results with new data; “reproducibility” then denotes checks of reported results using the original data and computer code.)
Indeed, this is one drawback of (relatively) newly adopted methods/procedures, they have not been studied long enough as say somethng such as a P-value, which has been studied for centuries. Even something as useful as exploring assumptions and uncertainty such as a principled sensitivity analysis is not free from this.
it seems Greenland’s predictions were accurate; in a large systematic review of published sensitivity analyses led by the mathematician Andrea Saltelli and his group, they found that highly cited papers in top impact factor journals rarely contained sensitivity analyses, and that many of these were poorly done and one-dimensional, in the sense of only varying one parameter at a time, which is hardly informative as a multi-dimensional analysis in which multiple parameters are varied at the same time.
Here, we will explore one example of how mindless sensitivity analyses are conducted within the context of clinical trials, although we will not explore multi-dimensional sensitivity analyses here. I make this distinction because the environment to conduct sensitivity/bias analyses differs substantially in trials where regulators are involved versus the environment in which many observational studies are analyzed and presented.
In medicine, sensitivity analyses (SA) are often conducted in trials and observational studies, but again, little thought is given to what they should entail.1 None of this is surprising given that they are not usually taught in traditional settings, although they have been discussed extensively within the statistical and epidemiological literature4–10 Yet, the other barrier that remains is that they are incredibly technical and will require the assistance of an analyst familiar with both the theory and the applications. It also does not help that the topic is vast and there are multiple new statistical methods being published every day.
Indeed, the Handbook of Missing Data Methodology,11 one of the most authoritative and comprehensive books to date on statistical methods to handle missing data in clinical trials, has nearly six chapters devoted to the topic of sensitivity analyses and different approaches to use. Unfortunately, at the rate that this field is advancing, this book may already be outdated, despite only coming out six years ago.
This article will focus on what a sensitivity analysis is often assumed to be based on practices in the literature, some differing points of view regarding sensitivity analyses (with an example of a highly promoted measure for conducting sensitivity analyses that has been very controversial, and a practical example of conducting principled(by principled, I mean non ad-hoc techniques, as James Carpenter would say) sensitivity analyses in the context of missing data in a randomized clinical trial.
Everything is Sensitive
Before we move forward, we must consider what a sensitivity analysis actually entails. The first word of the phrase is an obvious tell, it suggests an analysis that examines how sensitive or robust a result is. But a natural question is, sensitive specifically to what? What sort of perturbations and how relevant are they? Can I vary anything in the analysis to test the sensitivity of the result or assumption? For example, if I obtained an odds ratio of 1.7 from the primary analysis in my experiment and I conducted an extra analysis to see whether the odds ratio would change by a resampling method, is that a sensitivity analysis?
What if I did a completely different type of analysis, for example, suppose the primary analysis was a classical statistical test with an adjustment for multiple comparisons and I decided to run a hierarchical Bayesian regression with a spiked prior on the null, would that be a sensitivity analysis, given they are different frameworks and procedures (although being used for similar goals)? The possibilities of what can be varied are endless when a loose definition of sensitivity analysis is assumed. This is unique to every discipline and their culture. In epidemiology, sensitivity analyses and bias analyses which attempt to extensively explore assumptions and the robustness of the result are used synonymously, yet in the clinical trial world, this is not the case.
Frequent Misconceptions
Take for example in clinical trials and observational studies, in particular, it is common to see primary analyses often being intent-to-treat (ITT) analyses and sensitivity analyses being per-protocol analyses (PP).
I will not define these terms here and would encourage readers to consult other sources.
The following is a similar example from a high-profile trial published in the The Lancet in 2002,12
The Multicentre Aneurysm Screening Study group randomised 67,800 men to receive an invitation to an abdominal ultrasound scan or not [6]. Of those invited to receive an abdominal scan, 20% did not accept. The primary analysis was by intention to treat, thus estimating the effect of being randomised to abdominal ultrasound. Another analysis investigated the complier average causal effect, which considers what the (average) effect of treatment was in patients who would have adhered to protocol however they were randomised [7].
To many, this may seem perfectly fine, even great. The authors used the question they were primarily interested in as the main analysis, and then conducted an additional analysis to see if these results are consistent. Unfortunately, this is highly problematic as Morris et al. (2014)13 describes
These questions are different, and observing different results should not shake our confidence in either. The CACE analysis was a secondary analysis, not a sensitivity analysis.
It is common for authors to compare the results of intention-to-treat with per-protocol analysis; see for example [8, 9]. While it is hard to pin down the precise question of per-protocol analysis [10], this is clearly different to the question intention-to-treat addresses. Per-protocol analysis should not therefore be considered as a sensitivity analysis for intention-to-treat but as a secondary analysis, if at all.
Randomness & Uncertainty
Portable Sensitivity Analyses
These sorts of misunderstandings are so common and so prevalent throughout the literature, so it should come as no surprise that sensitivity analyses are rarely done, or they are done incorrectly. Although not in clinical trials, one particular controversial example has been the promotion and use of the \(E\)-value (the ‘E’ apparently stands for ‘evidence’, but I am not sure.) within epidemiology to assess the amount of confounding necessary within an observational study result to practically reduce the effect estimate to something that is practically null.
The method and value has been adopted with open arms by many epidemiologists and health researchers given that it has simplified a task that is often arduous and requires extensive and careful thought in comparison to the traditional classical analysis. Yet, others have also been highly critical of it for a number of reasons, and although they see the value in promoting sensitivity analyses to more researchers around the world, many are concerned that this measure will also eventually go down the road of P-values, but for observational research.
Regulators & Sensitivity Analyses
As mentioned above, there are many possible ways to conduct a sensitivity analysis, especially if the phrase is used in a loose/vague way. Whether or not these are valid and principled approaches to conducting sensitivity analyses is another question. Luckily, many of us do not have to ponder day and night about the semantics about this because both The Handbook of Missing Data Methodology and the International Council for Harmonisation of Technical Requirements for Pharmaceuticals for Human Use (ICH) have given this topic much thought, and for the latter it is reflected by the fact that they recently created an entire new addition to their E9 guidance document (Statistical Principles for Clinical Trials) which has served as a reference for clinical trial statisticians for decades. In the addendum, titled Addendum on Estimands and Sensitivity Analysis In Clinical Trials, which has now been legally adopted by regulatory agencies around the world including the FDA and EMA, they elaborate on the concept of estimands and the role sensitivity analyses play.
To be clear, estimands are not new and have been discussed in the statistical literature since Tukey14 but the ICH working group’s addendum formalized its adoption in the clinical trial world and the importance of sensitivity analyses.15–17
Estimands & Sensitivity
A.5.2.1. Role of Sensitivity Analysis
Inferences based on a particular estimand should be robust to limitations in the data and deviations from the assumptions used in the statisticral model for the main estimator. This robustness is evaluated through a sensitivity analysis. Sensitivity analysis should be planned for the main estimators of all estimands that will be important for regulatory decision making and labelling in the product information. This can be a topic for discussion and agreement between sponsor and regulator.
The statistical assumptions that underpin the main estimator should be documented. One or more analyses, focused on the same estimand, should then be pre-specified to investigate these assumptions with the objective of verifying whether or not the estimate derived from the main estimator is robust to departures from its assumptions. This might be characterised as the extent of departures from assumptions that change the interpretation of the results in terms of their statistical or clinical significance (e.g. tipping point analysis).
Distinct from sensitivity analysis, where investigations are conducted with the intent of exploring robustness of departures from assumptions, other analyses that are conducted in order to more fully investigate and understand the trial data can be termed “supplementary analysis” (see Glossary; A.5.3.). Where the primary estimand(s) of interest is agreed between sponsor and regulator, the main estimator is pre-specified unambiguously, and the sensitivity analysis verifies that the estimate derived is reliable for interpretation, supplementary analyses should generally be given lower priority in assessment.
A.5.2.2. Choice of Sensitivity Analysis
When planning and conducting a sensitivity analysis, altering multiple aspects of the main analysis simultaneously can make it challenging to identify which assumptions, if any, are responsible for any potential differences seen. It is therefore desirable to adopt a structured approach, specifying the changes in assumptions that underlie the alternative analyses, rather than simply comparing the results of different analyses based on different sets of assumptions. The need for analyses varying multiple assumptions simultaneously should then be considered on a case by case basis. A distinction between testable and untestable assumptions may be useful when assessing the interpretation and relevance of different analyses.
ICH E9 (R1) Guideline
The need for sensitivity analysis in respect of missing data is established and retains its importance in this framework. Missing data should be defined and considered in respect of a particular estimand (see A.4.). The distinction between data that are missing in respect of a specific estimand and data that are not directly relevant to a specific estimand gives rise to separate sets of assumptions to be examined in sensitivity analysis.
they explicitly define a sensitivity analysis as being an analysis which:
- realistically varies the assumptions from the primary analysis
- still targets the same estimand
- examines the robustness of the results to
- assumption violations or departures
- can possibly change the results/conclusions drawn
They contrast this with more extensive analyses that investigate these violations/departures of assumptions, and characterize those analyse as being supplementary rather than sensitivity. The latter is typically what is seen in rigorous epidemiological studies that employ quantitative bias analyses (a more specialized form of sensitivity analysis).
The ICH E9 addendum contains similar views that are echoed by the National Research Council’s advice on clinical trials (National Research Council 2010)18 regarding estimands and sensitivity
Recommendation 15: Sensitivity analysis should be part of the primary reporting of findings from clinical trials. Examining sensitivity to the assumptions about the missing data mechanism should be a mandatory component of reporting.
Now, back to the NEJM paper. The reason why an ITT analysis and a PP analysis cannot serve as primary and sensitivity analyses, respectively, is because they are targeting entirely different estimands.13 Thus, because they are answering completely different questions, they’re just two different analyses. And the additional PP analysis, although important to certain stakeholders, can be classified as a supplementary analysis or a non-sensitivity analysis.
Indeed, the following flowchart from Morris et al. (2014)13 is particularly useful as a guide to differentiate sensitivity analyses from non-sensitivity analyses.
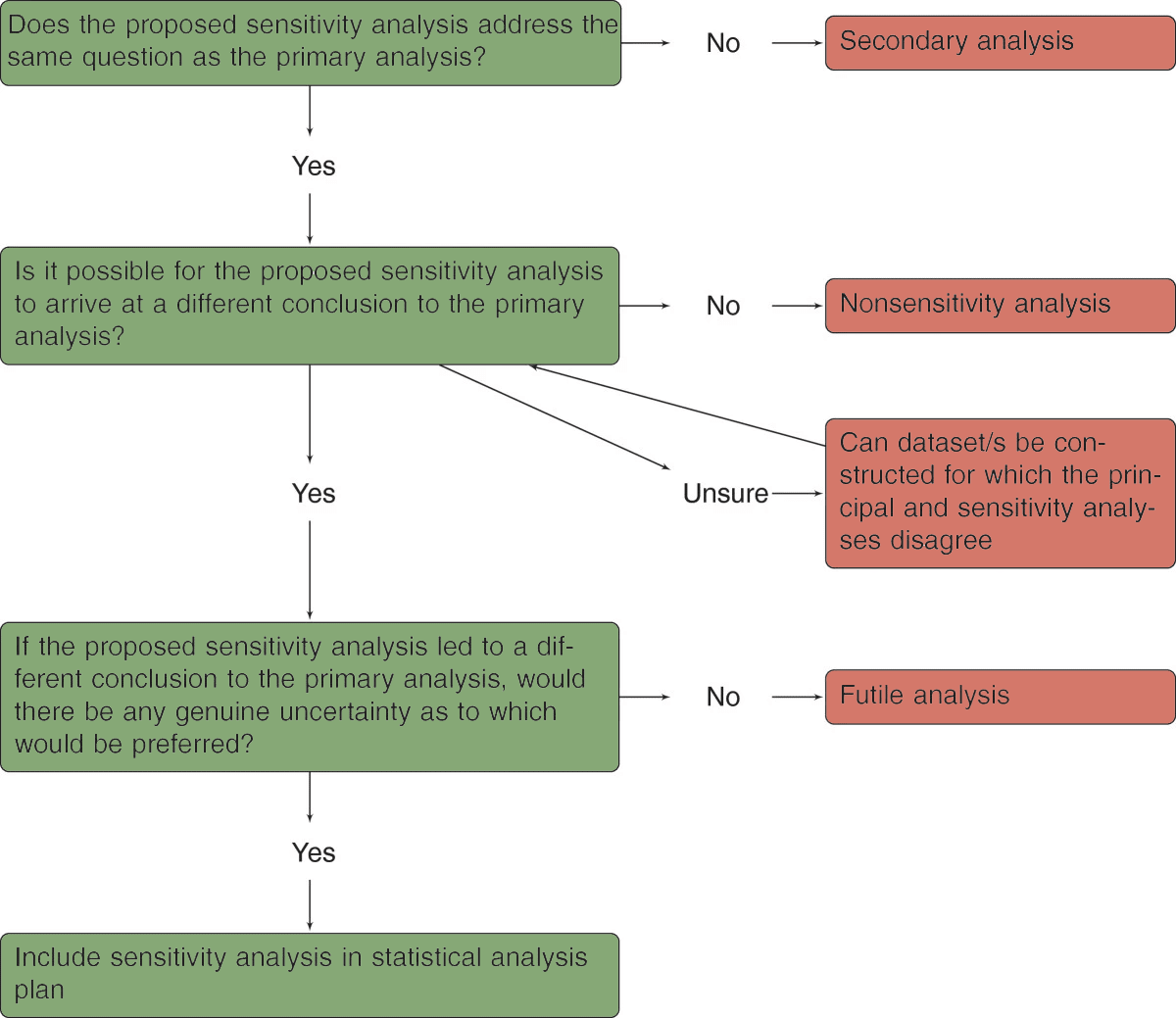
Utility of Subject-Matter Experts
So what does a sensitivity analysis actually look like within the context of a clinical trial or experiment? Below, I walk through the analysis of a trial to give some examples.
Sensitivity in Clinical Trials
I’ll use a sample clinical trial dataset, which is described here:19
“This dataset is typical of diastolic blood pressure data measured in small clinical trials in hypertension from the mid-to-late 1960s and for approximately a decade thereafter.
During this time, hypertension was more severe, the number of effective treatments was relatively small, and the definition (DBP > 95 mmHg) of essential hypertension was not as stringent as it is now (DBP > 80 mmHg) - as seen in the 1967 report from the Veterans Administration Cooperative Study Group on Antihypertensive Agents VA Study Group (1967).
In Table 3.1, diastolic blood pressure (DBP) was measured (mmHg) in the supine position at baseline (i.e., DBP) before randomization… Patients’ age and sex were recorded at baseline and represent potential covariates. The primary objective in this chapter in the analysis of this dataset is to test whether treatment A (new drug) may be effective in lowering DBP as compared to B (placebo) and to describe changes in DBP across the times at which it was measured.”
So to recap, the primary investigators of this trial were interested to see whether treatment A was more effective in lowering DBP when compared to placebo.
Although we will not be using some of the scripts and project setup that I discussed in my statistical workflow post for the sake of efficiency and ease, I would urge and recommend others do so that it remains easy to catch errors. In particular, I would especially recommend using the following packages:
For the analyses in this post, see the R packages in the session info section at the end of this post, these will need to be loaded in order for the scripts below to work.
Code
req_packs <- c("rms", "mice", "magrittr", "tidyr", "future",
"showtext", "concurve", "ggtext", "tidyverse", "ggplot2",
"parallel", "kableExtra", "cowplot", "Cairo", "svglite",
"yardstick", "broom", "mi", "Hmisc", "here", "VIM", "wesanderson",
"bayesplot", "lattice", "doParallel", "blogdown", "Amelia",
"bootImpute", "brms", "rmarkdown", "tinytex", "texPreview",
"ggcorrplot", "qqplotr", "car", "Statamarkdown", "rstan",
"missForest", "htmltools", "tidybayes", "performance", "mvtnorm",
"ImputeRobust", "gamlss", "ProfileLikelihood", "reshape2",
"boot", "knitr", "MASS", "miceMNAR")
# Load all packages at once
lapply(req_packs, library, character.only = TRUE)I will now simulate some of the data from this clinical trial.
Code
# Simulate Trial Data
set.seed(seed = 1031,
kind = "L'Ecuyer-CMRG",
normal.kind = "Inversion",
sample.kind = "Rejection")
BaselineDBP <- rnorm(500, 117, 2)
Group <- rbinom(500, 1, 0.5)
Age <- rnorm(500, 50, 7)
R1 <- rnorm(500, 0, 1)
R2 <- rnorm(500, 1, 0.5)
errors <- mvtnorm::rmvnorm(500,
mean = c(0, 0),
sigma = matrix(c(1, 0.5, 0.5, 1),
nrow = 2, byrow = TRUE
)
)
PostDBP <- BaselineDBP + (Age * 0.33) +
(Group * 9.7) + errors[, 1]I have made some minor adjustments to this dataset and also generated a new variable (Z) based on the existing ones in the dataset that is strongly correlated with the outcome of interest (PostDBP).
Code
# Explore Data
str(BP_full)
#> 'data.frame': 500 obs. of 7 variables:
#> $ PostDBP : num 142 140 129 148 135 ...
#> $ BaselineDBP: num 119 116 115 119 119 ...
#> $ Group : Factor w/ 2 levels "Drug X","Drug Y": 1 1 2 1 2 2 1 2 1 1 ...
#> $ Age : num 41.8 44.4 41.1 56.6 50.2 ...
#> $ Z : num 0.0141 -0.0629 -0.1101 0.0313 0.0495 ...
#> $ R1 : num 0.523 1.021 -0.839 0.413 -0.175 ...
#> $ R2 : num 0.451 0.35 0.897 1.227 1.166 ...| Variable | N | Overall N = 5001 |
Drug X N = 2581 |
Drug Y N = 2421 |
|---|---|---|---|---|
| PostDBP | 500 | 138.5 (133.4, 142.8) | 142.5 (140.5, 144.6) | 133.4 (131.3, 135.3) |
| BaselineDBP | 500 | 116.88 (115.56, 118.22) | 116.90 (115.53, 118.21) | 116.81 (115.59, 118.23) |
| Age | 500 | 49 (45, 55) | 49 (45, 55) | 50 (46, 55) |
| Z | 500 | 0.00 (-0.04, 0.05) | 0.00 (-0.04, 0.04) | 0.00 (-0.05, 0.05) |
| R1 | 500 | 0.00 (-0.73, 0.56) | 0.05 (-0.73, 0.60) | -0.10 (-0.74, 0.52) |
| R2 | 500 | 0.96 (0.64, 1.28) | 0.96 (0.59, 1.30) | 0.97 (0.67, 1.28) |
| 1 Median (Q1, Q3) | ||||
Code
summary(BP_full)
#> PostDBP BaselineDBP Group Age Z R1 R2
#> Min. :124 Min. :110 Drug X:258 Min. :27.7 Min. :-1.85e-01 Min. :-3.205036 Min. :-0.646
#> 1st Qu.:133 1st Qu.:116 Drug Y:242 1st Qu.:45.3 1st Qu.:-4.44e-02 1st Qu.:-0.732386 1st Qu.: 0.645
#> Median :138 Median :117 Median :49.4 Median : 9.45e-05 Median :-0.000058 Median : 0.960
#> Mean :138 Mean :117 Mean :49.7 Mean : 0.00e+00 Mean :-0.042800 Mean : 0.962
#> 3rd Qu.:143 3rd Qu.:118 3rd Qu.:54.7 3rd Qu.: 4.56e-02 3rd Qu.: 0.552206 3rd Qu.: 1.283
#> Max. :151 Max. :123 Max. :68.4 Max. : 2.02e-01 Max. : 3.377526 Max. : 2.480| PostDBP | BaselineDBP | Group | Age | Z | R1 | R2 |
|---|---|---|---|---|---|---|
| 142 | 119 | Drug X | 41.8 | 0.01 | 0.52 | 0.45 |
| 140 | 116 | Drug X | 44.4 | -0.06 | 1.02 | 0.35 |
| 129 | 115 | Drug Y | 41.1 | -0.11 | -0.84 | 0.90 |
| 148 | 119 | Drug X | 56.6 | 0.03 | 0.41 | 1.23 |
| 135 | 119 | Drug Y | 50.2 | 0.05 | -0.17 | 1.17 |
| 135 | 118 | Drug Y | 55.3 | 0.01 | -0.89 | 0.77 |
| 143 | 117 | Drug X | 54.3 | 0.00 | 1.07 | 0.34 |
| 133 | 116 | Drug Y | 55.8 | -0.05 | -1.91 | 0.96 |
| 144 | 118 | Drug X | 46.9 | 0.08 | 1.03 | 1.75 |
| 150 | 119 | Drug X | 62.0 | 0.01 | -0.94 | 2.48 |
Now, we can quickly explore the other characteristics of the dataset, and first we look at the rank correlations between the predictors and the response variable.
