When Can We Say That Something Doesn’t Work?

effect sizes, evidence of absence, find a statistically significant, null hypothesis significance testing, statistically significant
People don’t want to waste their time on things that don’t work. To avoid wasting time, many may want to assess the scientific evidence. They may first look at the basic science (if it can be studied at such a level) and ask, “does this thing have a clear molecular/biological mechanism,” or they may ask, “does it have a theoretical foundation?”

Next, the person may look at the human evidence (if there is any) and ask if it worked in a clinical trial or epidemiological data.
Now, suppose there is no human evidence, and we only have mechanistic data. Then we have a situation we may describe as “absence of evidence.” The thing we’re interested in hasn’t been studied at the human level. So, we can’t be sure whether it works or not.

You often hear people say, “there is no evidence that xx works for yy outcome.” It’s obviously true, and the person saying that may wish to guide you towards something that has been studied and shown to work, and away from something that could be a waste of your time and money.
Alas, too many people get carried away and confuse absence of evidence (we don’t know if X works) with evidence of absence (we know X doesn’t work)
Hypothesis Testing
Let’s imagine that a new weight loss supplement has been studied in humans. It’s a randomized controlled trial with a pretty small sample, say 40 participants, and it’s about 12 months long. So 20 people get the weight loss supplement, and 20 people get the placebo. They don’t know which one they got. At the end of the 12-month study, the authors conclude the following, “there is no difference between the weight loss group and the placebo group.”

Is it possible that both groups had the same average weight loss? No, of course not. Even if they were both taking placebos, we’d see some differences because of random error and natural fluctuations.
So how did the authors conclude there was no difference between groups? They ran a statistical inferential test to see whether there was a “statistically significant difference” between the groups. They didn’t find one, so they wrote, “there is no difference between the weight loss group and the placebo group.”
Someone may point to this study and say, “hey, look, the weight loss supplement was compared to placebo in a clinical trial and there was no difference. It doesn’t work.” I mean, it’s been studied in humans so that must be evidence of absence…right?
Wrong.
“What?” you say. “Okay, let’s repeat this study 10 times.Nearly all of the replications are nonsignificant. Surely now we have evidence of absence.”
“No. Doing the study several times doesn’t necessarily give you evidence of absence and you’re also arguing with a method called vote counting,” I reply.
“I hate you,” you respond.
The problem with the sort of design used above is that it uses a method called null hypothesis significance testing. It’s a long phrase but think about it like this: imagine we have a thought experiment where we assume no difference between the weight-loss-supplement group and placebo group. We’re assuming that all weight-loss differences that we do happen to see are merely a result of random error. Remember, this is a thought experiment, not the truth.1, 2
We run our study, and then whoa, suddenly we see some substantial differences in weight loss between the supplement group and the placebo group. Therefore, our data (the large difference in weight loss between groups) are not very compatible with our thought experiment (the idea of no difference between groups). So, what do we do in this case? We reject our thought experiment and accept a better thought experiment that is more compatible with our data (a thought experiment where we assume a difference between the supplement group and placebo group).
Of course, the thought experiments are the actual statistical hypotheses that are being tested. The null hypothesis is our thought experiment where we assume no difference. In clinical trials, if we’re starting from this position (this thought experiment of no difference, amongst other assumptions), we can only reject it, or fail to reject it. We can’t accept it.
Why? blame the guy below

Because there may be other alternative hypotheses that are true, and our study may not have enough “power” to reject the thought experiment.
Think of power in terms of a microscope. Imagine you can see bacteria, but you can’t see viruses, because your instrument isn’t advanced enough to detect them. Does this mean you have evidence that viruses don’t exist? What if you looked 10 more times using the same microscope or a weaker microscope? Do you now have evidence that viruses don’t exist?

No, of course not. That’s absurd. Contrary to what many people assume, if do not find a statistically significant difference or statistically significant effect, it does not mean something doesn’t have an effect. Replicating the study several times, finding no significant differences in most studies, and concluding there’s no effect… is fallacious because most of the studies may have lacked the sensitivity (statistical power) to detect an effect. This is why groups like Cochrane discourage this method of critical appraisal, commonly known as vote counting.
Again, if all the studies are using weak microscopes, replicating the study several times won’t change the fact that they lack the sensitivity to see viruses (a significant effect). We can only suspend our judgment when we fail to reject the null. It is not evidence of absence.