Code
# Data Attributes
study_formula <- as.formula(PostDBP ~ .)
plot(spearman2(study_formula, BP_full),
cex = 1,
pch = 18, col = alpha("darkred", 0.75)
)
abline(v = 0, col = alpha(zred, 0.75), lty = 3)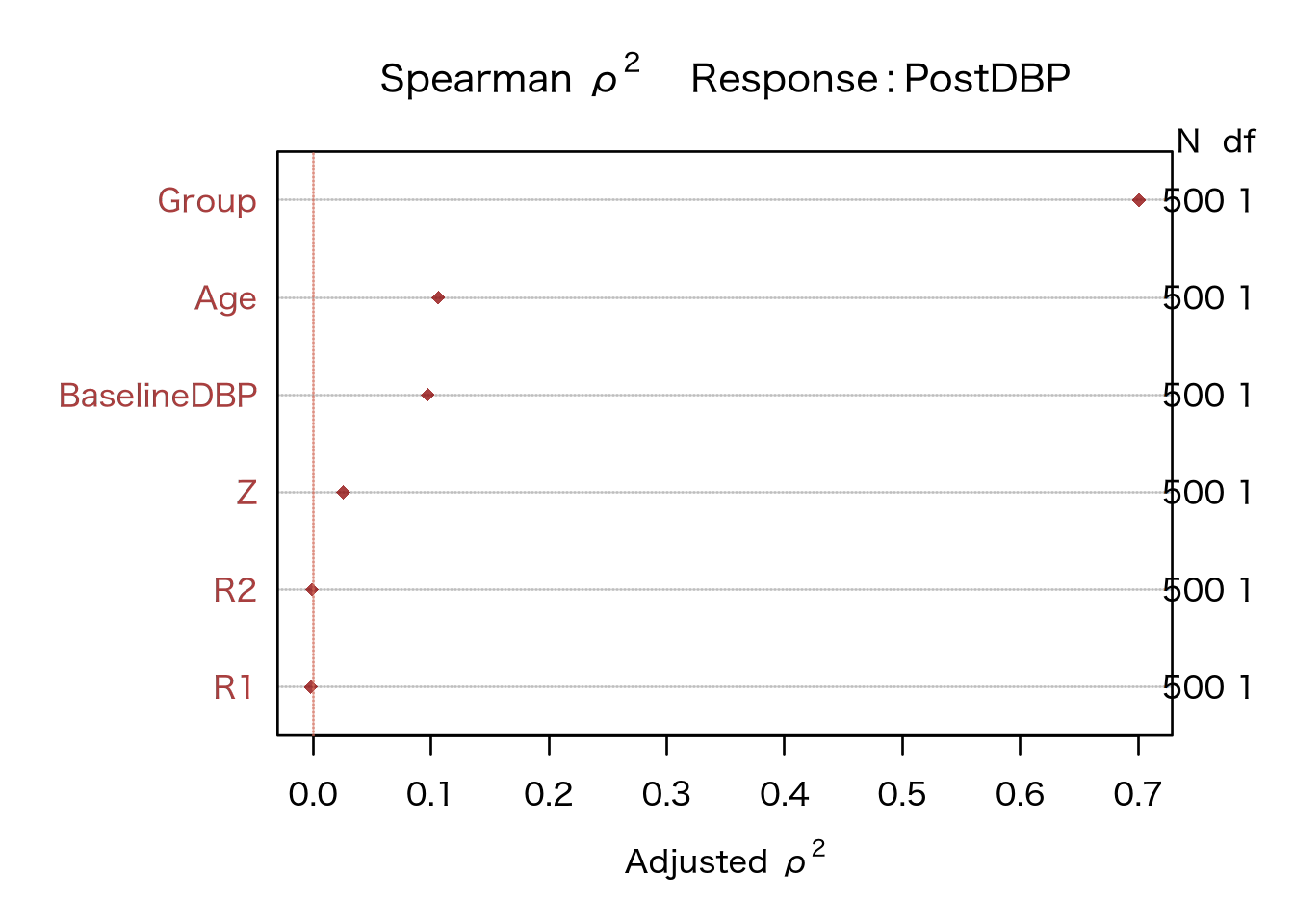
Along with a correlation matrix between the variables of interest.
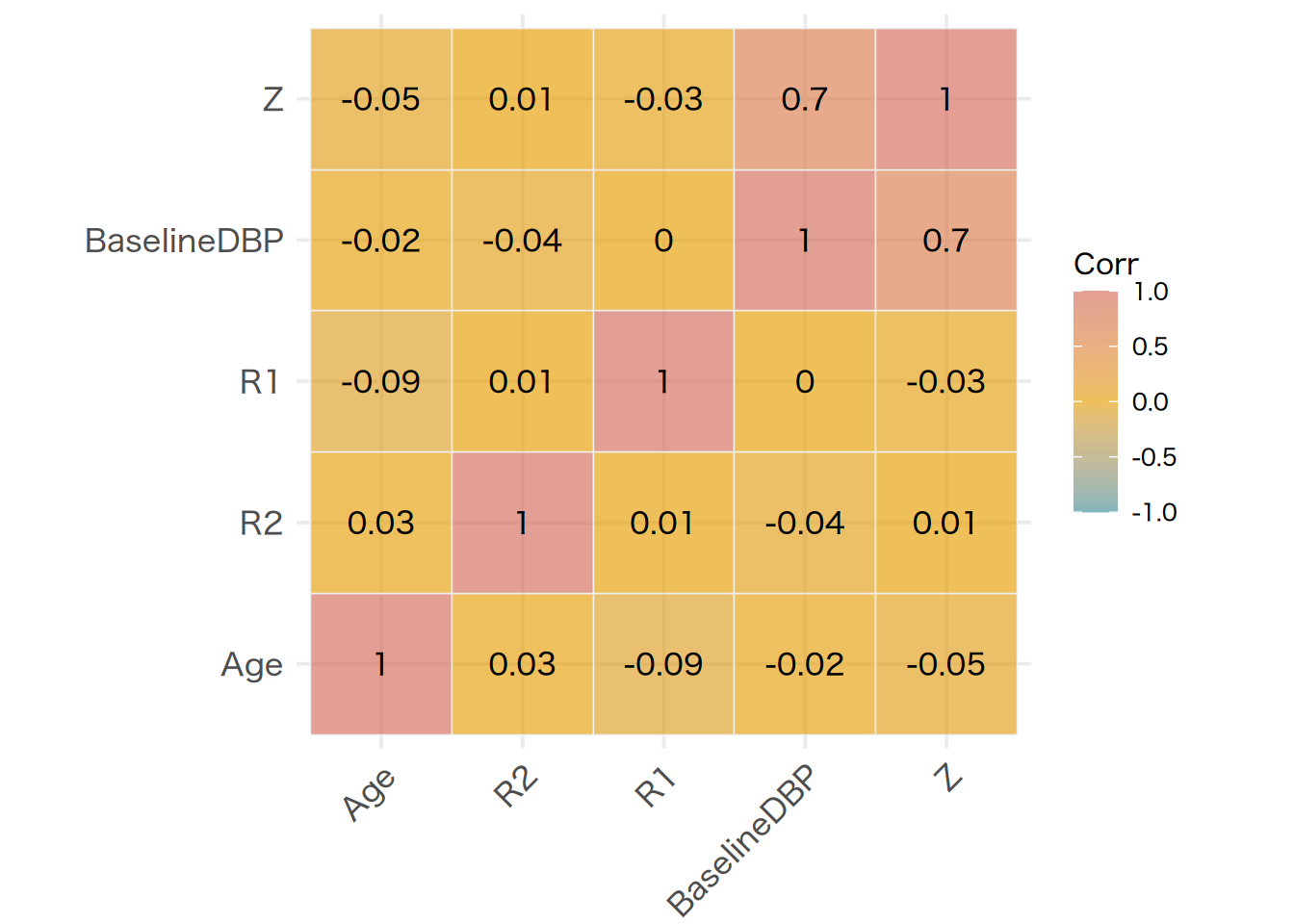
We will not be looking at the estimates from a fitted model yet. We are mainly looking at a few characteristics of this dataset before we move on to the next step.
The Threat of Missing Data
Now that we have familiarized ourselves with this dataset, we suddenly “notice” that there are missing data (which I actually generated below using a custom function) and suppose we didn’t actually know how the missing data were generated, we might suspect or start with the assumption that the data are missing at random (MAR).
We will explore a number of different methods used to handle missing data, including multiple imputation, selection models, and a number of ad-hoc methods commonly used by researchers handle missing data. However, before we move on to discussing some of these methods, we will quickly review concepts and terms regarding missing data mechanisms.
In the figure below, the three missing data mechanisms (MCAR, MAR, and MNAR) and ignorability (whether we need to model the mechanism of missing data) in relation to observed data (Y obs), missing data (Y mis), the missingness matrix (R), and their relationships (q; parameters that explain missingness, i.e., mechanism). The solid arrows, dotted arrows, and arrows with crosses represent “connection,” “possible connection,” and “no connection,” respectively.
The lines connecting ignorability and missingness group the three mechanisms into the two ignorability categories. Also no pure forms of MCAR, MAR, and MNAR exist, and all missingness can be considered as a form of MAR missingness; this is represented by the shaded continuum bar on the left. - Modified from Nakagawa and Freckleton (2011)
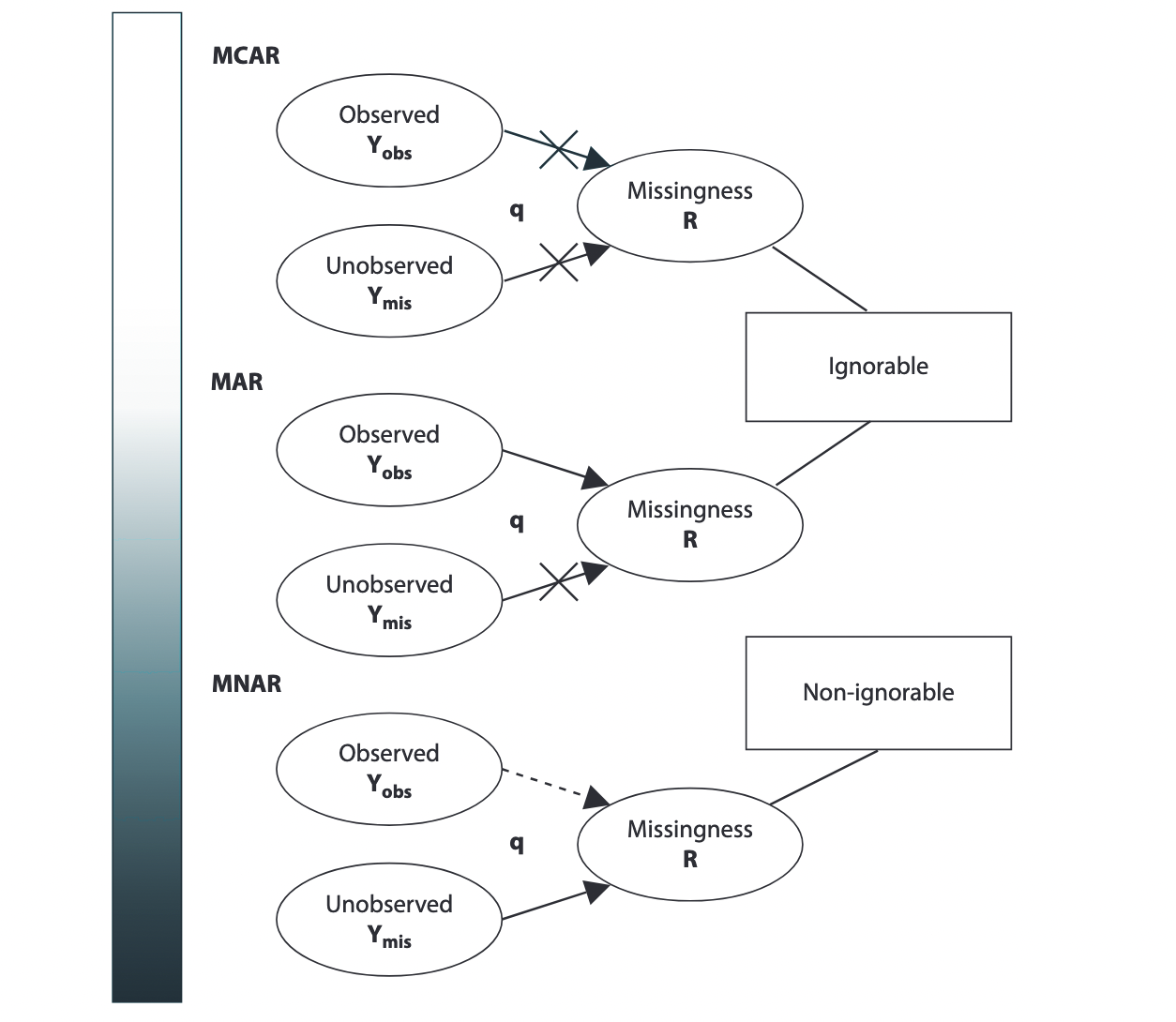
Of course, here, we do have an idea of what the missing data mechanism is, but we shall assume the role of a data analyst who has just been given a dataset with missing values in the outcome from their clinical colleague.
Code
# Generate Missing Data
set.seed(1031,
kind = "L'Ecuyer-CMRG",
normal.kind = "Inversion",
sample.kind = "Rejection"
)
Ry <- ifelse(lesslikely() > 0, 1, 0)
PostDBP[Ry == 0] <- NA
BP_miss <- data.frame(
PostDBP, BaselineDBP,
Group, Age, Z, R1, R2
)
str(BP_miss)
#> 'data.frame': 500 obs. of 7 variables:
#> $ PostDBP : num 142 140 129 148 135 ...
#> $ BaselineDBP: num 119 116 115 119 119 ...
#> $ Group : Factor w/ 2 levels "Drug X","Drug Y": 1 1 2 1 2 2 1 2 1 1 ...
#> $ Age : num 41.8 44.4 41.1 56.6 50.2 ...
#> $ Z : num 0.0141 -0.0629 -0.1101 0.0313 0.0495 ...
#> $ R1 : num 0.523 1.021 -0.839 0.413 -0.175 ...
#> $ R2 : num 0.451 0.35 0.897 1.227 1.166 ...
sum(is.na(BP_miss))
#> [1] 245
# Export data for Stata chunks
dir.create("static/datasets", recursive = TRUE, showWarnings = FALSE)
write.csv(BP_miss, "static/datasets/temp.csv", row.names = FALSE)We will now attempt to visualize our dataset and examine what proportion of these data are missing.
Code
missing_col <- c(zblue, zred)
aggr(BP_miss,
col = alpha(missing_col, 0.60),
plot = TRUE, prop = F, numbers = T
)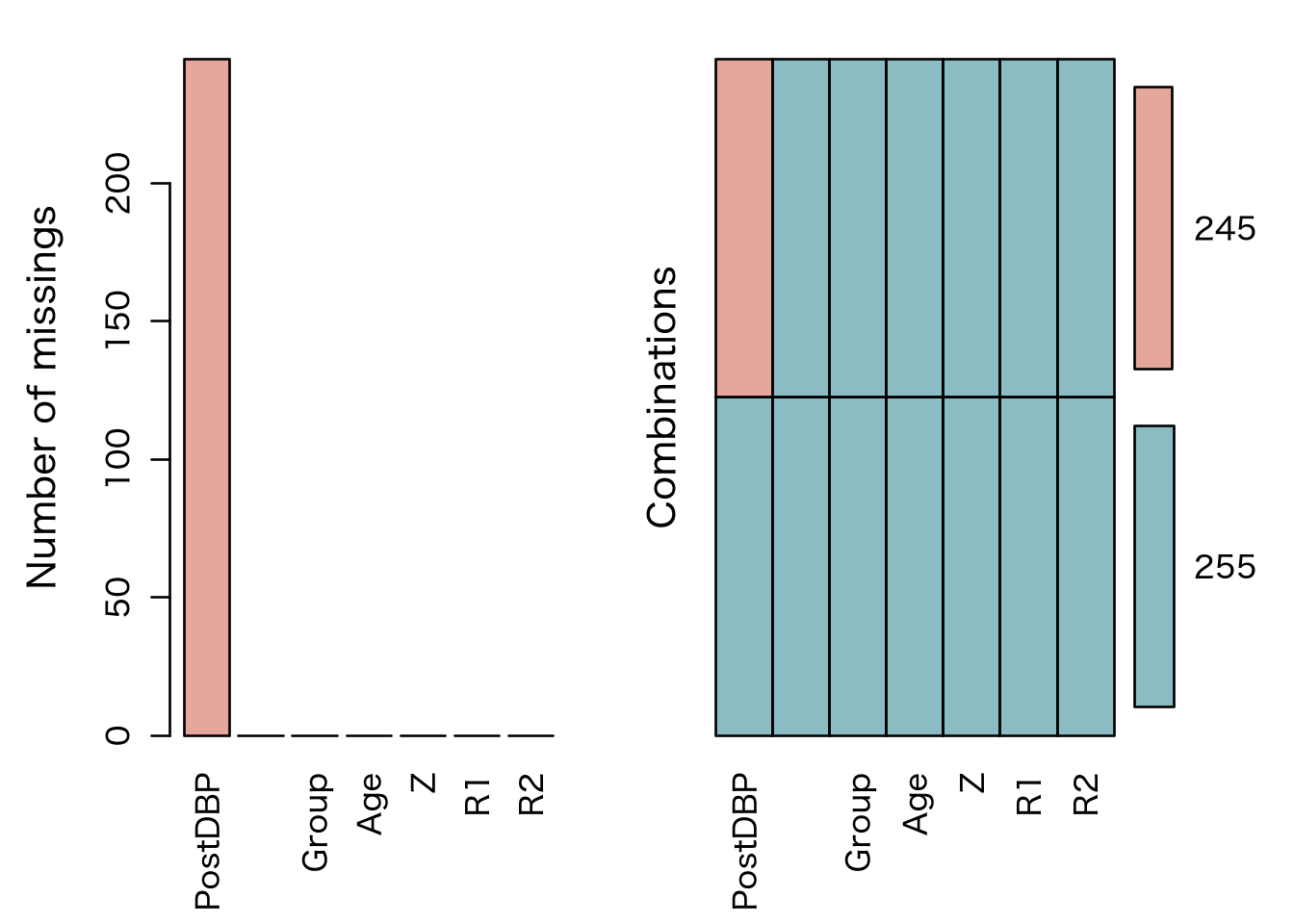
So now, we must examine this missing dataset and its characteristics and look for any systematic differences. We also examine the proportion of missingness and the influx and outflux patterns. This is important to assess how well connectected the missing data are to the observed data, explained by van Buuren here
The influx of a variable quantifies how well its missing data connect to the observed data on other variables. The outflux of a variable quantifies how well its observed data connect to the missing data on other variables. In general, higher influx and outflux values are preferred…
Influx and outflux are summaries of the missing data pattern intended to aid in the construction of imputation models. Keeping everything else constant, variables with high influx and outflux are preferred. Realize that outflux indicates the potential (and not actual) contribution to impute other variables. A variable with high \(O_{j}\) may turn out to be useless for imputation if it is unrelated to the incomplete variables. On the other hand, the usefulness of a highly predictive variable is severely limited by a low \(O_{j}\).
More refined measures of usefulness are conceivable, e.g., multiplying \(O_{j}\) by the average proportion of explained variance. Also, we could specialize to one or a few key variables to impute. Alternatively, analogous measures for \(I_{j}\) could be useful. The further development of diagnostic summaries for the missing data pattern is a promising area for further investigation.
Code
# Examine Flux Patterns
round(fico(BP_miss), 1)[2:6]
#> BaselineDBP Group Age Z R1
#> 0.5 0.5 0.5 0.5 0.5| POBS | Influx | Outflux | AINB | AOUT | FICO | |
|---|---|---|---|---|---|---|
| PostDBP | 0.51 | 0.45 | 0 | 1 | 0.00 | 0.00 |
| BaselineDBP | 1.00 | 0.00 | 1 | 0 | 0.08 | 0.49 |
| Group | 1.00 | 0.00 | 1 | 0 | 0.08 | 0.49 |
| Age | 1.00 | 0.00 | 1 | 0 | 0.08 | 0.49 |
| Z | 1.00 | 0.00 | 1 | 0 | 0.08 | 0.49 |
| R1 | 1.00 | 0.00 | 1 | 0 | 0.08 | 0.49 |
| R2 | 1.00 | 0.00 | 1 | 0 | 0.08 | 0.49 |
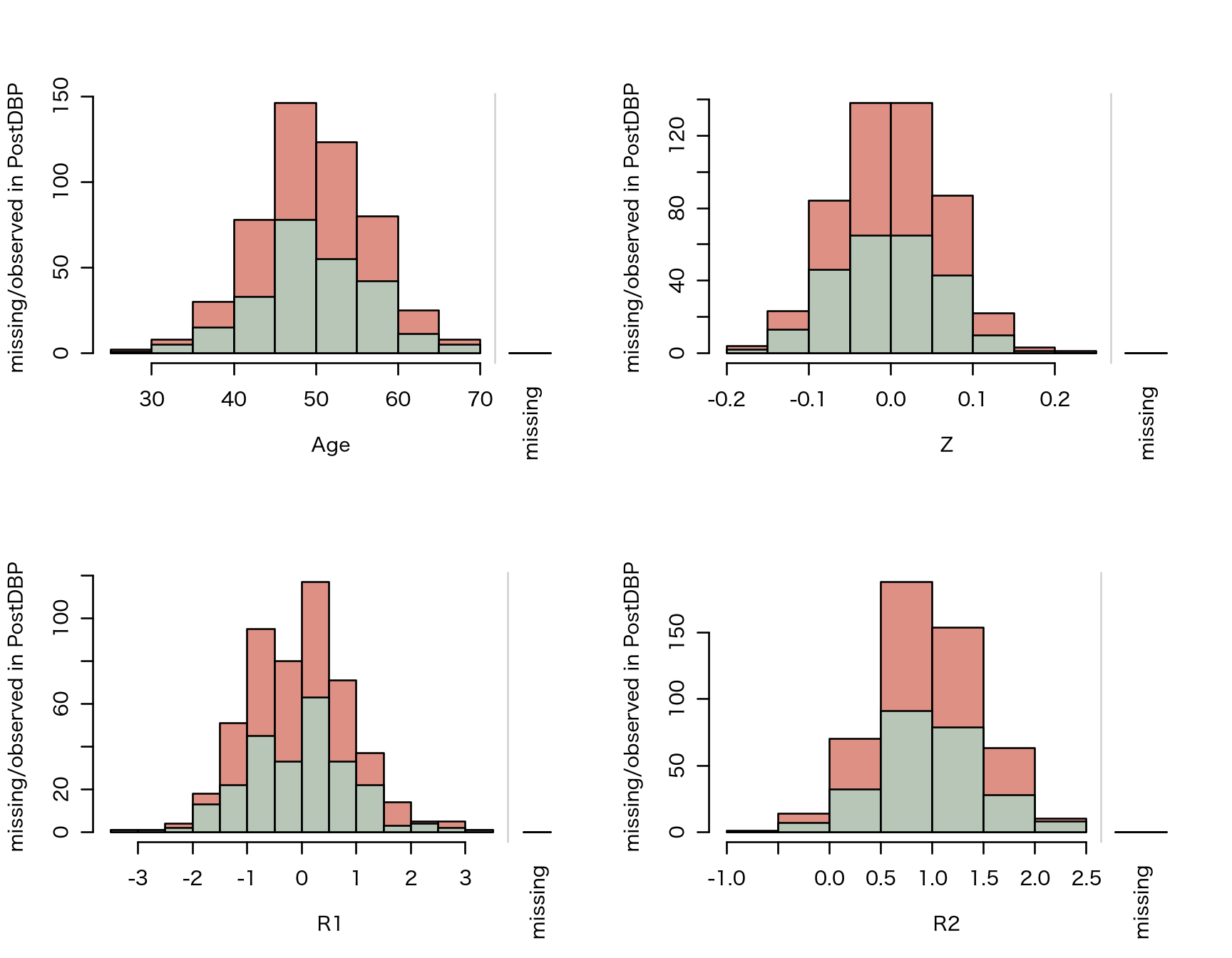
Next, We start off doing some preliminary analyses to eyeball differences between the observed data and the missing data.
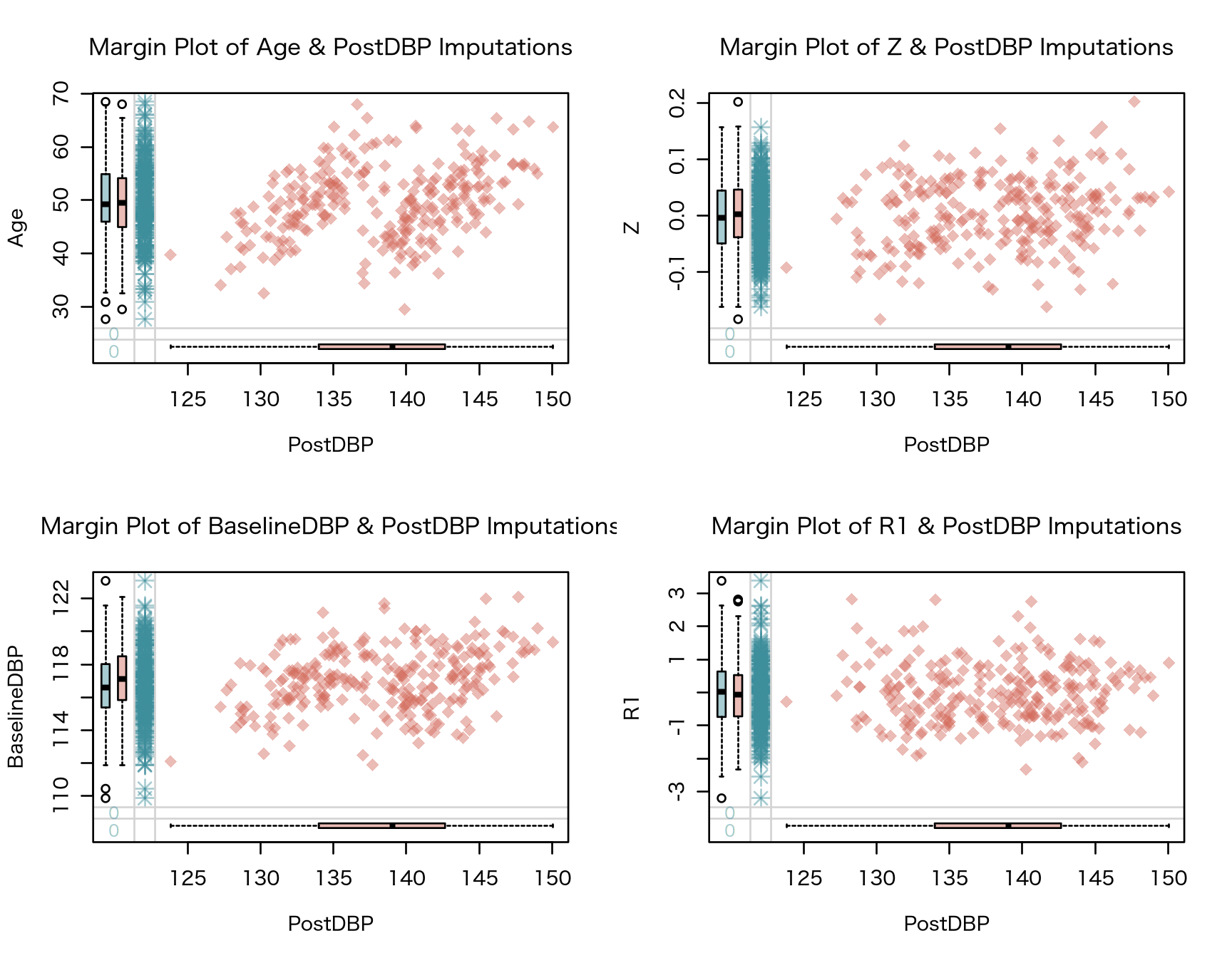
#> [1] 245| pobs | influx | outflux | ainb | aout | fico | |
|---|---|---|---|---|---|---|
| PostDBP | 0.51 | 0.45 | 0 | 1 | 0.00 | 0.00 |
| BaselineDBP | 1.00 | 0.00 | 1 | 0 | 0.08 | 0.49 |
| Group | 1.00 | 0.00 | 1 | 0 | 0.08 | 0.49 |
| Age | 1.00 | 0.00 | 1 | 0 | 0.08 | 0.49 |
| Z | 1.00 | 0.00 | 1 | 0 | 0.08 | 0.49 |
| R1 | 1.00 | 0.00 | 1 | 0 | 0.08 | 0.49 |
| R2 | 1.00 | 0.00 | 1 | 0 | 0.08 | 0.49 |
Having explored these data, we fit a preliminary model quickly to these missing data using the rlm() function from the MASS package and glance at what our estimates look like.
Code
# Exploratory Model Estimates
eda_1 <- rlm(
PostDBP ~ factor(Group) + BaselineDBP +
Age + Z + R1 + R2,
data = BP_miss,
method = "MM", psi = psi.huber
)| Value | Std. Error | t value | |
|---|---|---|---|
| (Intercept) | 11.68 | 5.77 | 2.02 |
| factor(Group)Drug Y | -9.58 | 0.13 | -71.57 |
| BaselineDBP | 0.98 | 0.05 | 19.86 |
| Age | 0.34 | 0.01 | 34.33 |
| Z | -0.93 | 1.48 | -0.62 |
| R1 | -0.03 | 0.07 | -0.43 |
| R2 | -0.13 | 0.13 | -0.94 |
| AIC | AICc | BIC | RMSE | Sigma |
|---|---|---|---|---|
| 749 | 750 | 778 | 1.02 | 1.03 |
Because the MASS::rlm() function will automatically delete missing observations and do a complete-case analysis, we can gauge what our estimates would look like if we assume that the data are missing completely at random (MCAR), which is almost always unrealistic.
It is almost always more realistic to assume that the data are missing at random (MAR), \(\operatorname{Pr}\left(R=0 \mid Y_{\mathrm{obs}}, Y_{\mathrm{mis}}, \psi\right)=\operatorname{Pr}\left(R=0 \mid Y_{\mathrm{obs}}, \psi\right)\). This can often be a reasonable assumption to start off with for the primary analysis.20
Multiple Imputation Workflow
For our main analysis, we will build an imputation model to essentially ‘predict’ the missing values in our dataset. This is because multiple imputation is a well-studied set of algorithms that are efficient and robust to deviances from normality.
Modern missing data methodologies include maximum-likelihood estimation (MLE) methods such as expectation–maximisation (EM) and multiple imputation (MI), both recommended for data which is MAR [3]. MI has been shown to be robust under departures from normality, in cases of low sample size, and when the proportion of missing data is high [2]. With complete outcome variables, MI is typically less computationally expensive than MLE, and MLE tends to be problem-specific with a different model being required for each analysis [8].
- Plumpton CO, Morris T, Hughes DA, White IR. Multiple imputation of multiple multi-item scales when a full imputation model is infeasible. BMC Res Notes. 2016 Jan 26;9:45. doi: 10.1186/s13104-016-1853-5.
How exactly does multiple imputation work?
The standard multiple imputation procedure (Rubin, 1987; Schafer, 1997) replaces missing covariate data with values drawn from a set of specified imputation models based on the observed relationships between the covariates and outcome, typically under a missing at random (MAR) assumption (Little and Rubin, 1987). A key feature of the procedure is that it outputs a number, say M, of imputed datasets. A prediction model is then fitted to each imputed dataset to produce imputation-specific regression coefficients, which can be averaged using “Rubin’s rules” (Rubin, 1987) to provide pooled regression coefficients.
To extract predictions from such a prediction model and multiply imputed data, either the sets of imputation-specific regression coefficients or the pooled regression coefficients could be used, and we must decide how to handle individuals with multiply imputed covariates. Thus there are numerous combinations for constructing a set of predictions, including imputation-specific predictions (M predictions for each individual) and pooled predictions (an averaged prediction over imputed datasets for each individual). The differences between them and their advantages and drawbacks are unclear.
Wood, A.M., Royston, P. and White, I.R. (2015), The estimation and use of predictions for the assessment of model performance using large samples with multiply imputed data. Biom. J., 57: 614-632. https://doi.org/10.1002/bimj.201400004
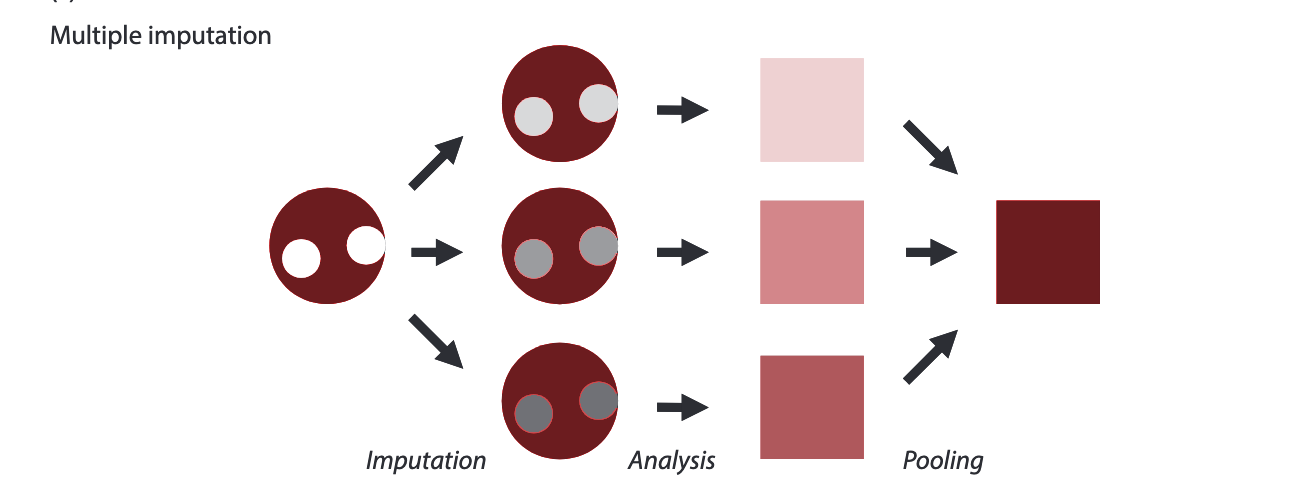
We include all possible information in our imputation model, for example, that might mean entail specifying all the variables in our dataset as covariates, and impute the missing data using a set of reliable and well-studied imputation algorithms, and then analyze each dataset and pool the results. Our basic workflow will look like this:
Concepts in Multiple Imputation
It can also be written using the following notation, which will be explained below.
\[ \begin{aligned} \bar{b} &=\frac{1}{m} \sum_{i=1}^m b_i \\ v_W &=\frac{1}{m} \sum_{i=1}^m s_{.} e_{\cdot}^2 \\ v_B &=\frac{1}{m-1} \sum_{i=1}^m\left(b_i-\bar{b}\right)^2 \\ v_T &=v_W+v_B+\frac{v_B}{m} \end{aligned} \]
There are three main steps in MI: imputation, analysis, and pooling (figure 4.5C). In the imputation step, you create \(m\) copies of completed data set by using data imputation methods such as the EM/EMB algorithms or the MCMC procedure. In the analysis step, you run separate statistical analyses on each of \(m\) data sets. Finally, in the pooling step, you aggregate \(m\) sets of results to produce unbiased parameter and uncertainty estimates.
This aggregation process is done by the following equations (which are automatically calculated in R): where ̄\(b\) is the mean of \(b_{i}\) (e.g., regression coefficients), which is a parameter estimated from the ith data set (\(m\)), \(v_W\) is the within-imputation variance calculated from the standard error associated with \(b_{i}\), \(v_B\) is the between-imputation variance estimates, and \(v_T\) is the total variance (\(√v_T\) is the overall standard error for \(\bar{b}\)).
This set of equations for combining estimates from \(m\) sets of results is often referred to as Rubin’s rules, as it was developed by Rubin (1987). Statistical significance and confidence intervals (CIs) of pooled parameters are obtained by, where \(df\) is the number of degrees of freedom used for t-tests or to obtain \(t\) values and CI calculations, and \(α\) is the significance level (e.g., 95% CI, \(α\) = 0.05).:
\[ \begin{aligned} d f &=(m-1)\left(1+\frac{m v_W}{(m+1) v_B}\right)^2, \\ t_{d f} &=\frac{\bar{b}}{\sqrt{v_T}}, \\ 100(1-\alpha) \% \mathrm{CI} &=\bar{b} \pm t_{d f,(1-\alpha / 2) \sqrt{v_T}} \end{aligned} \]
Nagakawa then discusses the similarities between imputation algorithms and MCMC methods,
MCMC procedures (and also Gibbs sampling) are often called Bayesian methods (chapter 1) because their goal is to create the posterior distributions of parameters, but methods using MCMC have much wider applications than Bayesian statistics). The MCMC procedure, is akin to the EM algorithm (Schafer 1997) in that it uses a two-step iterative algorithm to find \(\bf{\hat{m}}\) and \(\bf{\hat{V}}\).
The imputation step (I-step) uses stochastic regression with observed data. Next, the posterior step (P-step) uses this filled-in data set to construct the posterior distributions of \(\bf{\hat{m}}\) and \(\bf{\hat{V}}\). Then, it uses a Monte Carlo method to sample a new set of \(\bf{\hat{m}}\) and \(\bf{\hat{V}}\) from these distributions. These new parameter estimates are used for the subsequent I-step. Iterations of the two steps create the Markov chain, which even actually converges into fully fledged posterior distributions of \(\bf{\hat{m}}\) and \(\bf{\hat{V}}\) (figure 4.6B). These distributions are, in turn, used for multiple imputation.
Now that we’ve quickly reviewed some of the concepts of multipe imputation and missing data, we can now begin to build our imputation model. This is generally done by building a model with all relevant covariates, however, this should be compared a reduced model with just the treatment group. This is because we want both the adjusted and unadjusted estimates. We will then compare these models using the likelihood-ratio test21 to see whether there are any substantial differences between the fully-adjusted and reduced model.
The imputation model for a particular parameter will generally resemble the estimation model being used.
When developing your imputation model, it is important to assess if your imputation model is “congenial” or consistent with your analytic model. Consistency means that your imputation model includes (at the very least) the same variables that are in your analytic or estimation model. This includes any transformations to variables that will be needed to assess your hypothesis of interest. This can include log transformations, interaction terms, or recodes of a continuous variable into a categorical form, if that is how it will be used in later analysis. The reason for this relates back to the earlier comments about the purpose of multiple imputation.
Since we are trying to reproduce the proper variance/covariance matrix for estimation, all relationships between our analytic variables should be represented and estimated simultaneously. Otherwise, you are imputing values assuming they have a correlation of zero with the variables you did not include in your imputation model. This would result in underestimating the association between parameters of interest in your analysis and a loss of power to detect properties of your data that may be of interest such as non-linearities and statistical interactions. - From the UCLA Statistical Consulting Website
Monte Carlo Error Analysis
However, before we begin to build the model, we must also have an idea of how many imputations we need to compute. To many, this may seem like a trivial and even nonsensical task when any individual can impute a large number of datasets. Indeed, it may seem that more imputations would give a more reliable and precise estimate, however, nothing in life is free, and running a imputation algorithm that is computationally demanding (and which can potentially take hours or days) is not feasible for everyone, hence the reason for “sample-size” calculations for imputation algorithms.
Multiple imputation is a stochastic procedure. Each time we reimpute our data, we get different sets of imputations because of the randomness of the imputation step, and therefore we get different multiple-imputation estimates. However, we want to be able to reproduce MI results. Of course, we can always set the random-number seed to ensure reproducibility by obtaining the same imputed values. However, what if we use a different seed? Would we not want our results to be similar regardless of what seed we use? This leads us to a notion we call statistical reproducibility—we want results to be similar across repeated uses of the same imputation procedure; that is, we want to minimize the simulation error associated with our results.
To assess the level of simulation error, White, Royston, and Wood (2011) propose to use a Monte Carlo error of the MI results, defined as the standard deviation of the results across repeated runs of the same imputation procedure using the same data. The authors suggest evaluating Monte Carlo error estimates not only for parameter estimates but also for other statistics, including p-values and confidence intervals, as well as MI statistics including RVI and FMI.
The issue with this is that without giving careful thought to how many imputations may be needed for a particular study, one may run the risk of imputing too few datasets and losing information, or they may waste resources imputing a nonsensical amount that may not be necessary. Indeed, the latter seems especially trivial, however, it may often yield no advantages whatsoever, and only incur costs as many authors have argued.
The argument is that “the additional resources that would be required to create and store more than a few imputations would not be well spent” (Schafer 1997, 107), and “in most situations there is simply little advantage to producing and analyzing more than a few imputed datasets” (Schafer and Olsen 1998, 549).
Therefore, we will examine certain characteristics of our dataset with missing values and use them in an analysis to determine how many datasets we should impute to efficiently achieve our goals. We will base this off a number of characteristics such as the fraction of missing information, the proportion of missing observations, and the losses that we are willing to incur.
We first start by running a “dry” or naive imputation of our data to quickly examine some of these characteristics. This imputed dataset will not be used for our primary analysis, it is simply serving to guide us in our main imputation model. This is also why we have set the number of iterations to 0.
Once again, we will include all the variables in our dataset, and use the predictive mean matching method with approximately 5 donors.