Even in an ideal world, a statistically significant effect does not mean that the difference is meaningful (perhaps it’s a tiny, meaningless difference you found because of your extremely large study/powerful microscope, so now you see specks of dust smaller than viruses that you think are viruses, but aren’t), it doesn’t necessarily mean that there’s an effect (perhaps another assumption of your thought experiment was violated). Furthermore, categorizing results as being statistically significant or not statistically significant is simply dichotomous thinking and throws away much of the information from the study.
Okay, so you can’t claim evidence of absence with a study that failed to find a statistically significant difference. Then how do you get support for absence of an effect?!
Equivalence Testing
Well, in hypothesis testing, you can use something called equivalence testing.3–5
It’s basically the opposite of null hypothesis significance testing because you’ve reversed the burden of proof. Now you start with a thought experiment in which you assume significant differences between the supplement group and the placebo group.
You set up a region of differences that are close to zero and not meaningful (white area in the image below). If the differences you observe do not surpass this region, meaning they are very close to zero, then the data are incompatible with your thought experiment, in which you assumed there was significant differences between the groups.
So, you reject the thought experiment that there are differences between the groups and accept the hypothesis that there are no differences between groups. But if the differences end up being substantially large and fall within the pink area, you’ve failed to reject the alternative hypothesis (the thought experiment you started out with). Again, the opposite of testing the null hypothesis.


Before you could only reject the null hypothesis and accept the alternative.
Now in equivalence testing, you can only reject the alternative (what you started with) and accept the null hypothesis.
Now, you can say you have support for absence of meaningful effects.
Even though equivalence testing is the correct way to accept the null hypothesis, it is not a method that is used widely (at least in fields outside psychology and pharmaceutical research). And it’s a method used specifically within the context of testing statistical hypotheses thus, it too can suffer from issues of low power and may miss violations from the test hypothesis!Statistical hypothesis testing in a frequentist framework (long-term frequencies) can be useful in areas where we’d like to guide our behavior in the long run.
Bayesian Hypothesis Testing
There is also a Bayesian counterpart to hypothesis testing that utilizes Bayes factors. The Bayes factor is a ratio of the posterior odds to the prior odds. Therefore, it’s a measure of change from the prior odds to the posterior odds. In this framework, we are allowed to accept the null hypothesis or the alternative hypothesis depending on the calculated BF. Kruschke, 2017 discusses how Bayes factors are commonly interpreted,
A common decision rule for Bayesian null-hypothesis testing is based on the Bayes factor (not on the posterior probabilities). According to this decision procedure, the Bayes factor is compared against a decision threshold, such as 10. When BF(null) >10, the null hypothesis is accepted relative to the particular alternative hypothesis under consideration, and when BF(null) <1/10, the null hypothesis is rejected relative to the particular alternative hypothesis under consideration.
The choice of decision threshold is set by practical considerations. A Bayes factor between 3 and 10 is supposed to indicate “moderate” or “substantial” evidence for the winning model, while a Bayes factor between 10 and 30 indicates “strong” evidence, and a Bayes factor greater than 30 indicates “very strong” evidence (Jeffreys, 1961; Kass & Raftery, 1995; Wetzels et al., 2011).
Dienes (2016) suggested a Bayes factor of 3 for substantial evidence, while Schönbrodt et al. (2016) recommended the decision threshold for a Bayes factor be set at 6 for incipient stages of research but set at a higher threshold of 10 for mature confirmatory research (in the specific context of a null hypothesis test for the means of two groups, implying that the decision threshold might be different for different sorts of analyses).
To many, this may seem like a solution to the problems with null hypothesis significance testing and equivalence testing. However, utilizing Bayes factors also relies heavily on choosing priors that make sense. This is no trivial task as Bayes factors are sensitive to the prior distribution that is chosen for the alternative hypothesis. Unfortunately, the use of Bayes factors with “default priors” that are built into statistical programs has risen drastically.
They are incredibly easy to calculate, but also give weight to unrealistic effect sizes and can distort decisions. The use of default priors to calculate Bayes factors is as mindless as utilizing null hypothesis significance testing without much consideration for false positives and false negatives. It is simply another example of cargo-cult statistics and should be discouraged. Furthermore, Bayes factors are not without their own problems.
This summarizes much of what is available to researchers to properly accept the null hypothesis. But again, this is all within the context of testing statistical hypothesis. In certain areas of science, there is little justification for testing statistical hypotheses and thinking in terms of dichotomies, because the researchers may be more interested in the magnitude of the effect rather than in making decisions. For example, a study may be conducted for the sake of acquiring more information, but not shaping policy, which may be the aim of large research syntheses. This can also apply to research that is exploratory and in which there is no random mechanism.