Code
# Dry Imputation
form <- list(PostDBP ~ factor(Group) + BaselineDBP + Age + Z + R1 + R2)
pred <- make.predictorMatrix(BP_miss)
parlmice(BP_miss, method = "pmm", m = 20,
maxit = 0, cores = cores, donors = 5,
cluster.seed = 1031, formulas = form, ridge = 0,
predictorMatrix = pred, remove.collinear = TRUE,
remove.constant = TRUE, allow.na = TRUE,
printFlag = FALSE, visitSequence = "monotone") -> init_imp
head(init_imp$loggedEvents, 10)
#> NULLNow that we have imputed our dataset, we may examine it for any issues before moving onto the next step of analyzing it.
#> Error in `xyplot.mids()`:
#> ! Missing formula#> Error in `lattice::latticeParseFormula()`:
#> ! model must be a formula objectAlthough it is only a dry run, there seems to be no issues with it. We now pool our estimates using Rubin’s rules.
Code
init_res <- mice::pool(with(
init_imp,
rlm(
PostDBP ~ factor(Group) +
BaselineDBP + Age +
Z + R1 + R2,
method = "MM", psi = psi.huber
)
))
init_res_sum <- summary(init_res)
colnames(init_res_sum) <- c(
"Term", "Estimate", "SE",
"Statistic", "df", "P-val"
)
ztable(init_res_sum)| Term | Estimate | SE | Statistic | df | P-val |
|---|---|---|---|---|---|
| (Intercept) | 33.48 | 16.21 | 2.07 | NA | NA |
| factor(Group)Drug Y | -8.25 | 0.39 | -21.08 | NA | NA |
| BaselineDBP | 0.81 | 0.14 | 5.90 | NA | NA |
| Age | 0.28 | 0.03 | 8.57 | NA | NA |
| Z | 0.69 | 4.11 | 0.17 | NA | NA |
| R1 | 0.01 | 0.18 | 0.08 | NA | NA |
| R2 | -0.01 | 0.38 | -0.02 | NA | NA |
Now that we have our vector, we can quickly examine certain characteristics such as the fraction of missing information (FIMO), the between-imputation variance and the within-imputation variance. The reason that we focus on these particular attributes is because they are crucial for several tasks in any statistical analysis plan, such as having enough power/precision, minimum long-run coverage, etc.
We use the FIMO from the dry imputation and a number of other criteria to determine how many imputations we need:
- Some have suggested taking the FIMO and multiplying by 100 to obtain the number of imputed datasets needed
\[m \approx 100 \lambda\]
- For our goals, we wish to ensure that the monte-carlo standard error from the imputations are less than 10% of the between-imputation standard error
\[mcse < B^{\hat{-}}_{SE} * 0.10\]
- We wish to minimize the monte-carlo error that is derived from dividing the chosen number of datasets to impute from the fraction of missing information so that the monte-carlo standard error is less than 0.01
\[\frac{FMI}{m} ≈ 0.01\]
- We also wish to minimize the total variance so that the square-root of it is no greater than the ideal variance and the corresponding confidence interval width.
\[T_{m}=\left(1+\frac{\gamma_{0}}{m}\right) T_{\infty}\]
- Furthermore, it is commonly advocated by missing data experts to impute the same or similar number of datasets as fractions of missing observations \[\gamma_{0}*100\]
We start by extracting the FMIs from our dry imputation and calculating all these numbers.
Code
# Calculate Fraction of Missing Information
# `mice::pool()`/`summary.mipo()` have changed their returned columns across
# versions. Prefer the explicit `fmi` column when present; otherwise fall back
# to `lambda`, and finally compute it from Rubin's variance components.
extract_fmi <- function(model) {
if (is(model, "mira")) {
model <- mice::pool(model)
}
if (!is(model, "mipo")) {
stop("Model must be multiply imputed.")
}
pooled <- model$pooled
finite_max <- function(x) {
x <- suppressWarnings(as.numeric(x))
x <- x[is.finite(x)]
if (length(x)) max(x) else NA_real_
}
fmi_value <- if ("fmi" %in% names(pooled)) finite_max(pooled$fmi) else NA_real_
if (!is.na(fmi_value)) return(min(max(fmi_value, 0), 0.999))
lambda_value <- if ("lambda" %in% names(pooled)) finite_max(pooled$lambda) else NA_real_
if (!is.na(lambda_value)) return(min(max(lambda_value, 0), 0.999))
if (all(c("b", "ubar") %in% names(pooled))) {
m_count <- if (!is.null(model$m)) model$m else finite_max(pooled$m)
riv <- (1 + 1 / m_count) * pooled$b / pooled$ubar
lambda <- riv / (1 + riv)
if ("df" %in% names(pooled)) {
fmi_calc <- lambda + (2 / (pooled$df + 3))
} else {
fmi_calc <- lambda
}
fmi_value <- finite_max(fmi_calc)
if (!is.na(fmi_value)) return(min(max(fmi_value, 0), 0.999))
}
stop("Could not extract or compute fraction of missing information from pooled model.")
}
fmi <- extract_fmi(init_res)
m <- fmi / 0.01 # FMI Imputations
mcse <- sqrt(max(init_res$pooled$b, na.rm = TRUE) / m) # MCSE
se <- max((init_res$pooled$ubar) / sqrt(500), na.rm = TRUE) # SEWhat we find is that the fraction of missing information is nearly 50% which is very high and that in order to get a monte-carlo error of less than 0.01, we would need a minimum of at least 50 imputed datasets. We also calculate both the monte-carlo standard error and the standard error from the dry run and find that they are practically equivalent.
However, we must also explore other possibilities in terms of number of imputed datasets to reduce the monte-carlo errors so we run a quick function to do that, checking the effects of a number of imputed datasets on the width of the confidence interval, which is directly tied to the monte-carlo error.
Indeed, Von Hippel (2018) proposed a relationship between the fraction of missing information and the number of imputations needed to achieve a targeted CI length or monte-carlo error using a quadratic formula,
\[m=1+\frac{1}{2}\left(\frac{\gamma_{0}}{\operatorname{SD}\left(\sqrt{U_{\ell}}\right) \mathrm{E}\left(\sqrt{U_{\ell}}\right)}\right)^{2}\]
where \(\mathrm{E}\left(\sqrt{U_{\ell}}\right)\) and \(\mathrm{SD}\left(\sqrt{U_{\ell}}\right)\) are the coefficient of variation (CV), summarizing the imputation variation in the SE estimates. We can graphically construct a function to depict this relationship and calculate how many imputations we will need based on some desired error and further display the distribution of this relationship by varying these parameters.
In the function below, adopted from von Hippel, and van Buuren,20 I vary both the coefficient of variation and the \(\alpha\)-level.
Code
#' @title How Many Imputations?
#' @description Implements two-stage "how_many_imputations" from von Hippel (2018)
#' @param model Either a `mira` object (created by running a model on a data set which was imputed via "mice")
#' or a `mipo` object (creating by runing `pool()` on a `mira` object).
#' @param cv Desired precision of standard errors. Default to .05. (I.e., if the data were re-imputed, the
#' estimated standard errors would differ by no more than this amount.)
#' @param alpha Significance level for choice of "conservative" FMI.
#' @return The number of required imputations to obtain the `cv` level of precision.
#' @export
#' @importFrom methods is
#' @importFrom stats plogis qlogis qnorm
#' @importFrom mice pool
#' @references von Hippel, Paul T. (2018)
#' \sQuote{How Many Imputations Do You Need? A Two-stage Calculation Using a Quadratic Rule.},
#' \emph{Sociological Methods & Research} p.0049124117747303.
#'
powerimp <- function(model, cv = .05, alpha = .05) {
if (is(model, "mira")) {
model <- mice::pool(model)
}
if (!is(model, "mipo")) {
stop("Model must be multiply imputed.")
}
fmi <- extract_fmi(model)
z <- qnorm(1 - alpha / 2)
fmiu <- plogis(qlogis(fmi) + z * sqrt(2 / model$m))
ceiling(1 + 1 / 2 * (fmiu / cv)^2)
}
ci_width <- function() {
cv_i <- seq(0.01, 0.20, 0.01)
results1 <- lapply(
(seq_along(cv_i) / 100),
function(i) {
powerimp(
model = init_res,
cv = i, alpha = 0.01
)
}
)
results2 <- lapply(
(seq_along(cv_i) / 100),
function(i) {
powerimp(
model = init_res,
cv = i, alpha = 0.05
)
}
)
results3 <- lapply(
(seq_along(cv_i) / 100),
function(i) {
powerimp(
model = init_res,
cv = i, alpha = 0.1
)
}
)
a_0.01 <- do.call(rbind, results1)
df <- data.frame(cv_i, a_0.01)
df$a_0.05 <- do.call(rbind, results2)
df$a_0.1 <- do.call(rbind, results3)
return(df)
}
some <- ci_width()With this function, we can now graphically examine the effects of different parameter values on the monte-carlo errors from the imputations.
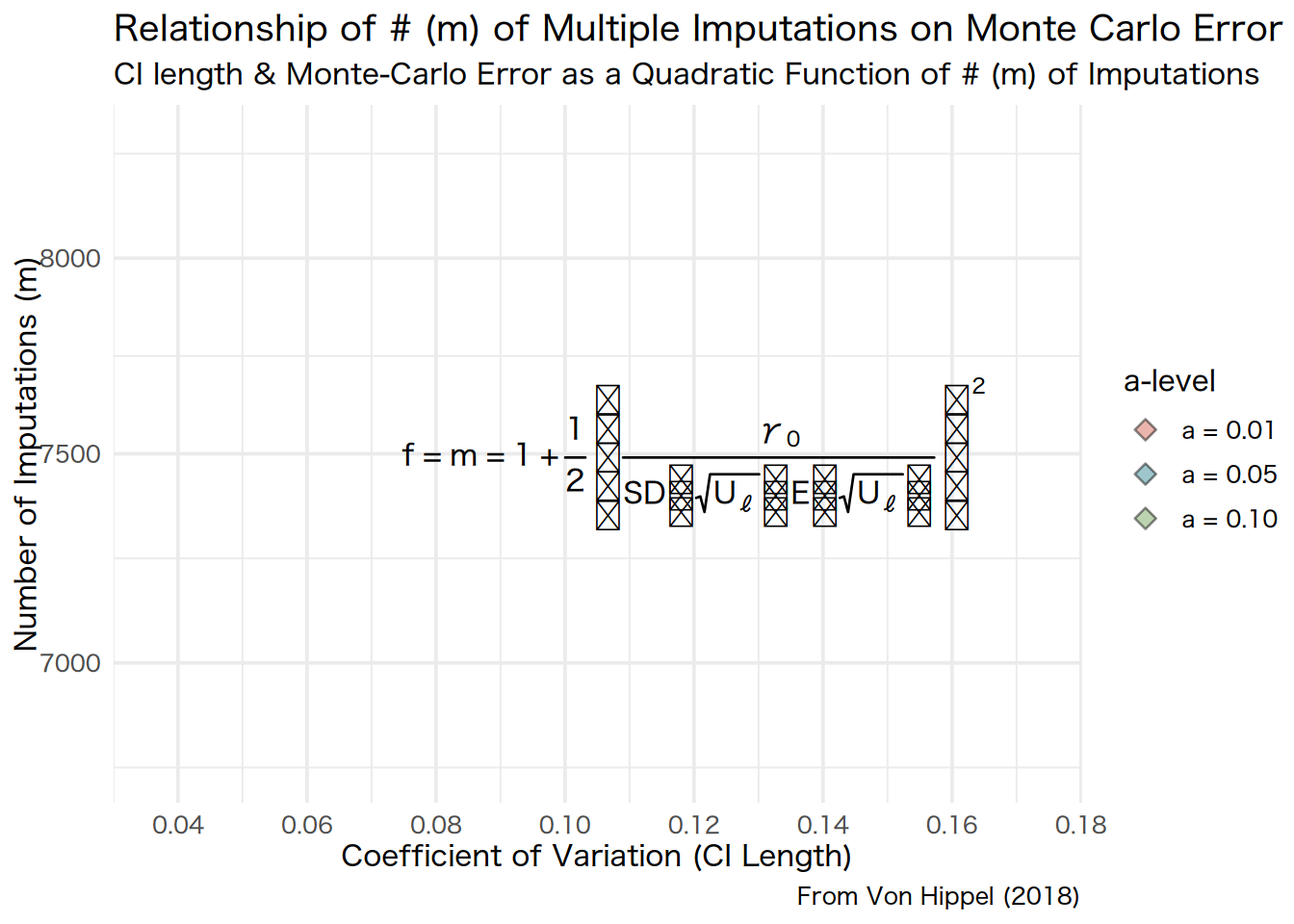
We can see above that as we aim for smaller monte-carlo errors, we need many more imputations to achieve our desired target.
Now that I have constructed and graphed three differing relationships between monte-carlo errors and number of imputations needed to achieve those errors, and varied the \(\alpha\)-levels, we can now move onto choosing a specific number of imputations to construct.
If I choose an \(\alpha\) level of 5%, which the maximum tolerable type-I error rate, and a coefficient of variation of 5%
Code
# Estimate Number of Imputations
powerimp(model = init_res, cv = 0.10, alpha = 0.05)
#> [1] 28
powerimp(model = init_res, cv = 0.05, alpha = 0.05)
#> [1] 109
powerimp(model = init_res, cv = 0.01, alpha = 0.05)
#> [1] 2699I need to construct approximately 124 imputations to achieve this coefficient of variation, which is what I will use for all the analyses from here on, and it is clear that it is far more reasonable than trying to impute 3000 datasets to achieve a tiny standard error.
However, I want to verify my calculations by running a similar estimation command that Stata provides. The documentation says the following regarding RVI and FMI:
Returning to the output, average RVI reports the average relative increase (averaged over all coefficients) in variance of the estimates because of the missing bmi values. A relative variance increase is an increase in the variance of the estimate because of the loss of information about the parameter due to nonresponse relative to the variance of the estimate with no information lost. The closer this number is to zero, the less effect missing data have on the variance of the estimate. Note that the reported RVI will be zero if you use mi estimate with the complete data or with missing data that have not been imputed. In our case, average RVI is small: 0.0312.
Largest FMI reports the largest of all the FMI about coefficient estimates due to nonresponse. This number can be used to get an idea of whether the specified number of imputations is sufficient for the analysis. A rule of thumb is that M ≥ 100 × FMI provides an adequate level of reproducibility of MI analysis. In our example, the largest FMI is 0.14 and the number of imputations, 20, exceeds the required number of imputations: 14
Although I cannot get the number of imputations directly from a command, I can run the mi estimate command, and look at the overall fraction of missing information as the number of imputations increases. If my previous calculations are consistent, I should look to increase the number of imputations until I achieve an FMI of 1.24 or less: 124/100
Code
set linesize 255
clear all
set seed 1031
parallel setclusters 8, statapath(/Applications/Stata)
parallel initialize 8, statapath(/Applications/Stata)
quietly import delimited "datasets/temp.csv", numericcols(2 3 5 6 7 8)
quietly mi set mlong
quietly mi register imputed baselinedbp postdbp age z group r1 r2
quietly parallel: mi impute chained (pmm, knn(5)) postdbp = baselinedbp age z r1 r2 group, burnin(5) add(120) rseed (1031) nomonotone
quietly mi estimate, saving(miest, replace): rreg postdbp i.group baselinedbp age z r1 r2
mi estimate using miest, mcerror level(95)
mi estimate, saving(miest, replace) vartable mcerror level(95) nocitable: rreg postdbp i.group baselinedbp age z r1 r2
mi estimate using miest, mcerror level(95)
#> Can not set Stata directory, try using -statapath(
#> > )- option
#> r(601);
#>
#>
#>
#>
#>
#> N Clusters: 8
#> Can not set Stata directory, try using -statapath()- option
#> r(601);
#>
#> r(601);The Primary Analysis
For the primary analysis, I will use the predictive-mean matching method and specify 5 donors (based on a number of simulation studies that have examined the effect of various donors specified)22, and fit a robust regression that includes all the variables within the dataset. Our imputation model will be
\[Y^{\operatorname{Post}} = \beta_{0} + \beta_{1}^{\operatorname{Group}} + \beta_{2}^{\operatorname{Base}} + \beta_{3}^{\operatorname{Age}} + \beta_{4}^{\operatorname{Z}} + \beta_{5}^{\operatorname{R1}} + \beta_{6}^{\operatorname{R2}} + \epsilon\]
So we will now impute our datasets.
Code
# Impute Missing Data
form <- list(PostDBP ~ factor(Group) + BaselineDBP + Age + Z + R1 + R2)
pred <- make.predictorMatrix(BP_miss)
parlmice(BP_miss,
method = "pmm",
predictorMatrix = pred,
m = 120, maxit = 5, cluster.seed = 1031,
n.core = cores, n.imp.core = (m / cores),
formulas = form, ridge = 0, cl.type = "FORK",
donors = 5, remove.collinear = TRUE,
remove.constant = TRUE, allow.na = TRUE,
printFlag = FALSE, visitSequence = "monotone"
) -> imp1
head(imp1$loggedEvents, 10)
#> NULLNow that we have imputed our datasets, we may examine them for any issues before moving onto the next step of analyzing it.
#> Error in `as.character()`:
#> ! cannot coerce type 'closure' to vector of type 'character'
#> Error in `h()`:
#> ! error in evaluating the argument 'object' in selecting a method for function 'update': object 't1' not found
#> Error:
#> ! object 'aesthetics' not foundOur imputed datasets seem to look fine so far. We now fit our models to each of these datasets and combine them using Rubin’s rules.
Code
# Primary Analysis
analysis1 <- with(imp1, rlm(
PostDBP ~ (Group) +
BaselineDBP + Age + Z + R1 + R2,
method = "MM", psi = psi.huber
))
#> Error:
#> ! object 'imp1' not found
analysis2 <- with(imp1, rlm(PostDBP ~ (Group),
method = "MM", psi = psi.huber
))
#> Error:
#> ! object 'imp1' not found
anova(analysis1, analysis2,
method = "D3", use = "LR"
)
#> Error:
#> ! object 'analysis1' not foundCode
result1 <- mice::pool(analysis1)
#> Error:
#> ! object 'analysis1' not found
results1_sum <- summary(result1)
#> Error in `h()`:
#> ! error in evaluating the argument 'object' in selecting a method for function 'summary': object 'result1' not found
colnames(results1_sum) <- c(
"Term", "Estimate", "SE",
"Statistic", "df", "P-val"
)
#> Error:
#> ! object 'results1_sum' not found#> Error:
#> ! object 'results1_sum' not foundWhile we have our primary analysis estimates, we also continue to examine our imputations for any anomalies.
#> Error in `h()`:
#> ! error in evaluating the argument 'x' in selecting a method for function 'rowMeans': object 'analysis1' not found
#> Error in `as.character()`:
#> ! cannot coerce type 'closure' to vector of type 'character'We’ve done our primary analysis, in which we imputed the missing data under the assumption of MAR, which is often a reasonable assumption to start with. Unfortunately, we cannot verify whether or not this assumption is true, but we can vary this missing data assumption and assume that the data are missing not at random (MNAR) \(\operatorname{Pr}\left(R=0 \mid Y_{\mathrm{obs}}, Y_{\mathrm{mis}}, \psi\right)\), and that in the individuals with missing data, we can assume different numbers than those with complete data. Our likelihood-ratio test also suggests that there’s very little difference between the full model and the reduced model, so we generally will go with the full model.
SA I: Controlled Imputations
Now suppose we wish to handle these missing data under the assumption of MNAR, we would now be conducting a sensitivity analysis because we are still targeting the same estimand, but only varying the assumptions. The question / target remain the same. To handle missing data that we assume are MNAR, there are a number of different and complex approaches.
We start off with the \(\delta\)-adjustment, controlled multiple imputation method,23 in which we assume that the group with missing observations differs systematically from the group with complete observations by a certain quantity. We produce a range of these quantities and add or subtract them from the imputed values and then conduct our analysis on this adjusted, imputed dataset. Here I will make the assumption that the average PostDBP estimate from the missing value group differs from at least 0 mmHg to at most 20 mmHg from the group with no missing observations.
Code
# Controlled MI
ini <- mice(BP_miss,
method = "pmm", maxit = 0,
predictorMatrix = pred
)
ini$method["BaselineDBP"] <- ""
ini$method["PostDBP"] <- "pmm"
ini$method["Age"] <- ""
ini$method["R1"] <- ""
ini$method["Group"] <- ""
ini$method["R2"] <- ""
ini$method["Z"] <- ""
meth <- ini$method
delta <- seq(-20, 20, 5)
imp.all <- vector("list", length(delta))
post <- ini$post
for (i in 1:length(delta)) {
d <- delta[i]
cmd <- paste("imp[[j]][, i] <- imp[[j]][, i] +", d)
post["PostDBP"] <- cmd
imp <- mice(BP_miss,
method = meth,
predictorMatrix = pred,
m = 5, maxit = 1, donors = 5,
cores = cores, ridge = 0, formulas = form,
remove.collinear = TRUE,
remove.constant = TRUE,
allow.na = TRUE, post = post,
printFlag = FALSE
)
imp.all[[i]] <- imp
}Code
for (i in 1:length(delta)) {
imp.all[[i]][["data"]][["Group"]] <- as.factor(imp.all[[i]][["data"]][["Group"]])
}Now that we have our imputed datasets that are modified by \(\delta\)-adjustments, we can fit our models to each imputed dataset and combine the estimates using Rubin’s rules.
Code
# Sensitivity Analysis 1
output <- sapply(imp.all,
function(x) {
mice::pool(with(
x,
rlm(
PostDBP ~ factor(Group) +
BaselineDBP + Age + Z + R1 + R2,
method = "MM", psi = psi.huber
)
))
},
simplify = "array", USE.NAMES = TRUE
)
a <- (as.data.frame(t(output)))$pooled
r <- array(rep(NA, length(delta) * 7),
dim = c(length(delta), 7),
dimnames = list(
c(delta),
c(
"Intercept", "Group",
"BaselineDBP", "Age",
"Z", "R1", "R2"
)
)
)
for (i in 1:length(delta)) {
r[i, ] <- cbind(a[[i]][["estimate"]])
}
r <- as.data.frame(r)
r <- data.frame(Delta = row.names(r), r, row.names = NULL)| Delta | Intercept | Group | BaselineDBP | Age | Z | R1 | R2 |
|---|---|---|---|---|---|---|---|
| -20 | -108.42 | -11.79 | 1.96 | 0.30 | -3.49 | 0.13 | -1.10 |
| -15 | -50.97 | -10.66 | 1.47 | 0.31 | -2.35 | 0.07 | -0.62 |
| -10 | -27.79 | -10.22 | 1.29 | 0.31 | -1.82 | 0.04 | -0.44 |
| -5 | -6.65 | -9.83 | 1.12 | 0.33 | -1.35 | 0.03 | -0.33 |
| 0 | 12.68 | -9.54 | 0.97 | 0.33 | -0.92 | -0.04 | -0.17 |
| 5 | 31.46 | -9.16 | 0.83 | 0.33 | -0.83 | -0.08 | -0.09 |
| 10 | 50.77 | -8.84 | 0.68 | 0.34 | -0.11 | -0.05 | 0.06 |
| 15 | 77.47 | -8.33 | 0.47 | 0.34 | 0.10 | -0.08 | 0.21 |
| 20 | 141.67 | -7.13 | -0.08 | 0.35 | 2.46 | -0.15 | 0.76 |
The table above gives the various \(\delta\)’s (the first column with values ranging from -30 - 30 in increments of 5) that were added to the multiply imputed datasets, and the corresponding estimates from the models fit to those datasets. So now we’ve conducted our first sensitivity analysis using the \(\delta\)-adjustment, controlled multiple imputation method. This form of sensitivity analysis is also typically what is used and preferred by regulators.23
Regulators prefer simple methods that impute the missing outcomes under MAR, and then add an adjustment δ to the imputes, while varying δ over a plausible range and independently for each treatment group (Permutt 2016).
The most interesting scenarios will be those where the difference between the δ’s correspond to the size of the treatment effect in the completers. Contours of the p-values may be plotted on a graph as a function of the δ’s to assist in a tipping-point analysis (Liublinska and Rubin 2014).
And as expected, lower \(\delta\) values gave us results that were consistent with the primary analysis, while the upper end of the extreme \(\delta\) values gave us estimates that were substantially off the mark.
Next, we quickly examine the state of a random sample of these imputations to make sure they’re reliable.
#> Error:
#> ! object 'aesthetics' not foundNow we move onto our next and final sensitivity analysis.
SA II: Selection Models
To further explore the MNAR assumption, we could also use a Heckman selection model \(P(Y,R)=P(Y)P(R|Y)\), as described by van Buuren here20
The selection model multiplies the marginal distribution \(P(Y)\) in the population with the response weights \(P(R|Y)\). Both \(P(Y)\) and \(P(R|Y)\) are unknown, and must be specified by the user. The model where \(P(Y)\) is normal and where \(P(R|Y)\) is a probit model is known as the Heckman model. This model is widely used in economics to correct for selection bias.
We can implement this in R using the miceMNAR package, which is an extension to the mice R package.
Code
# Selection Models
has_miceMNAR <- requireNamespace("miceMNAR", quietly = TRUE)
has_mnar_api <- FALSE
if (has_miceMNAR) {
miceMNAR_exports <- getNamespaceExports("miceMNAR")
has_mnar_api <- all(c("generate_JointModelEq", "MNARargument") %in% miceMNAR_exports)
}
if (!has_mnar_api) {
message(
"Skipping SA II (selection model): 'miceMNAR' with generate_JointModelEq/MNARargument is unavailable in this environment."
)
imp2 <- NULL
} else {
JointModelEq <- miceMNAR::generate_JointModelEq(
data = BP_miss,
varMNAR = "PostDBP"
)
JointModelEq[, "PostDBP_var_sel"] <- c(0, 1, 1, 1, 1, 1, 1)
JointModelEq[, "PostDBP_var_out"] <- c(0, 1, 1, 1, 0, 1, 1)
arg <- miceMNAR::MNARargument(
data = BP_miss,
varMNAR = "PostDBP",
JointModelEq = JointModelEq
)
imp2 <- mice(
data = arg$data_mod,
method = "pmm", seed = 1031,
predictorMatrix = arg$predictorMatrix,
JointModelEq = arg$JointModelEq,
control = arg$control,
remove.collinear = TRUE,
remove.constant = FALSE, allow.na = FALSE,
printFlag = FALSE, visitSequence = "monotone"
)
imp2$data$Group <- as.factor(imp2$data$Group)
}#> Selection-model diagnostics skipped because `imp2` was not created.\nNow we fit our models to these new datasets and pool them using Rubin’s rules.
Code
# Sensitivity Analysis 2
if (is.null(imp2)) {
analysis3 <- NULL
result3 <- NULL
results3_sum <- data.frame(
Term = character(),
Estimate = numeric(),
SE = numeric(),
Statistic = numeric(),
df = numeric(),
`P-val` = numeric()
)
} else {
analysis3 <- with(imp2, rlm(
PostDBP ~ factor(Group) +
BaselineDBP + Age + Z + R1 + R2,
method = "MM", psi = psi.huber
))
result3 <- mice::pool(analysis3)
results3_sum <- summary(result3)
colnames(results3_sum) <- c(
"Term", "Estimate", "SE",
"Statistic", "df", "P-val"
)
}#> Selection-model pooled results unavailable in this environment.\nNow we examine our imputed values.
#> Imputed-values diagnostic skipped because selection-model fit was unavailable.\nso now we have completed our second sensitivity analysis.
The results from both the primary analysis, the first sensitivity analysis, and the second seem somewhat consistent. However, with the first sensitivity analysis where we applied \(\delta\)-adjustments, as the adjustments became larger, the coefficients changed drastically. However, such large \(\delta\)-adjustments are not realistic and those that were smaller led to coefficients that were closer to the other two analyses.
Supplementary Analyses
The following analyses are what I mostly consider to be supplementary analyses that may further investigate some violations of assumptions but often go far beyond what would be necessary for a principled sensitivity analysis that would typically accompany a primary analysis.
First, I like to check that the results from my analyses are consistent across different statistical software So I may check to see that the results from my primary analysis from R are also similar to the results from another statistical software suite like Stata.
So in Stata, I would likely run something similar to the following in order to mimic the primary analysis in R.
Code
set linesize 255
clear all
set seed 1031
parallel setclusters 8, statapath(/Applications/Stata)
parallel initialize 8, statapath(/Applications/Stata)
import delimited "static/datasets/temp.csv", numericcols(2 3 5 6 7 8)
summarize
mi set mlong
mi register imputed baselinedbp postdbp age z group r1 r2
mi impute chained (pmm, knn(5)) postdbp = baselinedbp age z r1 r2 group, burnin(20) add(100) rseed (1031) savetrace(trace1, replace) nomonotone
mi estimate, mcerror: rreg postdbp i.group baselinedbp age z r1 r2
quietly mi passive: generate byte imputed = _mi_miss
#> Can not set Stata directory, try using -statapath(
#> > )- option
#> r(601);
#>
#>
#>
#>
#>
#> N Clusters: 8
#> Can not set Stata directory, try using -statapath()- option
#> r(601);
#>
#> r(601);#> Can not set Stata directory, try using -statapath(
#> > )- option
#> r(601);
#>
#>
#>
#> (Summaries of imputed values from -mi impute chained-)
#>
#>
#> Contains data from trace1.dta
#> Observations: 2,100 Summaries of imputed values from -mi impute chained-
#> Variables: 4 6 Sep 2025 17:50
#> ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
#> Variable Storage Display Value
#> name type format label Variable label
#> ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
#> iter byte %12.0g Iteration numbers
#> m byte %12.0g Imputation numbers
#> postdbp_mean float %9.0g Mean of postdbp
#> postdbp_sd float %9.0g Std. dev. of postdbp
#> ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
#> Sorted by:
#>
#>
#>
#> reshaping m=0 data ...
#> (j = 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 8
#> > 7 88 89 90 91 92 93 94 95 96 97 98 99 100)
#>
#> Data Long -> Wide
#> -----------------------------------------------------------------------------
#> Number of observations 2,100 -> 21
#> Number of variables 4 -> 201
#> j variable (100 values) m -> (dropped)
#> xij variables:
#> postdbp_mean -> postdbp_mean1 postdbp_mean2 ... postdbp_mean100
#> postdbp_sd -> postdbp_sd1 postdbp_sd2 ... postdbp_sd100
#> -----------------------------------------------------------------------------
#>
#> assembling results ...
#>
#>
#> Time variable: iter, 0 to 20
#> Delta: 1 unit
#>
#>
#>
#>
#> file traceplot.svg saved as SVG format
As you can see from above, I imported the missing data I generated in R into Stata, and then used it to multiply impute the datasets using the predictive mean matching method with 5 donors. I chose the exact same number of variables to include in the imputation model as I did with the primary and sensitivity analyses. Just like the primary analysis, I also used robust regression, rreg in Stata, to analyze the datasets. The numbers seem to be fairly consistent with those from the primary analysis and the some of the results from the sensitivity analyses.
I will now conduct another supplementary analysis, in which I fit a Bayesian regression model using a t-distribution so that it is analogous to the other robust regression models I have utilized so far, and I will specify a weakly informative prior. I will fit one model using the brm_multiple() function which will fit the model to each of the imputed datasets from before, while I fit another Bayesian model which will impute values during the model fitting process and compare the results.
Code
# Quantile Regression --------------------------
implist <- mitml::mids2mitml.list(imp1)
vcov.rq <- function(object, ...) {
summary(object,
se = "nid",
covariance = TRUE
)$cov
}
fit1 <- with(implist, rq(PostDBP ~ factor(Group) + BaselineDBP +
Age + Z + R1 + R2, tau = 0.5))
mitml::testEstimates(fit1)
#>
#> Call:
#>
#> mitml::testEstimates(model = fit1)
#>
#> Final parameter estimates and inferences obtained from 52 imputed data sets.
#>
#> Estimate Std.Error t.value df P(>|t|) RIV FMI
#> (Intercept) 11.851 6.252 1.895 303.853 0.059 0.694 0.414
#> factor(Group)Drug Y -9.427 0.171 -55.141 193.044 0.000 1.058 0.519
#> BaselineDBP 0.976 0.054 18.154 290.286 0.000 0.722 0.423
#> Age 0.335 0.011 31.092 313.392 0.000 0.676 0.407
#> Z -0.991 1.760 -0.563 260.180 0.574 0.794 0.447
#> R1 -0.027 0.091 -0.301 179.278 0.764 1.143 0.538
#> R2 -0.114 0.173 -0.660 157.378 0.510 1.322 0.575
#>
#> Unadjusted hypothesis test as appropriate in larger samples.
confint(mitml::testEstimates(fit1))
#> 2.5 % 97.5 %
#> (Intercept) -0.452 24.154
#> factor(Group)Drug Y -9.764 -9.090
#> BaselineDBP 0.870 1.082
#> Age 0.314 0.356
#> Z -4.456 2.475
#> R1 -0.207 0.153
#> R2 -0.455 0.227Code
# Bayesian Regression --------------------------
BP_miss$Group <- as.factor(BP_miss$Group)
brm_form2 <- bf(
PostDBP | mi() ~ factor(Group) + BaselineDBP +
Age + Z + R1 + R2, quantile = 0.50
)
prior1 <- get_prior(brm_form2, data = BP_miss, knots = 4,
family = asym_laplace(link = 'identity'))
b_2 <- brm(formula = brm_form2, data = BP_miss, prior = prior1,
family = asym_laplace(link = 'identity'), sample_prior = 'yes',
control = list(max_treedepth = 10, adapt_delta = 0.80),
iter = 2000, refresh = 0, backend = chains = 4,
algorithm = "sampling", knots = 4, future = FALSE, cores = 8L,
warmup = 500, seed = 1031)Code
post <- summary(b_2)[]
#> Error in `h()`:
#> ! error in evaluating the argument 'object' in selecting a method for function 'summary': object 'b_2' not found
summary(b_2)
#> Error in `h()`:
#> ! error in evaluating the argument 'object' in selecting a method for function 'summary': object 'b_2' not foundWe can also compare the results we get from brms/Stan with MCMCpack.
Code
posterior_95 <- MCMCquantreg(
PostDBP ~ factor(Group) + BaselineDBP +
Age + Z + R1 + R2,
data = BP_miss,
tau = 0.95, mcmc = 5000, chains = 4,
thin = 10, seed = 1031
)
summary(posterior_95)
#>
#> Iterations = 1001:5991
#> Thinning interval = 10
#> Number of chains = 1
#> Sample size per chain = 500
#>
#> 1. Empirical mean and standard deviation for each variable,
#> plus standard error of the mean:
#>
#> Mean SD Naive SE Time-series SE
#> (Intercept) 10.2441 19.8021 0.88558 1.00205
#> factor(Group)Drug Y -9.6451 0.4329 0.01936 0.02600
#> BaselineDBP 1.0197 0.1688 0.00755 0.00855
#> Age 0.3108 0.0324 0.00145 0.00156
#> Z -3.0856 5.6527 0.25279 0.27623
#> R1 -0.0277 0.2696 0.01206 0.01383
#> R2 -0.4040 0.3937 0.01761 0.01950
#>
#> 2. Quantiles for each variable:
#>
#> 2.5% 25% 50% 75% 97.5%
#> (Intercept) -27.035 -2.560 9.2822 22.020 49.797
#> factor(Group)Drug Y -10.572 -9.916 -9.6297 -9.350 -8.846
#> BaselineDBP 0.679 0.918 1.0263 1.130 1.338
#> Age 0.253 0.290 0.3094 0.332 0.375
#> Z -14.438 -6.933 -3.3466 1.069 7.636
#> R1 -0.550 -0.214 -0.0152 0.146 0.507
#> R2 -1.189 -0.646 -0.3728 -0.158 0.312Next, we examine the results from the Bayesian model in which values were imputed during model fitting.
Code
posterior_summary(b_2)[1:8]
(post <- posterior_samples(b_2))They seem to be similar to the results we’ve been seeing so far.
Indeed, it is no surprise that the Bayesian model with a weakly dispersed prior would give similar results to the base rlm() function. We now look at robust methods and resampling and the results they give.
Although this is currently under the supplementary analysis section, I would very much consider these next two analyses to be sensitivity analyses. The first method utilized here is known as the random indicator method, and it is an experimental method that essentially combines a selection model and a pattern-mixture model and is designed to handle data that are missing not at random. As van Buuren writes20
The random indicator method (Jolani 2012)24 is an experimental iterative method that redraws the missing data indicator under a selection model, and imputes the missing data under a pattern-mixture model, with the objective of estimating δ from the data under relaxed assumptions. Initial simulation results look promising. The algorithm is available as the
rimethod inmice.
The script below utilizes this method (random indicator), but bootstraps the missing dataset before the imputation procedure, and then after multiply imputing the datasets, obtains estimates using maximum likelihood multiple (MLMI) imputation, an alternative and more efficient method to the more popular posterior draw multiple imputation (PDMI). More about MLMI can be found here.25
Code
# Bootstrap Inference
bootMice(BP_miss, method = "ri", maxit = 5,
predictorMatrix = pred, nBoot = 96, nImp = 2,
seed = 1031, formulas = form, nCores = 8L,
ridge = 0, remove.collinear = TRUE,
remove.constant = TRUE, allow.na = TRUE,
printFlag = FALSE, visitSequence = "monotone") -> imps
analyseImp <- function(inputData) {
return(coef(rlm(PostDBP ~ factor(Group) + BaselineDBP + Age + Z + R1 + R2,
data = inputData, method = "MM", psi = psi.huber
)))
}
analyseImp1 <- function(inputData) {
return(coef(glm(PostDBP ~ factor(Group) + BaselineDBP + Age + Z + R1 + R2,
data = inputData, family = gaussian()
)))
}
ests <- bootImputeAnalyse(imps, analyseImp, quiet = TRUE)
ests1 <- bootImputeAnalyse(imps, analyseImp1, quiet = TRUE)
ests <- as.data.frame(ests)
colnames(ests) <- c("Estimate", "Var",
"CI.ll", "CI.ul", "df")
rownames(ests) <- c("Intercept", "Group", "BaselineDBP",
"Age", "Z", "R1", "R2")
ests1 <- as.data.frame(ests1)
colnames(ests1) <- c("Estimate", "Var",
"CI.ll", "CI.ul", "df")
rownames(ests1) <- c("Intercept", "Group", "BaselineDBP",
"Age", "Z", "R1", "R2")| Estimate | Var | CI.ll | CI.ul | df | |
|---|---|---|---|---|---|
| Intercept | 10.72 | 16.51 | 2.19 | 19.25 | 18.3 |
| Group | -9.62 | 0.02 | -9.89 | -9.34 | 48.0 |
| BaselineDBP | 0.99 | 0.00 | 0.91 | 1.06 | 19.6 |
| Age | 0.34 | 0.00 | 0.32 | 0.36 | 55.4 |
| Z | -1.00 | 2.32 | -4.06 | 2.05 | 51.2 |
| R1 | -0.02 | 0.01 | -0.19 | 0.15 | 64.3 |
| R2 | -0.14 | 0.02 | -0.39 | 0.11 | 44.8 |
| Estimate | Var | CI.ll | CI.ul | df | |
|---|---|---|---|---|---|
| Intercept | 10.37 | 16.67 | 1.84 | 18.89 | 19.7 |
| Group | -9.63 | 0.02 | -9.89 | -9.36 | 47.5 |
| BaselineDBP | 0.99 | 0.00 | 0.92 | 1.06 | 20.7 |
| Age | 0.33 | 0.00 | 0.31 | 0.35 | 57.3 |
| Z | -1.02 | 2.21 | -4.00 | 1.96 | 50.1 |
| R1 | -0.02 | 0.01 | -0.18 | 0.15 | 62.6 |
| R2 | -0.15 | 0.01 | -0.39 | 0.09 | 43.3 |
For our second supplementary analysis, We will utilize the GAMLSS method, which is an extension of the generalized linear model and the generalized additive model. For the vast majority of the imputations we have conducted, we have drawn values from an assumed normal distribution. Thus, GAMLSS allows us to be far more flexible with our assumptions. However, it is also worth noting that general normal imputations are robust against violations of the assumption of normality
In general, normal imputations appear to be robust against violations of normality. Demirtas, Freels, and Yucel (2008) found that flatness of the density, heavy tails, non-zero peakedness, skewness and multimodality do not appear to hamper the good performance of multiple imputation for the mean structure in samples n > 400, even for high percentages (75%) of missing data in one variable. The variance parameter is more critical though, and could be off-target in smaller samples.
Regardless, we will be using the GAMLSS method and also imputing from a t-distribution, which is much more robust to outliers.
Code
gamt <- mice(BP_miss, method = "gamlssTF",
predictorMatrix = pred,
m = 5, maxit = 1, seed = 1031,
cores = cores, formulas = form, ridge = 0,
remove.collinear = TRUE, remove.constant = TRUE,
allow.na = TRUE, printFlag = FALSE)
gt1 <- with(gamt, rlm(PostDBP ~ factor(Group) +
BaselineDBP + Age +
Z + R1 + R2))
resultsgt <- mice::pool(gt1)Code
ztable(summary(resultsgt))| term | estimate | std.error | statistic | df | p.value |
|---|---|---|---|---|---|
| (Intercept) | 13.23 | 4.95 | 2.67 | NA | NA |
| factor(Group)Drug Y | -9.52 | 0.13 | -76.02 | NA | NA |
| BaselineDBP | 0.97 | 0.04 | 23.48 | NA | NA |
| Age | 0.32 | 0.01 | 35.44 | NA | NA |
| Z | -0.62 | 1.39 | -0.44 | NA | NA |
| R1 | -0.02 | 0.07 | -0.34 | NA | NA |
| R2 | -0.14 | 0.10 | -1.35 | NA | NA |
Having done that, I shall try one more supplementary analysis which piqued my curiosity. I recently came across a few papers that concluded that random forests outperformed other imputation algorithms in recovering the true parameter values.