In those scenarios, the primary focus may be on estimation.
Interval Estimates
If you have a very large and precise study where the interval estimates – like a compatibility (confidence) interval) – are very tight and clustered around effects that are not meaningful, then you can say you have support for absence of meaningful effects. Every value within the interval is compatible with the test model and its assumptions, while those outside of the interval are incompatible.
We also need to be cautious with interval estimates because they are often misinterpreted as containing the true population parameter. For example, many believe that a 95% confidence/compatibility interval has a high probability (95%) of containing the true parameter, however, this probability (95%) is a long-run frequency, meaning that 95% of confidence intervals in the long run will contain the population parameter. Here is an excellent interactive graphic to see this in action. The probability of the interval from the data containing the population parameter is either 0% or 100%, not 95%. It either contains it or it does not.
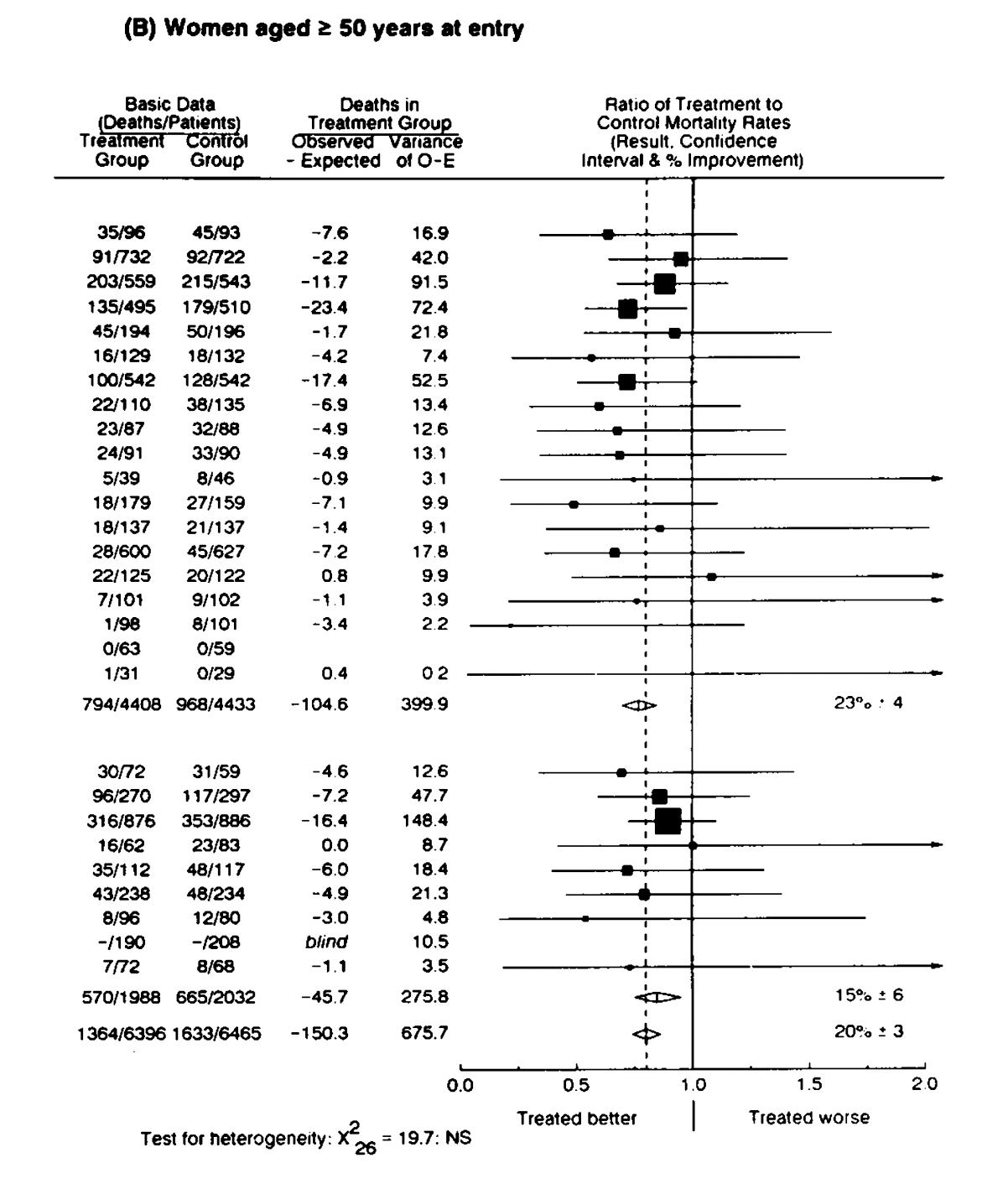
The image above represents a good example to work with. The intervals above in this forest plot came from 28 studies that investigated the effects of tamoxifen on mortality in women with breast cancer. Nearly all of the trials are nonsignificant (the intervals include the null value). However, they are all clearly small studies with far too much imprecision, as indicated by the width of the intervals.
Thus, when they are all pooled in a meta-analysis (diamond all the way at the bottom), we can see a very narrow compatibility interval that is clearly statistically significant and includes a small range of values that are compatible with the test model, and that clearly indicate an effect.
Any person who assesses the statistical significance of an individual trial out of these 28 studies or engages in vote counting to assess the overall body of literature (27 nonsignificant out of 28 studies) would be fooled into thinking that there was no effect, when in reality, each study suffered from far too much random error to be useful. This is a good example of why looking to see whether an interval contains the null or whether the study is significant or not, is not very useful.

Here’s another example where we can see this, taken from Modern Epidemiology.6
Look at the really wide interval function (the wide pyramid). The data from one study produced it. Look at what effect sizes it covers. Because it includes a rate ratio of 1 (which means the same rate of events between two groups), it’s considered nonsignificant. If someone saw this, they may try to argue that it’s evidence for no effect because it’s not statistically significant. However, the reality is that the study suffers from so much imprecision that we can hardly conclude anything from it. This is absence of evidence.
You may have also noticed the really skinny, narrow interval function slightly to the right of 1. That data was produced from another study and because it doesn’t include a rate ratio of 1 for many of the intervals at various confidence levels, it would be considered “statistically significant.” Yet, most of the intervals (the vast majority of the function) include rate ratios only slightly above 1.
So what this interval is telling us is that there’s a lot of precision here, which is why the interval function is so narrow, and that most of the effect sizes, that are compatible with our thought experiment (the test model/hypothesis), are not very large. This could be interpreted as support for absence of meaningful effects because most of the effect sizes are incredibly small and there’s a good deal of precision here.
Bayesian Intervals
The Bayesian counterpart to this would be to set a region of practical equivalence (ROPE) around the null (similar to equivalence testing) and see whether the calculated 95% highest density posterior interval (HDPI)(also referred to as 95% credible intervals) is inside the ROPE. If the entire interval is within the ROPE, then we accept the null value that the ROPE is based on. If the entire interval is outside the ROPE, then we can reject the null value. Otherwise, we may wish to remain undecided.
Unlike the confidence/compatibility interval, the HDPI actually contains the 95% most probable values and the spread of the posterior is a measure of uncertainty. Thus, any value inside the interval is more probable than those outside of it.