Generally, imputation algorithms are evaluated based on a general simulation design which often resembles the following:
- Sampling mechanism only. The basic simulation steps are: choose \(Q\), take samples \(Y^{(s)}\), fit the complete-data model, estimate \(\hat{Q}^{(s)}\) and \(U^{(s)}\) and calculate the outcomes aggregated over \(s\).
- Sampling and missing data mechanisms combined. The basic simulation steps are: choose \(Q\), take samples \(Y^{(s)}\), generate incomplete data \(Y_{\mathrm{obs}}^{(s, t)}\), impute, estimate \(\hat{Q}^{(s, t)}\) and \(T^{(s, t)}\) and calculate outcomes aggregated over \(s\) and \(t\).
- Missing data mechanism only. The basic simulation steps are: choose \((\hat{Q}, U)\), generate incomplete data \(Y_{o b s}^{(t)}\), impute, estimate \((Q, U)^{(t)}\) and \(B^{(t)}\) and calculate outcomes aggregated over \(t\).
These designs generally lead to evaluating a number of metrics which include the following:
- Raw Bias: where \(RB\) is bias and \(Q\) is the difference between the estimate and the truth \(RB=E(Q)-Q\), which may also be expressed as a percent \(100*\frac{RB=E(Q)-Q}{Q}\)
- Coverage Rate: which is simply the proportion of times the intervals actually contain the true parameter value
- Average Width: the width of the interval estimates, with longer widths indicating less information
- Root mean squared error (RMSE) \(\operatorname{RMSE}=\sqrt{\frac{1}{n_{\text {mis }}} \sum_{i=1}^{n_{\text {mits }}}\left(y_{i}^{\text {mis }}-\dot{y}_{i}\right)^{2}}\)
The authors primarily based their conclusions on the root mean squared error (RMSE). However, this is problematic for a number of reasons; imputation is not the same as prediction, and so the same loss functions are not as useful; indeed, the RMSE is highly misleading as a measure of performance.
van Buuren explains here:
It is well known that the minimum RMSE is attained by predicting the missing \(\dot{{y}}_{i}\) by the linear model with the regression weights set to their least squares estimates. According to this reasoning the “best” method replaces each missing value by its most likely value under the model. However, this will find the same values over and over, and is single imputation.
This method ignores the inherent uncertainty of the missing values (and acts as if they were known after all), resulting in biased estimates and invalid statistical inferences. Hence, the method yielding the lowest RMSE is bad for imputation. More generally, measures based on similarity between the true and imputed values do not separate valid from invalid imputation methods.
Having set up our simulation design, we can now test the performances between regression imputation norm.predict and and regular regression imputation norm and we will be examining the metrics above to evaluate performance. Regression imputation generally gives very biased results given that it uses its predictions to impute the missing values. Thus, I will show here how RMSE is highly misleading as a metric to evaluate the performance of imputation algorithms.
Code
# Evaluate MI Algorithms
create.data <- function(beta = 1, sigma2 = 1, n = 500,
run = 1) {
set.seed(seed = run)
x <- rnorm(n)
y <- beta * x + rnorm(n, sd = sqrt(sigma2))
cbind(x = x, y = y)
}
make.missing <- function(data, p = 0.5) {
rx <- rbinom(nrow(data), 1, p)
data[rx == 0, "x"] <- NA
data
}
test.impute <- function(data, m = 5, method = "norm", ...) {
imp <- mice(data,
method = method, m = m,
print = FALSE, cores = cores, ...
)
fit <- with(imp, lm(y ~ x))
tab <- summary(mice::pool(fit), "all", conf.int = TRUE)
as.numeric(tab["x", c("estimate", "2.5 %", "97.5 %")])
}
rmse <- function(truedata, imp, v = "x") {
mx <- is.na(mice::complete(imp, 0))[, v]
mse <- rep(NA, imp$m)
for (k in seq_len(imp$m)) {
filled <- mice::complete(imp, k)[mx, v]
true <- truedata[mx, v]
mse[k] <- mean((filled - true)^2)
}
sqrt(mean(mse))
}
mae <- function(truedata, imp, v = "x") {
mx <- is.na(mice::complete(imp, 0))[, v]
mse <- rep(NA, imp$m)
for (k in seq_len(imp$m)) {
filled <- mice::complete(imp, k)[mx, v]
true <- truedata[mx, v]
mse[k] <- mean((filled - true))
}
abs(mean(mse))
}
simulate1 <- function(runs = 10) {
res <- array(NA, dim = c(2, runs, 1))
dimnames(res) <- list(
c("norm.predict", "norm"),
as.character(1:runs),
"MAE"
)
for (run in 1:runs) {
truedata <- create.data(run = run)
data <- make.missing(truedata)
imp <- mice(data,
method = "norm.predict",
m = 1, cores = cores,
print = FALSE
)
res[1, run, ] <- mae(truedata, imp)
imp <- mice(data, method = "norm", print = FALSE)
res[2, run, ] <- mae(truedata, imp)
}
res
}
simulate2 <- function(runs = 10) {
res <- array(NA, dim = c(2, runs, 1))
dimnames(res) <- list(
c("norm.predict", "norm"),
as.character(1:runs),
"RMSE"
)
for (run in 1:runs) {
truedata <- create.data(run = run)
data <- make.missing(truedata)
imp <- mice(data,
method = "norm.predict",
m = 1, cores = cores,
print = FALSE
)
res[1, run, ] <- rmse(truedata, imp)
imp <- mice(data, method = "norm", print = FALSE)
res[2, run, ] <- rmse(truedata, imp)
}
res
}Our simulation above will generate a dataset, delete values from the dataset and then impute the missing values for that dataset using regression imputation and stochastic regression imputation. We will use two metrics to evaluate the performance of these two algorithms, RMSE and MAE. Once again, it is worth keeping in mind that regression imputation generally performs very poorly when it comes to imputation and that stochastic regression imputation performs better.
Code
set.seed(1031,
kind = "L'Ecuyer-CMRG",
normal.kind = "Inversion",
sample.kind = "Rejection"
)
res1 <- simulate1(1000)
res_1 <- apply(res1, c(1, 3),
mean,
na.rm = TRUE
)
res2 <- simulate2(1000)
res_2 <- apply(res2, c(1, 3),
mean,
na.rm = TRUE
)
ztable(cbind(res_1, res_2))What this simulation clearly shows is that despite regression imputation norm.predict giving highly biased results as usual relative to the truth, it still has a much lower RMSE than stochastic regression imputation, which both had a higher RMSE and a closer distance to the correct parameter values. Once again, this is not surprising given that imputation is not the same thing as prediction and therefore the loss functions cannot be used synonymously. However, when it came to raw bias and mean absolute error, stochastic regression imputation outperformed regression imputation which had a much larger mean absolute error and raw bias.
This is why the most informative metrics to focus on when evaluating an imputation algorithm include information/width, sufficient long-run coverage, and less misleading metrics such as mean absolute error and mean absolute percentage error.
The authors specifically used the missForest package. I tried using the package, but encountered too many difficulties so I simply specified the rf method in mice, and worked from there.
Code
# MI Using Random Forest
form <- list(PostDBP ~ factor(Group) + BaselineDBP + Age + Z + R1 + R2)
rf <- parlmice(BP_miss,
method = "rf", ntree = 20,
predictorMatrix = pred,
m = 10, maxit = 5, cluster.seed = 1031,
cores = cores, formulas = form, ridge = 0,
remove.collinear = TRUE, remove.constant = TRUE,
allow.na = TRUE, printFlag = FALSE,
visitSequence = "monotone"
)
rf1 <- with(rf, rlm(PostDBP ~ factor(Group) +
BaselineDBP + Age +
Z + R1 + R2))
results5 <- mice::pool(rf1)
results5_sum <- summary(results5)
colnames(results5_sum) <- c(
"Term", "Estimate", "SE",
"Statistic", "df", "P-val"
)
ztable(results5_sum)| Term | Estimate | SE | Statistic | df | P-val |
|---|---|---|---|---|---|
| (Intercept) | 37.67 | 7.30 | 5.16 | NA | NA |
| factor(Group)Drug Y | -9.30 | 0.18 | -50.41 | NA | NA |
| BaselineDBP | 0.78 | 0.06 | 12.40 | NA | NA |
| Age | 0.28 | 0.01 | 20.44 | NA | NA |
| Z | 1.17 | 2.14 | 0.55 | NA | NA |
| R1 | 0.01 | 0.09 | 0.15 | NA | NA |
| R2 | -0.02 | 0.19 | -0.12 | NA | NA |
Full Analysis Set
After we run all those analyses, we can finally check our numbers from the full dataset with no missing observations to see how our approaches to handle the missing data have performed. We first look at the fully adjusted model fit with rlm().
Code
# Full Analysis Set
final_full_mod <- rlm(
PostDBP ~ factor(Group) + BaselineDBP +
Age + Z + R1 + R2,
data = BP_full,
method = "MM", psi = psi.huber
)| Value | Std. Error | t value | |
|---|---|---|---|
| (Intercept) | 9.19 | 3.72 | 2.47 |
| factor(Group)Drug Y | -9.66 | 0.09 | -106.85 |
| BaselineDBP | 1.00 | 0.03 | 31.68 |
| Age | 0.33 | 0.01 | 50.17 |
| Z | -2.02 | 1.01 | -2.00 |
| R1 | 0.01 | 0.05 | 0.21 |
| R2 | -0.01 | 0.09 | -0.09 |
| Term | VIF | VIF_CI_low | VIF_CI_high | SE_factor | Tolerance | Tolerance_CI_low | Tolerance_CI_high |
|---|---|---|---|---|---|---|---|
| factor(Group) | 1.01 | 1.00 | 489.74 | 1.00 | 0.99 | 0.00 | 1.00 |
| BaselineDBP | 1.97 | 1.75 | 2.26 | 1.40 | 0.51 | 0.44 | 0.57 |
| Age | 1.02 | 1.00 | 4.09 | 1.01 | 0.98 | 0.24 | 1.00 |
| Z | 1.98 | 1.75 | 2.27 | 1.41 | 0.51 | 0.44 | 0.57 |
| R1 | 1.01 | 1.00 | 33.65 | 1.01 | 0.99 | 0.03 | 1.00 |
| R2 | 1.01 | 1.00 | 1603.17 | 1.00 | 0.99 | 0.00 | 1.00 |
We can also graphically inspect our assumptions.
Then we look at the unadjusted model, where the difference is the group that the participants were randomized to.
Code
# Unadjusted Model
final_reduced_mod <- rlm(PostDBP ~ factor(Group),
data = BP_full,
method = "MM", psi = psi.huber
)
final_reduced_mod_sum <- summary(final_reduced_mod)[["coefficients"]]
colnames(final_reduced_mod_sum) <- c(
"Value",
"Std. Error",
"t-value"
)| Value | Std. Error | t-value | |
|---|---|---|---|
| (Intercept) | 142.6 | 0.20 | 728.8 |
| factor(Group)Drug Y | -9.2 | 0.28 | -32.7 |
We can also compare the two to see if there are any substantial differences.
| Name | Model | AIC | AIC_wt | AICc | AICc_wt | BIC | BIC_wt | RMSE | Sigma |
|---|---|---|---|---|---|---|---|---|---|
| final_full_mod | rlm | 1420 | 1 | 1420 | 1 | 1453 | 1 | 0.98 | 0.99 |
| final_reduced_mod | rlm | 2556 | 0 | 2557 | 0 | 2569 | 0 | 3.10 | 3.11 |
While the results have mostly been consistent, I also wanted to run a few additional analyses of my own to see whether these effect estimates were consistent I first started by constructing the confidence distribution using the concurve package to see the range of parameter values consistent with the data given the background model assumptions.26, 27
Code
# Compatibility of Values
fit1 <- glm(
PostDBP ~ factor(Group) + BaselineDBP +
Age + Z + R1 + R2,
data = BP_full, family = gaussian()
)
summary(fit1)
#>
#> Call:
#> glm(formula = PostDBP ~ factor(Group) + BaselineDBP + Age + Z +
#> R1 + R2, family = gaussian(), data = BP_full)
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 9.02736 3.65879 2.47 0.014 *
#> factor(Group)Drug Y -9.64556 0.08906 -108.30 <2e-16 ***
#> BaselineDBP 1.00567 0.03120 32.23 <2e-16 ***
#> Age 0.32696 0.00645 50.69 <2e-16 ***
#> Z -1.97391 0.99551 -1.98 0.048 *
#> R1 0.01071 0.04711 0.23 0.820
#> R2 -0.02493 0.08799 -0.28 0.777
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
#> (Dispersion parameter for gaussian family taken to be 0.983)
#>
#> Null deviance: 15519.32 on 499 degrees of freedom
#> Residual deviance: 484.49 on 493 degrees of freedom
#> AIC: 1419
#>
#> Number of Fisher Scoring iterations: 2
fit2 <- glm(PostDBP ~ factor(Group),
data = BP_full, family = gaussian()
)
summary(fit2)
#>
#> Call:
#> glm(formula = PostDBP ~ factor(Group), family = gaussian(), data = BP_full)
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 142.596 0.193 737.3 <2e-16 ***
#> factor(Group)Drug Y -9.263 0.278 -33.3 <2e-16 ***
#> ---
#> Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#>
#> (Dispersion parameter for gaussian family taken to be 9.65)
#>
#> Null deviance: 15519.3 on 499 degrees of freedom
#> Residual deviance: 4805.8 on 498 degrees of freedom
#> AIC: 2556
#>
#> Number of Fisher Scoring iterations: 2
curve1 <- curve_gen(fit1,
var = "factor(Group)Drug Y", method = "lm",
log = FALSE, steps = 1000, table = TRUE
)
| Lower Limit | Upper Limit | Interval Width | Interval Level (%) | CDF | P-value | S-value (bits) |
|---|---|---|---|---|---|---|
| -9.67 | -9.62 | 0.057 | 25.0 | 0.625 | 0.750 | 0.415 |
| -9.71 | -9.59 | 0.120 | 50.0 | 0.750 | 0.500 | 1.000 |
| -9.75 | -9.54 | 0.205 | 75.0 | 0.875 | 0.250 | 2.000 |
| -9.76 | -9.53 | 0.228 | 80.0 | 0.900 | 0.200 | 2.322 |
| -9.77 | -9.52 | 0.256 | 85.0 | 0.925 | 0.150 | 2.737 |
| -9.79 | -9.50 | 0.293 | 90.0 | 0.950 | 0.100 | 3.322 |
| -9.82 | -9.47 | 0.349 | 95.0 | 0.975 | 0.050 | 4.322 |
| -9.85 | -9.45 | 0.399 | 97.5 | 0.988 | 0.025 | 5.322 |
| -9.88 | -9.42 | 0.459 | 99.0 | 0.995 | 0.010 | 6.644 |
| Table of Statistics for Various Interval Estimate Percentiles | ||||||
Indeed, our confidence distribution ends up being very similar to our Bayesian posterior distribution for the treatment effect. Under certain situations, the maximum likelihood estimate ends up also being equivalent to the median unbiased estimate. In this case, it happens to be very similar to the maximum a posteriori estimate.
\[C V_{n}(\theta)=1-2\left|H_{n}(\theta)-0.5\right|=2 \min \left\{H_{n}(\theta), 1-H_{n}(\theta)\right\}\]
#> Error:
#> ! object 'b_2' not found
#> Error in `post$fixed`:
#> ! $ operator is invalid for atomic vectorsWe can also check to see that our confidence distribution and posterior distribution are consistent with the profile-likelihood function, which is free of nuisance parameters. The advantage of profiling is allowing us to recover more accurate parameter estimates when there are several nuisance parameters or messy data. Below are implementations in both R and Stata, except this time we do not specify errors from the t-distribution.
Code
analyseImp3 <- function(inputData, i) {
dt <- inputData[i, ]
(coef(glm(PostDBP ~ factor(Group) + BaselineDBP + Age + Z + R1 + R2,
data = dt, family = gaussian()
))[2])
}
bootdist <- boot::boot(
data = BP_full, statistic = analyseImp3,
R = 4000, sim = "ordinary", stype = "i",
parallel = "multicore", ncpus = 8
)
sd <- boot::boot.ci(bootdist, conf = c((1:99) / 100), type = "bca")[4]
A <- sd$bca
qplot((c(A[, 4], A[, 5])), geom = "density", fill = I("#3f8f9b44")) +
theme_less() +
labs(
title = "bCA Bootstrap Density Plot",
x = "'Group' Parameter Value (Treatment Effect mmHg)",
y = "Density"
)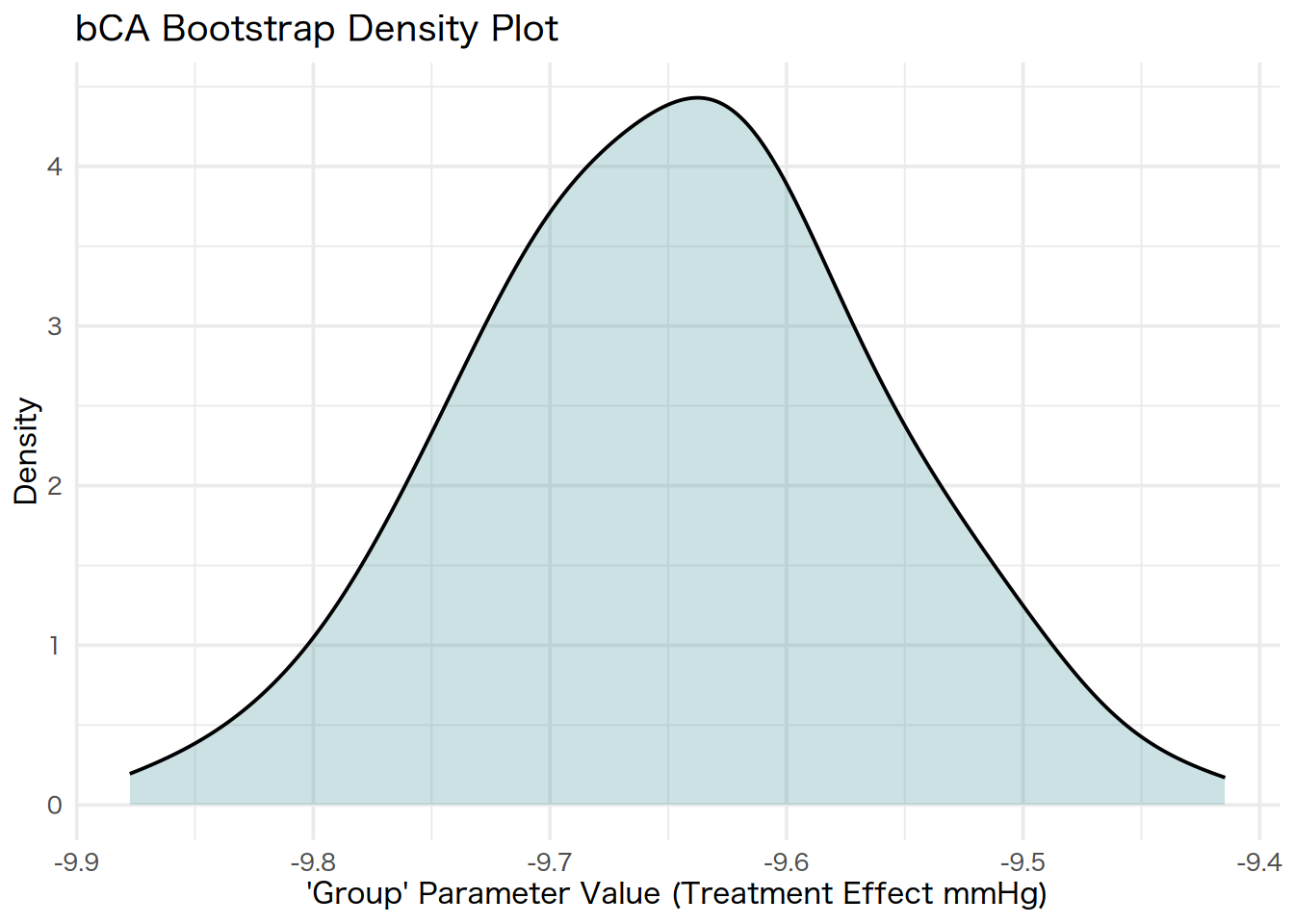
\(L_{t_{n}}(\theta)=f_{n}\left(F_{n}^{-1}\left(H_{p i v}(\theta)\right)\right)\left|\frac{\partial}{\partial t} \psi\left(t_{n}, \theta\right)\right|=h_{p i v}(\theta)\left|\frac{\partial}{\partial t} \psi(t, \theta)\right| /\left.\left|\frac{\partial}{\partial \theta} \psi(t, \theta)\right|\right|_{t=t_{n}}\)
We now focus on profiling on the treatment effect and calculating the profile deviance function. We then multiply our deviance by -0.5 to obtain the profile log-likelihood function.