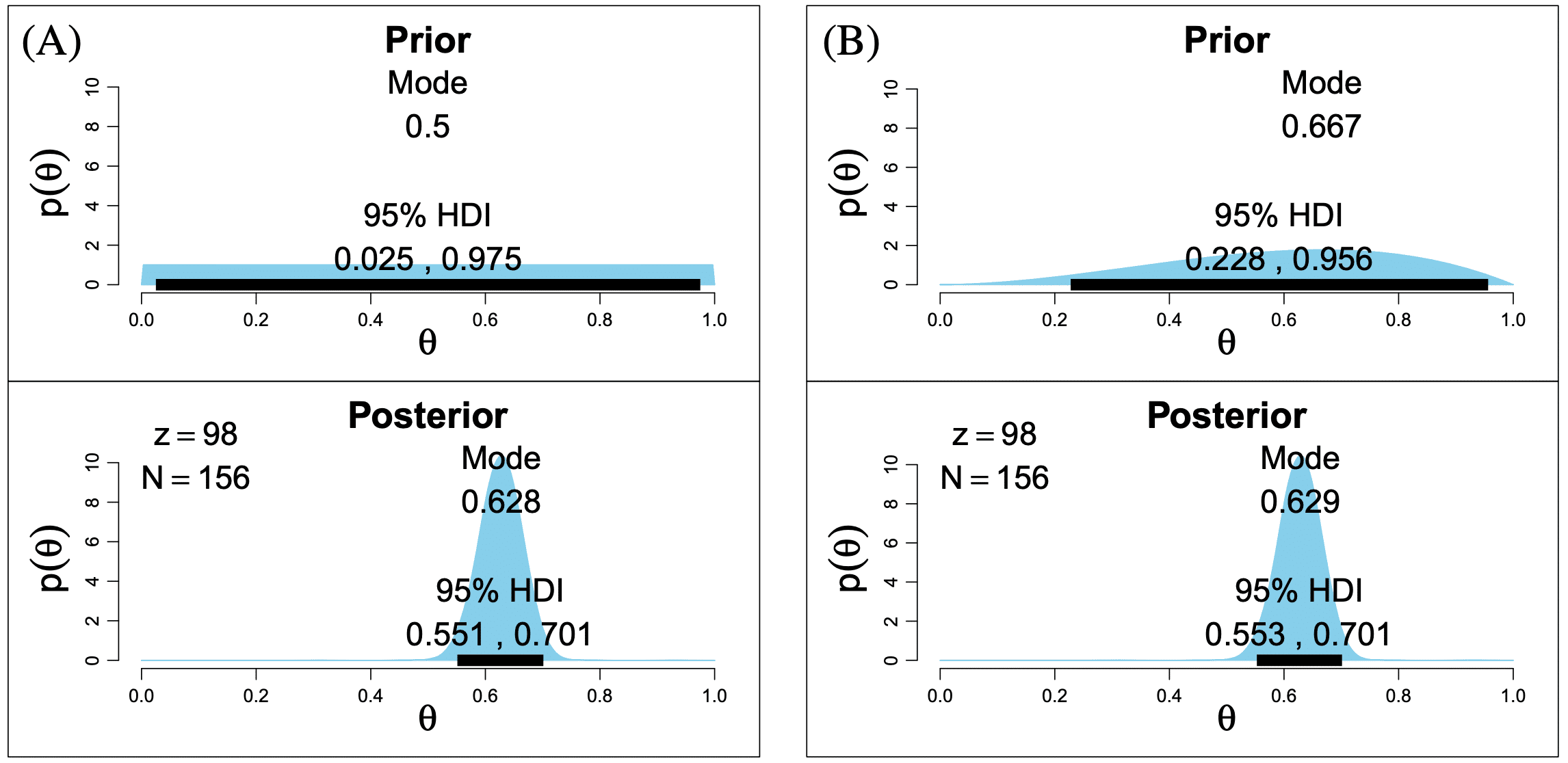
Like all Bayesian procedures, this too requires specifying a prior distribution about probable values of a parameter θ, thus very strong priors can overwhelm the likelihood function (the observed data), especially when there are few data, and transfer into the posterior distribution, which is what the 95% HDPI is taken from.
This can be seen in the image above, where a “diffuse” prior (left) has little effect on the posterior distribution and the slightly informed prior (right) also has little (but somewhat more) influence on the mode. This is because there is a fairly large amount of data here, which would need a very strong prior to be notably influenced.
As a rule, always look to the interval estimates in addition to statistical tests to see what effect sizes are compatible with the test model and remember: absence of evidence is NOT evidence of absence. Every scientific study is an attempt to collect data and analyze it. This does not mean that we must always make a decision and come to a conclusion.
****The fifth paper being cited has some mistakes in it with regard to interpreting interval estimates and power. It incorrectly assumes that a 95% interval has a 95% probability of containing the population parameter, when in reality, this is a long-term frequentist probability (if you repeated the study an infinite number of times, 95% of the intervals from those studies would contain the true population parameter).
Quertemont: “Table 1 shows that the 95% confidence interval for the difference between the control and experimental groups is –6.55 to 119.51 ms for example.Therefore, we are 95% confident that the true difference between the groups at the population level is between –6.55 ms (the mean reaction time of the experimental group is about 7 ms below that of the control group) and 119.51 ms (the mean reaction time of the experimental group is about 120 ms above that of the control group).”
It also incorrectly describes statistical power, which I’ve discussed at length here.
Quertemont: “The same power analysis for the second example returns a value of .8727, meaning that a priori our study was expected to return a significant test result in 87.3% of the cases if the difference between the groups was 15 ms and the sample sizes were 150. Finding a null result in this situation is much more informative about the likely effect size at the population level. Since the study led to non-significant results, we can reasonably conclude that the true population difference is below 15 ms, a difference we would interpret as negligible and not relevant for practical purposes.”
See also: What Makes a Sensitivity Analysis? — the hub piece tying this material to the broader cluster on assumptions, robustness, and what happens when models bend.
Comments