Code
# Profile Likelihood
prof <- profile(fit1)
disp <- attr(prof, "summary")$dispersion
mindev <- attr(prof, "original.fit")$deviance
dev1 <- prof[[1]]$tau^2
dev2 <- dev1 * disp + mindev
tmpf <- function(x, n) {
data.frame(
par = n, tau = x$tau,
deviance = x$tau^2 * disp + mindev,
x$par.vals, check.names = FALSE
)
}
pp <- do.call(rbind, mapply(tmpf, prof, names(prof),
SIMPLIFY = FALSE
))
pp2 <- melt(pp, id.var = 1:3)
pp3 <- subset(pp2, par == variable, select = -variable)
pp4 <- pp3[-c(1:13), ]
pp4$loglik <- pp4$deviance * -0.5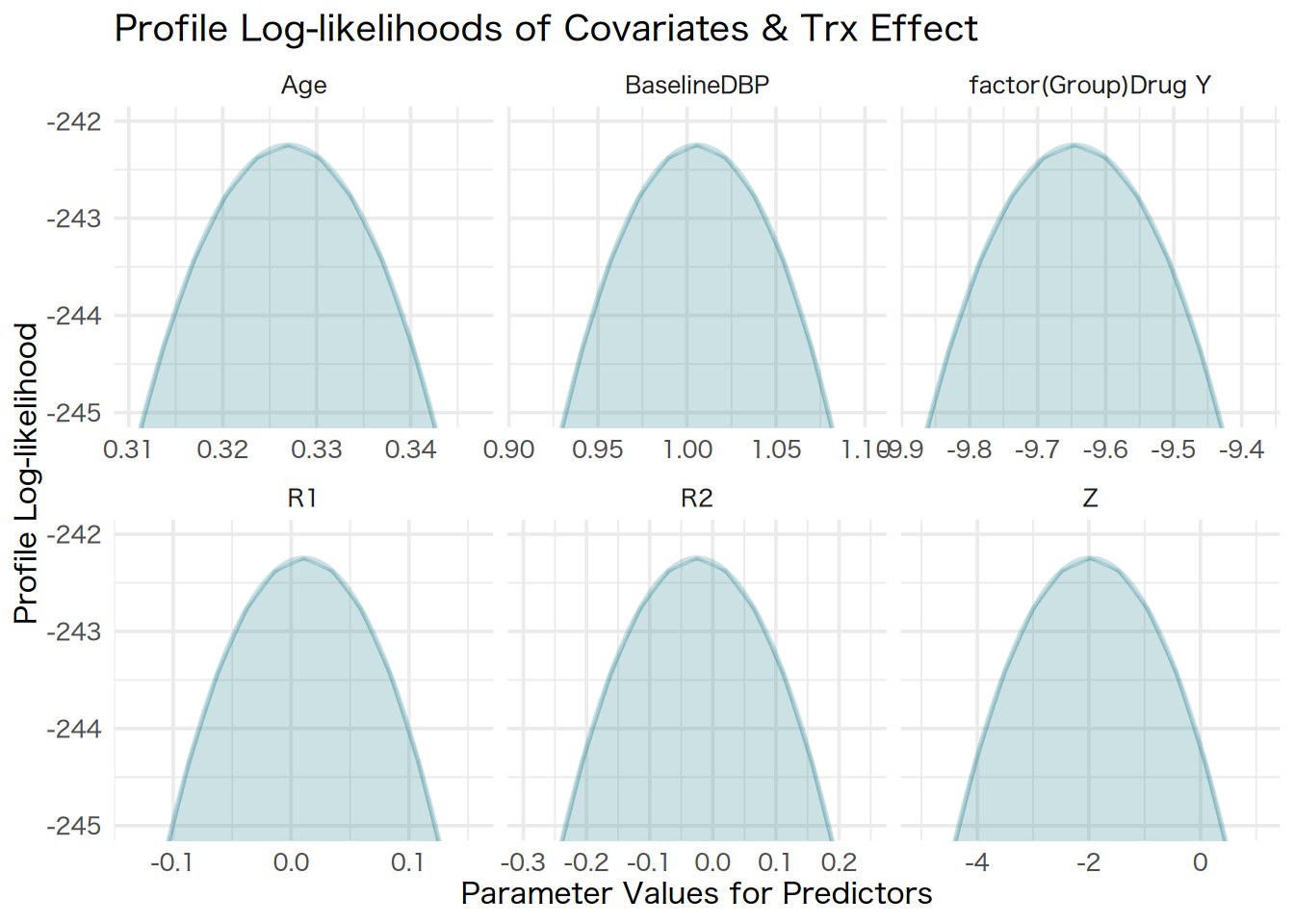
Code
set linesize 255
clear all
set seed 1031
import delimited "static/datasets/temp.csv", numericcols(2 3 5 6 7 8)
foreach var of varlist group baselinedbp age z r1 r2 {
grstyle init
grstyle color background white, opacity(.1)
quietly pllf glm postdbp group baselinedbp age z r1 r2, profile(`var')
graph copy Graph `var'
}
graph combine group baselinedbp age z r1 r2
graph export "loglikfunction.svg", replace
#> Can not set Stata directory, try using -statapath(
#> > )- option
#> r(601);
#>
#>
#>
#>
#>
#> (encoding automatically selected: ISO-8859-2)
#> (7 vars, 500 obs)
#>
#> command grstyle is unrecognized
#> r(199);
#>
#> r(199);| Lower Limit | Upper Limit | CI Width | Level (%) | CDF | P-value | S-value |
|---|---|---|---|---|---|---|
| -9.67 | -9.62 | 0.057 | 25.0 | 0.625 | 0.750 | 0.415 |
| -9.71 | -9.59 | 0.120 | 50.0 | 0.750 | 0.500 | 1.000 |
| -9.75 | -9.54 | 0.205 | 75.0 | 0.875 | 0.250 | 2.000 |
| -9.76 | -9.53 | 0.228 | 80.0 | 0.900 | 0.200 | 2.322 |
| -9.77 | -9.52 | 0.256 | 85.0 | 0.925 | 0.150 | 2.737 |
| -9.79 | -9.50 | 0.293 | 90.0 | 0.950 | 0.100 | 3.322 |
| -9.82 | -9.47 | 0.349 | 95.0 | 0.975 | 0.050 | 4.322 |
| -9.85 | -9.45 | 0.399 | 97.5 | 0.988 | 0.025 | 5.322 |
| -9.88 | -9.42 | 0.459 | 99.0 | 0.995 | 0.010 | 6.644 |
| Table of Statistics for Various Interval Estimate Percentiles | ||||||
I then compared the results of the full analysis set to the results from the primary analysis and sensitivity analyses.
#> Can not set Stata directory, try using -statapath(
#> > )- option
#> r(601);
#>
#>
#>
#>
#>
#> -initialize- invalid parallel subcommand (help parallel)
#> r(198);
#>
#> r(198);Examining the Analyses
#> Error:
#> ! object 'result1' not found
#> Error in `post[["fixed"]]`:
#> ! subscript out of bounds
#> Error:
#> ! object 'pmm' not found
#> Error:
#> ! object 'pmm' not found
#> Error in `mpe_vec()`:
#> ! `estimate` should be a numeric vector, not NULL.
#> Error:
#> ! object 'bayes' not found
#> Error:
#> ! object 'pmm_mpe' not found
#> Error:
#> ! object 'pmm' not found
#> Error in `mae_vec()`:
#> ! `estimate` should be a numeric vector, not NULL.
#> Error:
#> ! object 'bayes' not found
#> Error:
#> ! object 'pmm_mae' not found
#> Error:
#> ! object 'pmm' not found
#> Error in `huber_loss_vec()`:
#> ! `estimate` should be a numeric vector, not NULL.
#> Error:
#> ! object 'bayes' not found
#> Error:
#> ! object 'pmm_huber' not found
#> Error:
#> ! object 'pmm' not found
#> Error in `msd_vec()`:
#> ! `estimate` should be a numeric vector, not NULL.
#> Error:
#> ! object 'bayes' not found
#> Error:
#> ! object 'pmm_msd' not found
#> Error:
#> ! object 'mi_eval' not found
#> Error:
#> ! object 'mi_eval' not found
#> Error:
#> ! object 'mi_eval' not found
#> Error:
#> ! object 'mi_eval' not foundWe can see that that the overall treatment effect is approximately 9.7-9.9, and for most of the principled methods we used to handle the missing data, we did not obtain similar estimates. For example, both the primary analysis and the controlled multiple imputation methods did not yield the correct treatment effect estimate in the adjusted model.
In fact, nearly all of the methods used except for the Heckman selection model, yielded overestimates of the treatment effect. Even though such analyses can be substantially improved with more specification and more information, the reality is that data that are assumed to be MNAR are difficult to handle and that no method can guarantee the correct answer. Indeed, we knew the missing data model / mechanism, via our custom function
Code
# Missing Data Mechanism
lesslikely <- function() {
set.seed(seed = 1031,
kind = "L'Ecuyer-CMRG",
normal.kind = "Inversion",
sample.kind = "Rejection"
)
logistic <- function(x) exp(x) / (1 + exp(x))
1 - rbinom(n, 1, logistic(errors[, 2]))
}
Ry <- ifelse(lesslikely() > 0, 1, 0)
PostDBP[Ry == 0] <- NA\[\begin{equation} \Pr(R_1=0)=\psi_0+\frac{e^{Y_1}}{1+e^{Y_1}}\psi_1 \end{equation}\]
for MNAR we set \(\psi_\mathrm{MNAR}=(0,1)\)
Thus, we obtain the following model:
\[\begin{align} \mathrm{MNAR}&:\mathrm{logit}(\Pr(R_1=0)) = Y_1 \ \end{align}\]
Even the random indicator method, which has shown much promise in simulation studies24 and offers the advantage of not having to specify a pattern-mixture or selection model could not recover the correct treatment effect estimate either, showing the difficulty of handling missing data and the limitations of automated approaches.
I hope it is clear from the examples above that it is quite easy to do any analyses with missing data and use a variety of ad-hoc approaches or even principled approaches to explore whether or not the results you’ve obtained are trustworthy or at least even give that impression, but doing a careful and principled one is quite difficult and requires much thought that will take into account real departures from assumptions and whether or not those will lead to substantial changes in results and conclusions/decisions.
Acknowledgements
I’d like to thank Dr. Tim Morris and Dr. Andrew Althouse for helpful comments on an earlier version of this piece. My acknowledgment of their help does not imply endorsement of my views by these colleagues or vice versa, and I remain solely responsible for the views expressed herein. All errors are my own. To point out such errors, please leave a comment below or use the contact form to get in touch.
Statistical Environments
R Environment
#> ─ Session info ─────────────────────────────────────────────────────────────────────────────────────────────────────────────────
#> setting value
#> version R version 4.6.1 (2026-06-24)
#> os macOS Tahoe 26.5.1
#> system aarch64, darwin25.4.0
#> ui unknown
#> language (EN)
#> collate en_US.UTF-8
#> ctype en_US.UTF-8
#> tz America/New_York
#> date 2026-06-26
#> pandoc 3.10 @ /opt/homebrew/bin/ (via rmarkdown)
#> quarto 1.9.38 @ /Applications/quarto/bin/quarto
#>
#> ─ Packages ─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
#> package * version date (UTC) lib source
#> abind 1.4-8 2024-09-12 [1] CRAN (R 4.6.0)
#> Amelia * 1.8.3 2024-11-08 [1] CRAN (R 4.6.0)
#> arm 1.15-3 2026-04-15 [1] CRAN (R 4.6.0)
#> arrayhelpers 1.1-0 2020-02-04 [1] CRAN (R 4.6.0)
#> backports 1.5.1 2026-04-03 [1] CRAN (R 4.6.0)
#> base * 4.6.1 2026-06-24 [2] local
#> base64enc 0.1-6 2026-02-02 [1] CRAN (R 4.6.0)
#> bayesplot * 1.15.0 2025-12-12 [1] CRAN (R 4.6.1)
#> bbotk 1.10.1 2026-06-13 [1] CRAN (R 4.6.0)
#> bitops 1.0-9 2024-10-03 [1] CRAN (R 4.6.0)
#> blogdown * 1.24 2026-06-19 [1] CRAN (R 4.6.1)
#> boot * 1.3-32 2025-08-29 [1] CRAN (R 4.6.1)
#> bootImpute * 1.3.0 2025-12-15 [1] CRAN (R 4.6.1)
#> bridgesampling 1.2-1 2025-11-19 [1] CRAN (R 4.6.0)
#> brms * 2.23.0 2025-09-09 [1] CRAN (R 4.6.1)
#> Brobdingnag 1.2-9 2022-10-19 [1] CRAN (R 4.6.0)
#> broom * 1.0.13 2026-05-14 [1] CRAN (R 4.6.0)
#> broom.mixed * 0.2.9.7 2026-02-17 [1] CRAN (R 4.6.0)
#> Cairo * 1.7-0 2025-10-29 [1] CRAN (R 4.6.1)
#> car * 3.1-5 2026-02-03 [1] CRAN (R 4.6.0)
#> carData * 3.0-6 2026-01-30 [1] CRAN (R 4.6.1)
#> cards 0.8.0 2026-05-28 [1] CRAN (R 4.6.0)
#> caTools 1.18.3 2024-09-04 [1] CRAN (R 4.6.0)
#> checkmate * 2.3.4 2026-02-03 [1] CRAN (R 4.6.0)
#> class 7.3-23 2025-01-01 [1] CRAN (R 4.6.0)
#> cli * 3.6.6 2026-04-09 [1] CRAN (R 4.6.1)
#> clipr 0.8.1 2026-05-25 [1] CRAN (R 4.6.0)
#> cluster 2.1.8.2 2026-02-05 [1] CRAN (R 4.6.0)
#> coda * 0.19-4.1 2024-01-31 [1] CRAN (R 4.6.1)
#> codetools 0.2-20 2024-03-31 [1] CRAN (R 4.6.0)
#> colorspace * 2.1-2 2025-09-22 [1] CRAN (R 4.6.0)
#> commonmark 2.0.0 2025-07-07 [1] CRAN (R 4.6.0)
#> compiler 4.6.1 2026-06-24 [2] local
#> concurve * 3.0.0 2026-06-23 [1] local
#> cowplot * 1.2.0 2025-07-07 [1] CRAN (R 4.6.1)
#> crayon 1.5.3 2024-06-20 [1] CRAN (R 4.6.0)
#> curl 7.1.0 2026-04-22 [1] CRAN (R 4.6.0)
#> data.table 1.18.4 2026-05-06 [1] CRAN (R 4.6.1)
#> datasets * 4.6.1 2026-06-24 [2] local
#> DBI 1.3.0 2026-02-25 [1] CRAN (R 4.6.1)
#> DEoptimR 1.2-0 2026-06-07 [1] CRAN (R 4.6.0)
#> desc 1.4.3 2023-12-10 [1] CRAN (R 4.6.0)
#> details 0.4.0 2025-02-09 [1] CRAN (R 4.6.0)
#> DiagrammeR 1.0.12 2026-04-27 [1] CRAN (R 4.6.0)
#> dichromat 2.0-0.1 2022-05-02 [1] CRAN (R 4.6.0)
#> digest 0.6.39 2025-11-19 [1] CRAN (R 4.6.0)
#> distributional 0.8.0 2026-06-23 [1] CRAN (R 4.6.0)
#> doParallel * 1.0.17 2022-02-07 [1] CRAN (R 4.6.1)
#> doRNG 1.8.6.3 2026-02-05 [1] CRAN (R 4.6.0)
#> dplyr * 1.2.1 2026-04-03 [1] CRAN (R 4.6.1)
#> e1071 1.7-17 2025-12-18 [1] CRAN (R 4.6.0)
#> emmeans 2.0.3 2026-04-09 [1] CRAN (R 4.6.0)
#> estimability 1.5.1 2024-05-12 [1] CRAN (R 4.6.0)
#> evaluate 1.0.5 2025-08-27 [1] CRAN (R 4.6.0)
#> extremevalues 2.4.1 2024-12-17 [1] CRAN (R 4.6.0)
#> farver 2.1.2 2024-05-13 [1] CRAN (R 4.6.0)
#> fastmap 1.2.0 2024-05-15 [1] CRAN (R 4.6.0)
#> forcats * 1.0.1 2025-09-25 [1] CRAN (R 4.6.0)
#> foreach * 1.5.2 2022-02-02 [1] CRAN (R 4.6.1)
#> foreign 0.8-91 2026-01-29 [1] CRAN (R 4.6.1)
#> formatR 1.14 2023-01-17 [1] CRAN (R 4.6.0)
#> Formula 1.2-5 2023-02-24 [1] CRAN (R 4.6.0)
#> fs 2.1.0 2026-04-18 [1] CRAN (R 4.6.1)
#> furrr 0.4.0 2026-03-31 [1] CRAN (R 4.6.0)
#> future * 1.70.0 2026-03-14 [1] CRAN (R 4.6.1)
#> future.apply * 1.20.2 2026-02-20 [1] CRAN (R 4.6.0)
#> gamlss * 5.5-0 2025-08-19 [1] CRAN (R 4.6.1)
#> gamlss.data * 6.0-7 2025-09-04 [1] CRAN (R 4.6.0)
#> gamlss.dist * 6.1-1 2023-08-23 [1] CRAN (R 4.6.0)
#> generics 0.1.4 2025-05-09 [1] CRAN (R 4.6.0)
#> ggcorrplot * 0.1.4.1 2023-09-05 [1] CRAN (R 4.6.0)
#> ggdist 3.3.3 2025-04-23 [1] CRAN (R 4.6.0)
#> ggplot2 * 4.0.3 2026-04-22 [1] CRAN (R 4.6.1)
#> ggtext * 0.1.2 2022-09-16 [1] CRAN (R 4.6.1)
#> glmnet 5.0 2026-05-04 [1] CRAN (R 4.6.1)
#> globals 0.19.1 2026-03-13 [1] CRAN (R 4.6.0)
#> glue 1.8.1 2026-04-17 [1] CRAN (R 4.6.1)
#> graphics * 4.6.1 2026-06-24 [2] local
#> grDevices * 4.6.1 2026-06-24 [2] local
#> grid * 4.6.1 2026-06-24 [2] local
#> gridExtra 2.3 2017-09-09 [1] CRAN (R 4.6.1)
#> gridtext 0.1.6 2026-02-19 [1] CRAN (R 4.6.0)
#> gt 1.3.0 2026-01-22 [1] CRAN (R 4.6.0)
#> gtable 0.3.6 2024-10-25 [1] CRAN (R 4.6.0)
#> gtsummary * 2.5.1 2026-05-30 [1] CRAN (R 4.6.0)
#> here * 1.0.2 2025-09-15 [1] CRAN (R 4.6.1)
#> Hmisc * 5.2-6 2026-06-19 [1] CRAN (R 4.6.1)
#> hms 1.1.4 2025-10-17 [1] CRAN (R 4.6.0)
#> htmlTable 2.5.0 2026-04-22 [1] CRAN (R 4.6.0)
#> htmltools * 0.5.9 2025-12-04 [1] CRAN (R 4.6.1)
#> htmlwidgets 1.6.4 2023-12-06 [1] CRAN (R 4.6.1)
#> httr 1.4.8 2026-02-13 [1] CRAN (R 4.6.0)
#> ImputeRobust * 1.3-1 2018-11-30 [1] CRAN (R 4.6.1)
#> inline 0.3.21 2025-01-09 [1] CRAN (R 4.6.0)
#> insight 1.5.1 2026-05-21 [1] CRAN (R 4.6.0)
#> iterators * 1.0.14 2022-02-05 [1] CRAN (R 4.6.0)
#> itertools 0.1-3 2014-03-12 [1] CRAN (R 4.6.0)
#> jomo 2.7-6 2023-04-15 [1] CRAN (R 4.6.0)
#> jsonlite 2.0.0 2025-03-27 [1] CRAN (R 4.6.1)
#> kableExtra * 1.4.0 2024-01-24 [1] CRAN (R 4.6.1)
#> knitr * 1.51 2025-12-20 [1] CRAN (R 4.6.1)
#> labeling 0.4.3 2023-08-29 [1] CRAN (R 4.6.0)
#> laeken 0.5.3 2024-01-25 [1] CRAN (R 4.6.0)
#> latex2exp * 0.9.8 2026-01-09 [1] CRAN (R 4.6.0)
#> lattice * 0.22-9 2026-02-09 [1] CRAN (R 4.6.1)
#> lgr 0.5.2 2026-01-30 [1] CRAN (R 4.6.0)
#> lifecycle 1.0.5 2026-01-08 [1] CRAN (R 4.6.0)
#> listenv 1.0.0 2026-06-22 [1] CRAN (R 4.6.0)
#> litedown 0.9 2025-12-18 [1] CRAN (R 4.6.0)
#> lme4 2.0-1 2026-03-05 [1] CRAN (R 4.6.1)
#> lmtest 0.9-40 2022-03-21 [1] CRAN (R 4.6.0)
#> loo * 2.9.0 2025-12-23 [1] CRAN (R 4.6.1)
#> lubridate * 1.9.5 2026-02-04 [1] CRAN (R 4.6.1)
#> magick 2.9.1 2026-02-28 [1] CRAN (R 4.6.1)
#> magrittr * 2.0.5 2026-04-04 [1] CRAN (R 4.6.1)
#> markdown 2.0 2025-03-23 [1] CRAN (R 4.6.0)
#> MASS * 7.3-65 2025-02-28 [1] CRAN (R 4.6.1)
#> Matrix * 1.7-5 2026-03-21 [1] CRAN (R 4.6.0)
#> MatrixModels 0.5-4 2025-03-26 [1] CRAN (R 4.6.0)
#> matrixStats 1.5.0 2025-01-07 [1] CRAN (R 4.6.0)
#> mcmc 0.9-8 2023-11-16 [1] CRAN (R 4.6.0)
#> MCMCpack * 1.7-1 2024-08-27 [1] CRAN (R 4.6.0)
#> methods * 4.6.1 2026-06-24 [2] local
#> mgcv * 1.9-4 2025-11-07 [1] CRAN (R 4.6.0)
#> mi * 1.2 2025-09-02 [1] CRAN (R 4.6.0)
#> mice * 3.19.0 2025-12-10 [1] CRAN (R 4.6.1)
#> miceadds * 3.20-10 2026-05-28 [1] CRAN (R 4.6.0)
#> miceFast * 0.9.1 2026-02-26 [1] CRAN (R 4.6.0)
#> minqa 1.2.8 2024-08-17 [1] CRAN (R 4.6.0)
#> missForest * 1.6.1 2025-10-26 [1] CRAN (R 4.6.0)
#> mitml * 0.4-5 2023-03-08 [1] CRAN (R 4.6.0)
#> mitools 2.4 2019-04-26 [1] CRAN (R 4.6.0)
#> mlr3 1.7.1 2026-06-11 [1] CRAN (R 4.6.0)
#> mlr3learners 0.15.0 2026-06-09 [1] CRAN (R 4.6.0)
#> mlr3misc 0.22.0 2026-06-10 [1] CRAN (R 4.6.0)
#> mlr3pipelines 0.11.0 2026-03-01 [1] CRAN (R 4.6.0)
#> mlr3tuning 1.6.0 2026-03-16 [1] CRAN (R 4.6.0)
#> moocore 0.3.1 2026-05-04 [1] CRAN (R 4.6.0)
#> multcomp 1.4-30 2026-03-09 [1] CRAN (R 4.6.0)
#> mvtnorm * 1.4-1 2026-06-06 [1] CRAN (R 4.6.1)
#> nlme * 3.1-169 2026-03-27 [1] CRAN (R 4.6.1)
#> nloptr 2.2.1 2025-03-17 [1] CRAN (R 4.6.0)
#> nnet 7.3-20 2025-01-01 [1] CRAN (R 4.6.0)
#> opdisDownsampling 1.6 2026-06-25 [1] CRAN (R 4.6.1)
#> otel 0.2.0 2025-08-29 [1] CRAN (R 4.6.0)
#> palmerpenguins 0.1.1 2022-08-15 [1] CRAN (R 4.6.0)
#> pan 1.9 2023-12-07 [1] CRAN (R 4.6.0)
#> paradox 1.0.1 2024-07-09 [1] CRAN (R 4.6.0)
#> parallel * 4.6.1 2026-06-24 [2] local
#> parallelly * 1.47.0 2026-04-17 [1] CRAN (R 4.6.0)
#> pbmcapply * 1.5.1 2022-04-28 [1] CRAN (R 4.6.0)
#> performance * 0.17.0 2026-05-21 [1] CRAN (R 4.6.0)
#> pillar 1.11.1 2025-09-17 [1] CRAN (R 4.6.0)
#> pkgbuild 1.4.8 2025-05-26 [1] CRAN (R 4.6.1)
#> pkgconfig 2.0.3 2019-09-22 [1] CRAN (R 4.6.0)
#> plyr 1.8.9 2023-10-02 [1] CRAN (R 4.6.1)
#> png 0.1-9 2026-03-15 [1] CRAN (R 4.6.0)
#> polspline 1.1.25 2024-05-10 [1] CRAN (R 4.6.0)
#> posterior * 1.7.0 2026-04-01 [1] CRAN (R 4.6.0)
#> pracma 2.4.6 2025-10-22 [1] CRAN (R 4.6.0)
#> prettyunits 1.2.0 2023-09-24 [1] CRAN (R 4.6.0)
#> ProfileLikelihood * 1.3 2023-08-25 [1] CRAN (R 4.6.1)
#> progress * 1.2.3 2023-12-06 [1] CRAN (R 4.6.0)
#> proxy 0.4-29 2025-12-29 [1] CRAN (R 4.6.0)
#> purrr * 1.2.2 2026-04-10 [1] CRAN (R 4.6.1)
#> qqconf 1.3.2 2023-04-14 [1] CRAN (R 4.6.0)
#> qqplotr * 0.0.7 2025-09-05 [1] CRAN (R 4.6.0)
#> quantreg * 6.1 2025-03-10 [1] CRAN (R 4.6.1)
#> QuickJSR 1.10.0 2026-05-17 [1] CRAN (R 4.6.0)
#> R6 2.6.1 2025-02-15 [1] CRAN (R 4.6.1)
#> randomForest * 4.7-1.2 2024-09-22 [1] CRAN (R 4.6.0)
#> ranger 0.18.0 2026-01-16 [1] CRAN (R 4.6.0)
#> rbibutils 2.4.1 2026-01-21 [1] CRAN (R 4.6.0)
#> rcartocolor 2.1.2 2025-07-23 [1] CRAN (R 4.6.0)
#> RColorBrewer 1.1-3 2022-04-03 [1] CRAN (R 4.6.1)
#> Rcpp * 1.1.1-1.1 2026-04-24 [1] CRAN (R 4.6.1)
#> RcppParallel 5.1.11-2 2026-03-05 [1] CRAN (R 4.6.0)
#> Rdpack 2.6.6 2026-02-08 [1] CRAN (R 4.6.0)
#> readr * 2.2.0 2026-02-19 [1] CRAN (R 4.6.1)
#> reformulas 0.4.4 2026-02-02 [1] CRAN (R 4.6.0)
#> rematch2 2.1.2 2020-05-01 [1] CRAN (R 4.6.0)
#> reshape2 * 1.4.5 2025-11-12 [1] CRAN (R 4.6.1)
#> reticulate * 1.46.0 2026-04-09 [1] CRAN (R 4.6.1)
#> rlang 1.2.0 2026-04-06 [1] CRAN (R 4.6.1)
#> rmarkdown * 2.31 2026-03-26 [1] CRAN (R 4.6.1)
#> rms * 8.1-1 2026-02-18 [1] CRAN (R 4.6.1)
#> rngtools 1.5.2 2021-09-20 [1] CRAN (R 4.6.0)
#> robustbase 0.99-7 2026-02-05 [1] CRAN (R 4.6.0)
#> rpart 4.1.27 2026-03-27 [1] CRAN (R 4.6.0)
#> rprojroot 2.1.1 2025-08-26 [1] CRAN (R 4.6.0)
#> rstan * 2.32.7 2025-03-10 [1] CRAN (R 4.6.1)
#> rstantools 2.6.0 2026-01-10 [1] CRAN (R 4.6.1)
#> rstudioapi 0.19.0 2026-06-11 [1] CRAN (R 4.6.1)
#> S7 0.2.2 2026-04-22 [1] CRAN (R 4.6.0)
#> sandwich 3.1-1 2024-09-15 [1] CRAN (R 4.6.1)
#> sass 0.4.10 2025-04-11 [1] CRAN (R 4.6.0)
#> scales 1.4.0 2025-04-24 [1] CRAN (R 4.6.1)
#> sessioninfo 1.2.4 2026-06-04 [1] CRAN (R 4.6.0)
#> shape 1.4.6.1 2024-02-23 [1] CRAN (R 4.6.0)
#> showtext * 0.9-8 2026-03-21 [1] CRAN (R 4.6.1)
#> showtextdb * 3.0 2020-06-04 [1] CRAN (R 4.6.0)
#> sp 2.2-1 2026-02-13 [1] CRAN (R 4.6.0)
#> SparseM * 1.84-2 2024-07-17 [1] CRAN (R 4.6.0)
#> splines * 4.6.1 2026-06-24 [2] local
#> StanHeaders * 2.32.10 2024-07-15 [1] CRAN (R 4.6.1)
#> Statamarkdown * 0.9.6 2025-10-07 [1] CRAN (R 4.6.1)
#> stats * 4.6.1 2026-06-24 [2] local
#> stats4 * 4.6.1 2026-06-24 [2] local
#> stringi 1.8.7 2025-03-27 [1] CRAN (R 4.6.1)
#> stringr * 1.6.0 2025-11-04 [1] CRAN (R 4.6.1)
#> survival 3.8-6 2026-01-16 [1] CRAN (R 4.6.1)
#> svglite * 2.2.2 2025-10-21 [1] CRAN (R 4.6.1)
#> svgPanZoom 0.3.4 2020-02-15 [1] CRAN (R 4.6.0)
#> svUnit 1.0.8 2025-08-26 [1] CRAN (R 4.6.0)
#> sysfonts * 0.8.9 2024-03-02 [1] CRAN (R 4.6.1)
#> systemfonts 1.3.2 2026-03-05 [1] CRAN (R 4.6.1)
#> tensorA 0.36.2.1 2023-12-13 [1] CRAN (R 4.6.0)
#> texPreview * 2.1.0 2024-01-24 [1] CRAN (R 4.6.0)
#> textshaping 1.0.5 2026-03-06 [1] CRAN (R 4.6.0)
#> TH.data 1.1-5 2025-11-17 [1] CRAN (R 4.6.0)
#> tibble * 3.3.1 2026-01-11 [1] CRAN (R 4.6.1)
#> tidybayes * 3.0.7 2024-09-15 [1] CRAN (R 4.6.0)
#> tidyr * 1.3.2 2025-12-19 [1] CRAN (R 4.6.1)
#> tidyselect 1.2.1 2024-03-11 [1] CRAN (R 4.6.0)
#> tidyverse * 2.0.0 2023-02-22 [1] CRAN (R 4.6.1)
#> timechange 0.4.0 2026-01-29 [1] CRAN (R 4.6.0)
#> tinytex * 0.60 2026-06-16 [1] CRAN (R 4.6.1)
#> tools 4.6.1 2026-06-24 [2] local
#> twosamples 2.0.1 2023-06-23 [1] CRAN (R 4.6.0)
#> tzdb 0.5.0 2025-03-15 [1] CRAN (R 4.6.0)
#> utils * 4.6.1 2026-06-24 [2] local
#> uuid 1.2-2 2026-01-23 [1] CRAN (R 4.6.0)
#> V8 8.2.0 2026-04-21 [1] CRAN (R 4.6.0)
#> vcd 1.4-13 2024-09-16 [1] CRAN (R 4.6.0)
#> vctrs 0.7.3 2026-04-11 [1] CRAN (R 4.6.0)
#> VIM * 7.0.0 2026-01-10 [1] CRAN (R 4.6.0)
#> viridisLite 0.4.3 2026-02-04 [1] CRAN (R 4.6.0)
#> visNetwork 2.1.4 2025-09-04 [1] CRAN (R 4.6.0)
#> wesanderson * 0.3.7 2023-10-31 [1] CRAN (R 4.6.0)
#> whisker 0.4.1 2022-12-05 [1] CRAN (R 4.6.1)
#> withr 3.0.3 2026-06-19 [1] CRAN (R 4.6.1)
#> xfun * 0.59 2026-06-19 [1] CRAN (R 4.6.1)
#> xml2 1.6.0 2026-06-22 [1] CRAN (R 4.6.1)
#> xtable * 1.8-8 2026-02-22 [1] CRAN (R 4.6.1)
#> yaml 2.3.12 2025-12-10 [1] CRAN (R 4.6.1)
#> yardstick * 1.4.0 2026-04-07 [1] CRAN (R 4.6.1)
#> zoo 1.8-15 2025-12-15 [1] CRAN (R 4.6.0)
#>
#> [1] /opt/homebrew/lib/R/4.6/site-library
#> [2] /opt/homebrew/Cellar/r/4.6.1/lib/R/library
#> * ── Packages attached to the search path.
#>
#> ─ External software ────────────────────────────────────────────────────────────────────────────────────────────────────────────
#> setting value
#> cairo 1.18.4
#> cairoFT 2.14.3/2.18.1
#> pango
#> png
#> jpeg
#> tiff
#> tcl 9.0
#> curl 8.7.1
#> zlib 1.2.12
#> bzlib 1.0.8, 13-Jul-2019
#> xz 5.8.3
#> deflate
#> zstd 1.5.7
#> PCRE 10.47 2025-10-21
#> ICU 78.1
#> TRE TRE 0.8.0 R_fixes (BSD)
#> iconv Apple or GNU libiconv 1.11 /usr/lib/libiconv.2.dylib
#> readline 8.3
#> BLAS /opt/homebrew/Cellar/openblas/0.3.33/lib/libopenblasp-r0.3.33.dylib
#> lapack /opt/homebrew/Cellar/r/4.6.1/lib/R/lib/libRlapack.dylib
#> lapack_version 3.12.1
#>
#> ────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
#> $RNGkind
#> [1] "L'Ecuyer-CMRG" "Inversion" "Rejection"Stata Environment
Code
set linesize 255
display %tcMonth_dd,CCYY_hh:MM_am now()
about
#> Can not set Stata directory, try using -statapath(
#> > )- option
#> r(601);
#>
#>
#>
#> June 26,2026 1:22 pm
#>
#>
#> StataNow/MP 19.5 for Mac (Apple Silicon)
#> Revision 03 Jun 2026
#> Copyright 1985-2025 StataCorp LLC
#>
#> Total physical memory: 48.01 GB
#>
#> Stata license: Single-user 2-core , expiring 6 Feb 2027
#> Serial number: 501909358563
#> Licensed to: Zad Rafi
#> HunterReferences
References
1. Stark PB, Saltelli A. (2018). “Cargo-cult statistics and scientific crisis.” Significance. 15:40–43. doi: 10.1111/j.1740-9713.2018.01174.x.
2. Gigerenzer G. (2018). “Statistical Rituals: The Replication Delusion and How We Got There.” Advances in Methods and Practices in Psychological Science. 1:198–218. doi: 10.1177/2515245918771329.
3. Greenland S. (2017). “Invited commentary: The need for cognitive science in methodology.” American Journal of Epidemiology. 186:639–645. doi: 10.1093/aje/kwx259.
4. Greenland S. (2005). “Multiple-bias modelling for analysis of observational data.” Journal of the Royal Statistical Society Series A (Statistics in Society). 168:267–306. doi: 10.1111/j.1467-985X.2004.00349.x.
5. Greenland S, Lash TL. (2008). “Bias analysis.” In: Rothman KJ, Greenland S, Lash TL, editors. Modern Epidemiology. 3rd edition. Lippincott Williams & Wilkins. p. 345–380.
6. Lash TL, Fox MP, Fink AK. (2009). “Applying Quantitative Bias Analysis to Epidemiologic Data.” Springer New York.
7. Lash TL, Fox MP, MacLehose RF, Maldonado G, McCandless LC, Greenland S. (2014). “Good practices for quantitative bias analysis.” International Journal of Epidemiology. 43:1969–1985. doi: 10.1093/ije/dyu149.
8. Lash TL, Ahern TP, Collin LJ, Fox MP, MacLehose RF. (2021). “Bias Analysis Gone Bad.” American Journal of Epidemiology. doi: 10.1093/aje/kwab072.
9. Gustafson P. (2021). “Invited Commentary: Toward Better Bias Analysis.” American Journal of Epidemiology. doi: 10.1093/aje/kwab068.
10. Greenland S. (2021). “Dealing with the Inevitable Deficiencies of Bias Analysis and All Analyses.” American Journal of Epidemiology. doi: 10.1093/aje/kwab069.
11. Molenberghs G, Fitzmaurice G, Kenward MG, Tsiatis A, Verbeke G. (2014). “Handbook of Missing Data Methodology.” CRC Press.
12. Scott RaP. (2002). “The Multicentre Aneurysm Screening Study (MASS) into the effect of abdominal aortic aneurysm screening on mortality in men: A randomised controlled trial.” The Lancet. 360:1531–1539. doi: 10.1016/S0140-6736(02)11522-4.
13. Morris TP, Kahan BC, White IR. (2014). “Choosing sensitivity analyses for randomised trials: principles.” BMC Medical Research Methodology. 14:11. doi: 10.1186/1471-2288-14-11.
14. Mosteller F, Tukey JW. (1987). “Data analysis including statistics.” In: The Collected Works of John W. Tukey: Philosophy and Principles of Data Analysis 1965-1986. CRC Press.
15. Akacha M, Bretz F, Ohlssen D, Rosenkranz G, Schmidli H. (2017). “Estimands and Their Role in Clinical Trials.” Statistics in Biopharmaceutical Research. 9:268–271. doi: 10.1080/19466315.2017.1302358.
16. Permutt T. (2020). “Do Covariates Change the Estimand?” Statistics in Biopharmaceutical Research. 12:45–53. doi: 10.1080/19466315.2019.1647874.
17. Mitroiu M, Oude Rengerink K, Teerenstra S, Pétavy F, Roes KCB. (2020). “A narrative review of estimands in drug development and regulatory evaluation: Old wine in new barrels?” Trials. 21:671. doi: 10.1186/s13063-020-04546-1.
18. Little RJ, D’Agostino R, Cohen ML, Dickersin K, Emerson SS, Farrar JT, et al. (2012). “The Prevention and Treatment of Missing Data in Clinical Trials.” New England Journal of Medicine. 367:1355–1360. doi: 10.1056/NEJMsr1203730.
19. Chen D-G(Din), Peace KE, Zhang P. (2017). “Clinical trial data analysis using r and SAS.” 2nd edition. Chapman; Hall/CRC. doi: 10.1201/9781315155104.
20. Buuren S van. (2018). “Flexible Imputation of Missing Data, Second Edition.” CRC Press.
21. Meng X-L, Rubin DB. (1992). “Performing Likelihood Ratio Tests with Multiply-Imputed Data Sets.” Biometrika. 79:103–111. doi: 10.2307/2337151.
22. Schenker N, Taylor J. (1996). “Partially parametric techniques for multiple imputation.” Computational Statistics & Data Analysis. 22:425–446. doi: 10.1016/0167-9473(95)00057-7.
23. Permutt T. (2016). “Sensitivity analysis for missing data in regulatory submissions.” Statistics in Medicine. 35:2876–2879. doi: 10.1002/sim.6753.
24. Jolani S. (2012). “Dual Imputation Strategies for Analyzing Incomplete Data.”
25. von Hippel PT, Bartlett J. (2019). “Maximum likelihood multiple imputation: Faster imputations and consistent standard errors without posterior draws.” arXiv:12100870 [stat]. https://arxiv.org/abs/1210.0870.
26. Rafi Z, Greenland S. (2020). “Semantic and cognitive tools to aid statistical science: Replace confidence and significance by compatibility and surprise.” BMC Medical Research Methodology. 20:244. doi: 10.1186/s12874-020-01105-9.
27. Greenland S, Rafi Z. (2020). “To Aid Scientific Inference, Emphasize Unconditional Descriptions of Statistics.” arXiv:190908583 [statME]. https://arxiv.org/abs/1909.08583.
Citation
For attribution, please cite this work as:
1. Rafi Z, Panda S. (2020). ‘What Makes a Sensitivity
Analysis?’ https://lesslikely.com/statistics/sensitivity.html.
Backlinks (11)
- Blog
- All Posts
- Site Map
- Tables, Graphs, and Computations from Rafi & Greenland (2020)
- Your Models Are Neither Useful Nor Approximate
- Vitamin E, Mortality, and the Bayesian Gloss
- Confidence, Posteriors, and the Bootstrap
- When Can We Say That Something Doesn’t Work?
- Statistics
- Problems with the Number Needed to Treat
- Quality Control in Statistical Analyses
Comments